
前言
2019年来了,2020年还会远吗? 请把下一年的年终奖发一下,谢谢。。。
回顾逝去的2018年,最大的改变是从一名学生变成了一位工作者,不敢说自己多么的职业化,但是正在努力往那个方向走。
以前想的更多是尝试,现在需要考虑的更多是落地。学校和公司还是有很大的不一样,学到了很多东西。
2019年了,新年新气象,给大家宣布一下”七夜安全博客“今年的规划:
1. 2019年不再接任何商业广告(文末腾讯广告除外),纯粹输出安全技术干货。
2. 2019年每周至少两篇原创图文,也就是说每个月至少八篇文章。
3. 2019年每篇图文都不再单独开赞赏,统一在每个月1号开赞赏,并回顾上个月的内容,简称收租,大家觉得上个月的文章不错,就多赞赏即可
4. 2019年的主题是二进制安全,至少上半年是这样,包括木马的设计与检测方面,会按照系列和专题发布文章。
废话不多说,新的一年就从哈勃沙箱说起,用来检测linux恶意文件。
哈勃沙箱
今天说的哈勃沙箱是腾讯哈勃检测系统中,linux恶意文件检测部分的开源代码。github地址为:
https://github.com/Tencent/HaboMalHunter
今天是源码剖析的第一篇,目标是简要介绍一下沙箱使用的检测手段和主要技术点。从github中输出的html报表里,监控的信息还是挺丰富的。这里只截取一部分,根据github中的说明,大家很容易就可以搭建一个沙箱。

静态检测
在哈勃沙箱的代码目录中,static目录下即为静态检测的代码,代码很清晰。静态检测的本质是特征码匹配,对已知的恶意文件进行快速匹配进而查杀,如果能在静态检测层面发现恶意代码,就不需要动态分析了,这样速度就会快很多。
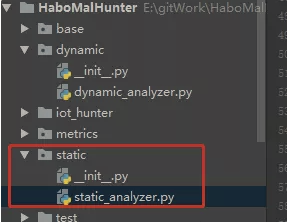
从static_analyzer.py来看,哈勃linux沙箱静态检测,获取的信息主要有六个方面:
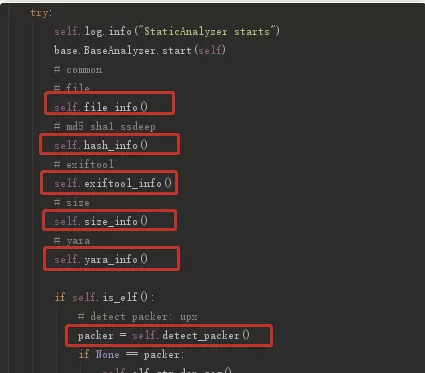
1. 文件类型信息
通过file命令获取文件信息,比如是二进制还是其他类型文件,在linux中是无法通过后缀判断它是什么文件的。

2. 文件hash比对
对于已知的恶意文件都有相应的hash库,方便快速比对。哈勃主要计算文件的md5,sha1,sha256,这是一种绝对匹配方式。

还有一种方式是计算文件的ssdeep值,这个在我之前在公众号讲webshell检测时讲过这个,这个值可以通过相似度判断恶意文件的一些变形。

3. exiftool信息
获取文件属性信息,通过exiftool工具来实现,内容包括修改时间,创建时间等等。

4. 文件大小
文件大小也是一个辅助判断的依据,毕竟木马文件不会很大,几兆的木马文件上传也是费事。
5. yara模糊过滤
YARA是一款旨在帮助恶意软件研究人员识别和分类恶意软件样本的开源工具,使用YARA可以基于文本或二进制模式创建恶意软件家族描述信息。
YARA的每一条描述或规则都由一系列字符串和一个布尔型表达式构成,并阐述其逻辑。YARA规则可以提交给文件或在运行进程,以帮助研究人员识别其是否属于某个已进行规则描述的恶意软件家族。比如下面这个例子:
| 12345678910111213 | rule silent_banker : banker{ meta: description = "This is just an example" thread_level = 3 in_the_wild = true strings: $a = {6A 40 68 00 30 00 00 6A 14 8D 91} $b = {8D 4D B0 2B C1 83 C0 27 99 6A 4E 59 F7 F9} $c = "UVODFRYSIHLNWPEJXQZAKCBGMT" condition: $a or $b or $c} |
实现代码为:

