
【留出法】
留出法,是一种对机器学习泛化误差能力进行评估的一种方法。具体做法是在样本数据集的基础之上进行合理划分,即训练集和测试集,一部分用来训练模型(训练集),一部分用来评估模型的泛化能力(测试集)。
- 注意点:训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响。即测试集和训练集中的正例、反例要尽量保持原样本数据中的比例。
- 由于单次使用留出法得到的评估结果往往不够稳定可靠,在使用留出法时,一般要采用若干次随机划分、重复进行试验评估后取平均值作为留出法的评估结果。
训练集和测试集的比例划分,一般常见的做法是大约~的样本用于训练,剩余的样本用于测试。
此部分内容是为剪枝做补充的内容
【决策树】
决策树是一种常见的机器学习算法,既可以做分类也可以做回归(回归此章节暂不涉及)。决策树的执行过程是将数据从根节点一步一步的划分到各个叶子节点(决策的过程)。决策树包括以下组成成分:
- 根节点
- 飞叶子节点与分支
- 叶子节点(最终的决策结果)
借助周志华教授机器学习一书中的案例,图例如下所示:
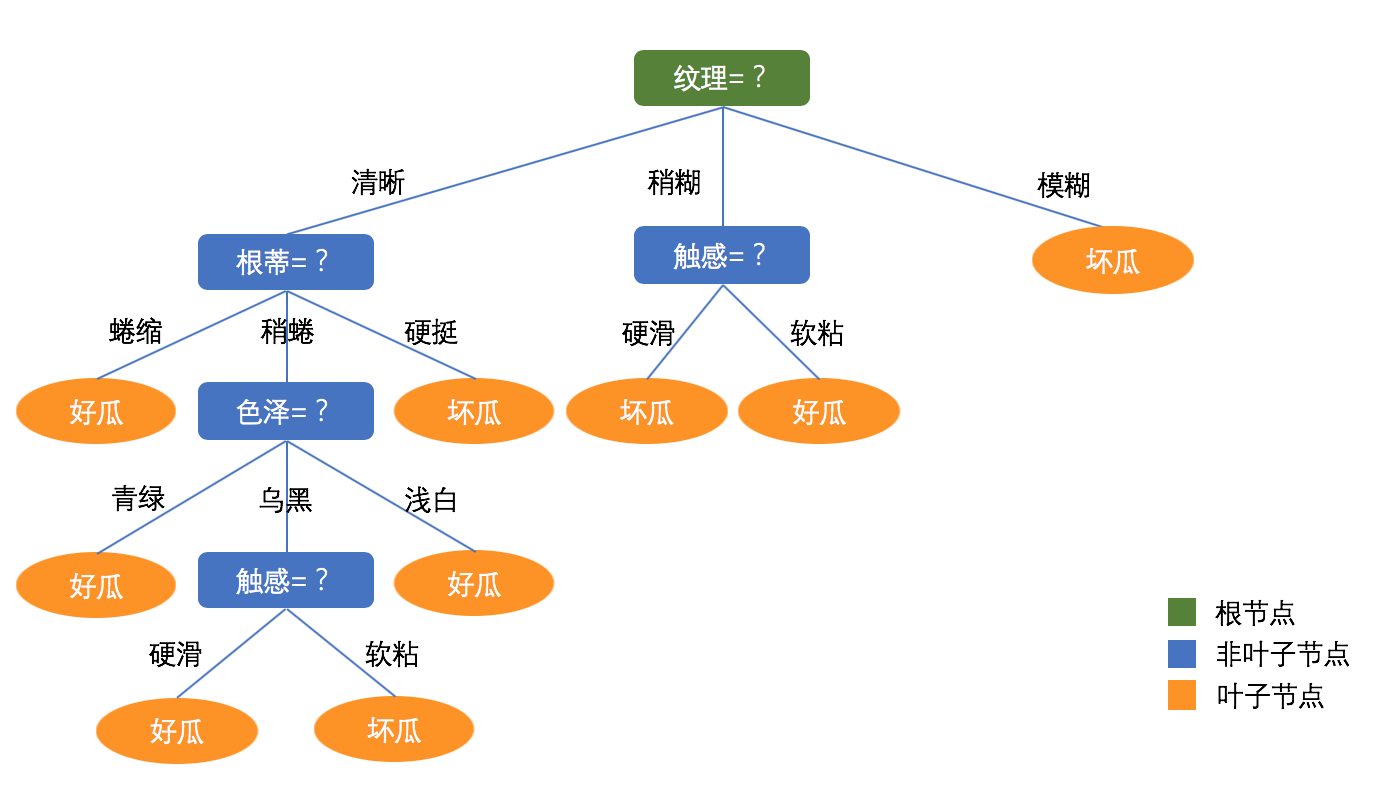
决策树优缺点:
- 优点:计算复杂度不高,输出结果易于理解,对中间值的确实不敏感,可以处理不相关特征数据
- 缺点:可能会产生过度匹配问题
- 适用数据类型:数值型和离散型
一般决策树的实现主要包含以下三个步骤:节点特征的选取(信息增益)、决策树的构建(利用递归的方式,具体参考代码)、决策树修剪(防过拟合)
【节点特征的选取】
整体思路:
1. 我们希望在决策树决策过程中,每经过一次决策,分类后的集合,纯度越来越高;
2. 我们从中选取能使分类结果最纯的某一属性,作为当前的决策属性。
常用的算法如下:
- ID3:信息增益
- C4.5:信息增益率
- CART:使用GINI系数来当做衡量标准
【信息增益】
信息熵 ,是用来度量样本集合纯度最常用的一种指标,在决策树中被用来选取属性特征作为节点。熵,表示随机变量的不确定,即混乱程度。
其中表示当前样本集合D中第类样本所占的比例
对于单个变量的熵来说:
当时,,即随机变量完全没有不确定性
当,,此时随机变量的不确定性最大。
信息增益
有了信息熵的定义后,信息增益的概念便很好理解了,表示分类后,数据整体信息熵的差值。假定离散属性有个可能的取值,即表示数据集中的结果有种取值。我们使用对样本集D进行划分,则会产生个分支节点,其中第个分支节点包含了D中所有在属性上取值为的样本,记为,考虑到不同的分支节点所包含的样本数不同,给分支节点赋予权重,即样本数越多的分支节点的影响越大,故信息增益如下式:
【信息增益率】
信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的影响,我们采用信息增益率:
其中
称为属性的“固有值”,属性的可能取值数目越多(即V越大),则的值通常会越大。
缺点:增益率准则,对可取值树木较少的属性有所偏好,所以C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
