
承接上文,探讨kd二叉查找树的平衡、删除改进以及运用。
无论是普通的二叉查找树还是kd二叉查找树,频繁的添加以及删除操作都可能破坏整棵树的平衡,怎么办呢?对于普通的二叉查找树,可以通过DSW算法或者AVL算法进行平衡,相关内容可以看这里,数据结构与算法-二叉查找树(DSW)和数据结构与算法-二叉查找树(AVL)。以上算法的核心都是旋转,通过旋转来调整左右子树的高度来平衡树,但是旋转对于kd二叉树是不合适的,因为kd二叉树不同层次之间比较的维度是不同的。比如说存在节点P,比较的维度是x吧,那么节点P的左子树中任意节点的x维度的值小于P节点x维度值,右子树中任意节点的x维度的值大于P节点x维度值。如果将P节点调高或者降低层次,那么P节点和左右子树比较的维度就会改变,假如是y吧。不能保证节点P的左子树中任意节点的y维度的值小于P节点y维度值,右子树中任意节点的y维度的值大于P节点y维度值。所以,旋转不能用于kd二叉树。
那么,该怎么平衡一颗kd二叉查找树呢?
答案是删除原有的树,重新创建一颗平衡的kd二叉查找树。这种方法非常暴力,如果用于生产环境,必须选择服务器压力较小的一个时间点来重新平衡树。并且,要控制重新创建kd树的频率,这个频率需要在生产环境中,根据具体的数据量来调整。
接下来探讨改进删除算法。删除算法的效率不高,原因在于需要不停的遍历被删除节点下的某颗子树,不仅耗费时间而且浪费计算资源。怎么改进呢?
有一种叫做替罪羊的算法可以用到这里。就是说,每次删除节点的时候,不是真正的删除,而是做个标记表明这个节点已删除,这样就不会影响kd树的平衡。但是被标记的节点太多也不好,怎么处理呢?可以在每次删除的时候进行检查,统计被标记节点在整棵树中的比例,如果比例大于阈值,就重新平衡树。删除掉被标记的节点,使用剩余节点创建新的平衡的kd二叉树。由于重新创建kd树是由某个节点删除引起的,但是显然责任不是它一个节点的,它就成了替罪羊,因此,算法就以此命名了。替罪羊算法效率还是可以的,牺牲较小的查找效率来获取整棵树的平衡是可取的,生产环境可以考虑使用。
下面来探讨kd二叉查找树的运用。
查找符合特定范围的节点
假设我们有一系列点处于k维空间中,现在有个需求,需要知道符合x1<x<xn,y1<y<yn,...,k1<k<kn的节点有哪些。如果没有kd二叉树,只能通过遍历筛选出符合要求的节点,显然,这种方式效率不高。kd二叉树可以帮助我们跳过一些节点来提高查找效率。首先用自然语言描述算法逻辑:
假设存在节点P,节点P所处层次需要比较维度x,首先判断x(P)处于x1<x<xn的哪个范围。如果x1<x(P)<xn,显然,需要遍历P节点的所有子树,如果x(P)<x1,那么只需要遍历P节点的右子树,如果x(P)>xn,那么只需要遍历P节点的左子树即可。
伪代码如下:
searchRange(range[][]){
if root != 0
search(root, 0, range);
}
search(p, i, range[][]){
found = true;
for j = 0 到 k - 1
if !(range[j][0] <= p-el.keys[j] <= range[j][1])
found = false;
bread;
if found
输出 p->el;
if p->left != 0 && range[i][1] <= p->el.keys[i]
search(p->left, (i + 1) mod k, range);
if p->right != 0 && range[i][0] >= p->el.keys[i]
search(p->right, (i + 1) mod k, range);
}使用kd二叉树查找特定范围的节点相比于直接遍历要快的多。
实现kNN算法
kNN的全称是k-Nearest-Neighbor,k个最近邻点。也就是说,假设现在有n个m维空间的点,给定点P,需要找到与定点P最靠近的k个点,这就是kNN算法。这里距离的求法用的是欧式距离:
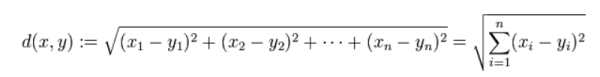
最直观的算法逻辑是遍历n个节点,计算出每个节点与定点P的距离,然后排序,获取距离最小的k个邻点。算法的时间复杂度是0(n),还可以接受,但是太占用计算资源了,每两个节点距离的计算需要n次减法,n次平方,不仅仅占用大量时间,还会占用大量计算资源,得不偿失。
当前有很多kNN解决方案,我们来探讨基于kd二叉树的kNN方案。
在探讨之前,我们需要理解kd二叉树的几何意义,就从一维kd二叉树开始。
当k为1时,kd二叉树就退化为普通的二叉查找树,我们可以将二叉树上的节点想象成横坐标上的定点。就像这样:
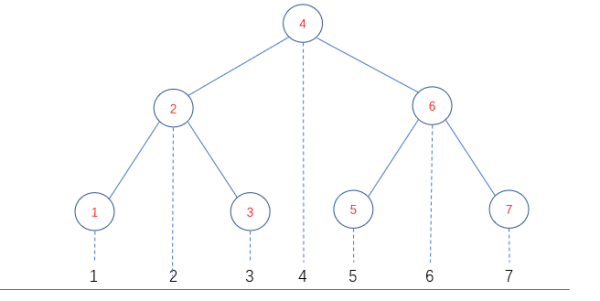
横坐标被分解成8个部分,如果给出定点P,那么该定点最终会落入这8个部分之一。
当k为2时,kd二叉树中的节点可以想象成坐标系上的点,就像这样:
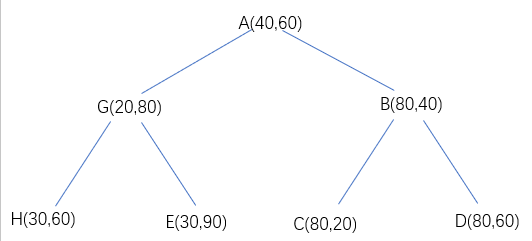
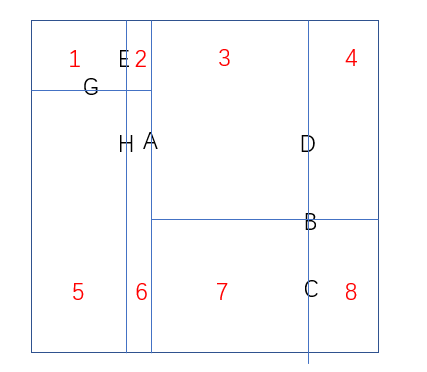
其中每个点都代表着一部分区域,首先A节点代表整个矩形,G节点代表被A分开的左边的矩形,B节点代表被A分开的右边的矩形,以此类推,每个节点代表着某块区域的同时将该区域分割成两部分,分别被左右子树占据。
也就是说,如果给出一个定点P,那么P必然落入以上8个区域之一。
在kd二叉树上实现kNN算法之所以效率较高,是因为kd二叉树可以将k维空间分割成m个区域,给出的查找定点必然落入某个区域之中,该区域必然被某个节点P的左子树或者右子树占据,假设定点落入了左子树中,我们可以计算出在该区域中距离定点最近的节点,假设距离为l1。下面是核心逻辑,我们已经获取了节点P左子树中距离定点最近的节点,那么节点P的右子树有必要遍历吗?假设节点P比较的是x维度的值,我们可以计算出定点和x=x(P)超平面之间的距离l2。如果l1<l2,那么就没必要遍历右子树了,因为定点距离右子树中节点的距离只会比l2更大,也就是说l1肯定是最小的距离。如果l1>l2,那么就有必要遍历右子树,因为右子树中可能存在距离定点更近的节点。到目前为止,我们已经获取了节点P所代表的的子树中距离定点最近的节点,下一步怎么走?我们知道,节点P必然是某个节点R的左子树或者右子树,假设是左子树吧,那么问题来了,节点R的右子树需要遍历吗?这就回到了上面的问题,你会发现,通过不断回溯父节点,我们可以不断的跳过某些子树,最终整棵树里的节点全部遍历完毕。因为kd树在查找距离定点最近节点时,可以跳过很多子树,因此效率会大大提高。
下面用自然语言描述kNN算法:
给出定点P,首先获取定点P落入了哪块区域,假设是区域Q吧,计算出定点P和区域Q中节点最小的距离l1
回溯到父节点R,计算定点P和节点R之间的距离l2,取l1和l2之间的最小值为新的l1
假设节点R比较的是x维度的值,计算定点P和x=x(p)超平面之间的距离l3
如果l1<l3,跳过R节点的另一颗子树,继续回溯到R节点的父节点,如果R节点为Root,遍历结束,否则从第二步开始
如果l1>l3,遍历R节点的另一颗子树,获取定点和该子树中节点最小的距离l4
取l1和l4之间的最小值为新的l1,当前,R节点所在子树已经遍历完毕,那就继续回溯到R节点的父节点,如果R节点为Root,遍历结束,否则从第二步开始
算法中,也许有人会疑惑l4的大小如何获取,也就是说,不知道如何遍历R节点的另一颗子树。答案是使用递归,因为R节点的子树也是一颗kd二叉树,我们对该子树使用递归即可获取l4的大小。
到目前为止,我们已经探讨了kd二叉树的平衡,删除算法改进,输出符合特定范围的节点以及最后的kNN算法。kd二叉树还有很多细节需要去理解,这些需要读者在实践中获取了。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