6. 查壳
一般的恶意文件,为了防止被逆向人员分析,都会加壳的。
哈勃主要是判断了是否是upx壳。如果是upx,则进行解压。判断是upx壳的方法很简单,直接使用upx进行解压,返回是否成功。

接着提取以下信息:
明文字符串(通过strings命令),
动态库(通过ldd命令)
入口点,节,段,符号等信息(通过readelf命令)

动态检测
动态检测是沙箱的核心部分,但是本篇不展开讲解,在下一篇进行详细分析,因为动态检测的原理比较复杂。动态检测的内容在dynamic目录下的dynamic_analyzer.py文件里。

一般的动态检测主要是监视程序三个部分的内容:
syscall系统调用
进程内存
网络流量
对于系统调用,哈勃使用了三种方式进行了全方位的监控:ltrace/strace/sysdig。
ltrace和strace
ltrace和strace都是基于ptrace机制进行检测的,但是又有很大的不同,strace跟踪系统调用,而ltrace可以跟踪动态库函数。我们知道,ptrace机制可以用来跟踪系统调用,那么ltrace是如何使用它跟踪库函数呢?
首先ltrace打开elf文件,对其进行分析。在elf文件中,出于动态链接的需要,需要在elf文件中保存函数的符号,供链接器使用。具体格式,大家可以参考elf文件的格式。
这样ltrace就能够获得该文件中,所有系统调用的符号,以及对应的执行指令。然后,ltrace将该执行指令所对应的4个字节替换成断点指令。
这样在进程执行到相应的库函数后,就可以通知到了ltrace,ltrace将对应的库函数打印出来之后,继续执行子进程。
实际上ltrace与strace使用的技术大体相同,但ltrace在对支持fork和clone方面,不如strace。strace在收到fork和clone等系统调用后,做了相应的处理,而ltrace没有。
至于sysdig的原理,以及与ltrace,strace的区别,我们会在下一文章中进行详细说明。
内存分析
对于内存,沙箱基本上都是基于volatility来做的,哈勃也不例外。哈勃主要分析了两部分内存:
1.bash 调用历史
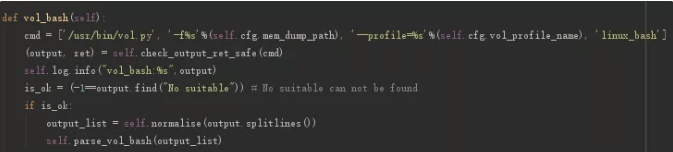
2.父子进程的关系

网络分析
对于网络,沙箱主要做了两个部分的工作,一部分是虚拟网络环境,另一部分是网络抓包。
1.INetSim虚拟网络环境

2.tcpdump 抓取数据包
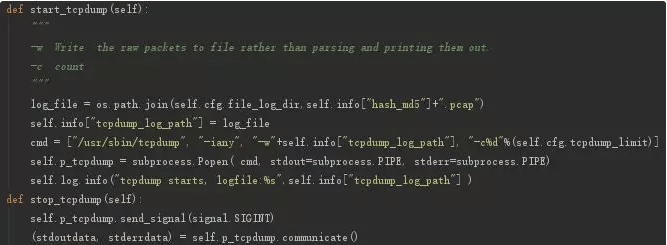
有的木马,还会有自删除,自锁定,自修改的行为,这是一些自保护的需要。沙箱中对此也进行了检测:

现有代码的不足
对于开源的部分代码,发现一些不能落地生产环境的地方,付费版的代码应该没这些问题。
1.没有实现检测的自动化
它是把沙箱安装到虚拟机中,然后人工拖动程序进入沙箱检测,没有发现自动化的代码。当然,对于虚拟机的自动化控制,这个是可以做的,二次开发。
2.没有策略
沙箱的检测策略是没有开源的,这是很宝贵的东西。我们虽然可以获取大量的信息,但是哪些是恶意的,我们没办法判别。当然这就是我们策略该做的事情了,只要有样本,策略还是可以做的。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