【GINI指数(基尼指数)】
GINI系数也是度量数据集纯度的一个标准,故数据集D的GINI值表达式为:
直观上来讲,反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率,因此越小,则数据集D的纯度越高。
属性的指数定义为:
故,选择那个使得划分后基尼指数最小的属性作为最优划分属性。
【剪枝】
使用决策树有时会出现“过拟合”的情况,为了解决过拟合的,故引入剪枝的策略,剪去多余的“枝干”,减低过拟合发生的风险。有两种剪枝策略:
- 预剪枝
- 后剪枝
对于此部分内容,请参阅:https://blog.csdn.net/zfan520/article/details/82454814,
在此不再做介绍,该文章讲解的很细致,配图也十分详细
【决策树损失函数的理解】(借的内容)
算法目的:决策树的剪枝是为了简化决策树模型,避免过拟合。
算法基本思路:减去决策树模型中的一些子树或者叶结点,并将其根结点作为新的叶结点,从而实现模型的简化。
模型损失函数
变量预定义:表示树T的叶节点个数,t表示树T的叶节点,同时,
表示该叶节点的样本点个数,其中属于类的样本点有
个,表示类别的个数,
为叶结点上的经验熵,
为参数损失函数:
简化表示:
经验熵:
损失函数简化形式:
这里的经验熵反应了一个叶结点中的分类结果的混乱程度,经验熵越大,说明该叶节点所对应的分类结果越混乱,也就是说分类结果中包含了较多的类别,表明该分支的分类效果较差。所以,损失函数越大,说明模型的分类效果越差。
决策树的剪枝通常分为两种,即预剪枝、后剪枝。
预剪枝是在决策树生成过程中,对树进行剪枝,提前结束树的分支生长。
后剪枝是在决策树生长完成之后,对树进行剪枝,得到简化版的决策树。
下面的算法,是后剪枝的实现步骤。
输入:生成算法产生的整个树,参数
输出:修剪后的子树
- 计算每个结点的经验熵
- 递归地从树的叶结点向上回缩
设一组叶结点回缩到父结点之前与之后的整体树分别为
和
,其对应的损失函数值分别是
与
,如果
,即如果进行剪枝,损失函数变小,就进行剪枝,将父结点变为新的叶结点- 返回(2),直至不能继续为止,得到损失函数最小的子树
参考文章:
https://www.cnblogs.com/MrLJC/p/4099404.html
https://blog.csdn.net/jiaoyangwm/article/details/79525237
https://blog.csdn.net/zfan520/article/details/82454814
决策树损失函数:
https://blog.csdn.net/ritchiewang/article/details/50254009
https://blog.csdn.net/wzk1996/article/details/81941572?utm_source=blogxgwz1
共同学习,写下你的评论
评论加载中...
作者其他优质文章



