
1 性能优化工具类
1.1 FastThreadLocal
1.1.1 传统的ThreadLocal
ThreadLocal最常用的两个接口是set和get
最常见的应用场景为在线程上下文之间传递信息,使得用户不受复杂代码逻辑的影响
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
t.threadLocals;
我们使用set的时候实际上是获取Thread对象的threadLocals属性,把当前ThreadLocal当做参数然后调用其set(ThreadLocal,Object)方法来设值
threadLocals是ThreadLocal.ThreadLocalMap类型的
每个线程对象关联着一个ThreadLocalMap实例,主要是维护着一个Entry数组
Entry是扩展了WeakReference,提供了一个存储value的地方
一个线程对象可以对应多个ThreadLocal实例,一个ThreadLocal也可以对应多个Thread对象,当一个Thread对象和每一个ThreadLocal发生关系的时候会生成一个Entry,并将需要存储的值存储在Entry的value内
- 一个ThreadLocal对于一个Thread对象来说只能存储一个值,为Object型
- 多个ThreadLocal对于一个Thread对象,这些ThreadLocal和线程相关的值存储在Thread对象关联的ThreadLocalMap中
- 使用扩展WeakReference的Entry作为数据节点在一定程度上防止了内存泄露
- 多个Thread线程对象和一个ThreadLocal发生关系的时候其实真实数据的存储是跟着线程对象走的,因此这种情况不讨论
我们在看看ThreadLocalMap#set:
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
每个ThreadLocal实例都有一个唯一的threadLocalHashCode初始值
上面首先根据threadLocalHashCode值计算出i,有下面两种情况会进入for循环:
- 由于
threadLocalHashCode &(len-1)对应的槽有内容,因此满足tab[i]!=null条件,进入for循环,如果满足条件且当前key不是当前threadlocal只能说明hash冲突了 - ThreadLocal实例之前被设置过,因此满足tab[i]!=null条件,进入for循环
进入for循环会遍历tab数组,如果遇到以当前threadLocal为key的槽,即上面第(2)种情况,有则直接将值替换
如果找到了一个已经被回收的ThreadLocal对应的槽,也就是当key==null的时候表示之前的threadlocal已经被回收了,但是value值还存在,这也是ThreadLocal内存泄露的地方。碰到这种情况,则会引发替换这个位置的动作
如果上面两种情况都没发生,即上面的第(1)种情况,则新创建一个Entry对象放入槽中
private Entry getEntry(ThreadLocal key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
当命中的时候,也就是根据当前ThreadLocal计算出来的i恰好是当前ThreadLocal设置的值的时候,可以直接根据hashcode来计算出位置,当没有命中的时候,这里没有命中分为三种情况:
- 当前ThreadLocal之前没有设值过,并且当前槽位没有值。
- 当前槽位有值,但是对于的不是当前threadlocal,且那个ThreadLocal没有被回收。
- 当前槽位有值,但是对于的不是当前threadlocal,且那个ThreadLocal被回收了。
上面三种情况都会调用getEntryAfterMiss方法。调用getEntryAfterMiss方法会引发数组的遍历。
总结一下ThreadLocal的性能,一个线程对应多个ThreadLocal实例的场景中
在没有命中的情况下基本上一次hash就可以找到位置
如果发生没有命中的情况,则会引发性能会急剧下降,当在读写操作频繁的场景,这点将成为性能诟病。
1.1.2 实例

两个线程操作同一object 对象,显然非线程安全,但是由于使用了 FTL, 线程安全!
结果表明内存地址不同,并非操作同一个 object!
让T1每1s 中新生成一个 object 对象
T2验证当前 object 是否与之前状态相同
显然,每个线程拿到的对象都是线程独享的!
某线程对变量的修改不影响其他线程!
通过对象隔离优化了程序性能!
1.1.3 Netty FastThreadLocal源码解析

1.1.3.1 创建

创建时重写一下初始值方法

实际上在构造FastThreadLocal实例的时候就决定了这个实例的索引
index 为 private 且非 static, 说明每个实例都有该值
再看看索引的生成相关代码
index 从0开始计数

nextIndex是InternalThreadLocalMap父类的一个全局静态的AtomicInteger类型的对象,这意味着所有的FastThreadLocal实例将共同依赖这个指针来生成唯一的索引,而且是线程安全的
Netty重新设计了更快的FastThreadLocal,主要实现涉及
- FastThreadLocalThread
- FastThreadLocal
- InternalThreadLocalMap
FastThreadLocalThread是Thread类的简单扩展,主要是为了扩展threadLocalMap属性
FastThreadLocal提供的接口和传统的ThreadLocal一致,主要是set和get方法,用法也一致
不同地方在于FastThreadLocal的值是存储在InternalThreadLocalMap这个结构里面的,传统的ThreadLocal性能槽点主要是在读写的时候hash计算和当hash没有命中的时候发生的遍历,我们来看看FastThreadLocal的核心实现
InternalThreadLocalMap实例和Thread对象一一对应
UnpaddedInternalThreadLocalMap维护着一个数组:
这个数组用来存储跟同一个线程关联的多个FastThreadLocal的值,由于FastThreadLocal对应indexedVariables的索引是确定的,因此在读写的时候将会发生随机存取,非常快。
另外这里有一个问题,nextIndex是静态唯一的,而indexedVariables数组是实例对象的,因此我认为随着FastThreadLocal数量的递增,这会造成空间的浪费
1.1.3.2 get方法实现
获取 ThreadLocalMap




首先拿到当前线程,再判断是否为 FTL 线程快速获取否则慢速获取
- 让我们先分析一下 slowGet方法

首先会获取一个 ThreadLocal 变量
拿到 JDK 的 ThreadLocal 变量,用于给每个线程拿到InternalThreadLocalMap变量,所以过程较慢,该方法称为 slowGet 可想而知!
由于在创建 ThreadLocal 时,并没有重写 initValue 方法,所以可能为null - 接下啦看 fastGet 方法







直接通过索引取出对象



通过每个线程独享的 ThreadLocalMap 对象借助在 JVM 中每个 FTL 的唯一索引
1.2 轻量级对象池 Recycler
1.2.1 Recycler的使用


所以不使用 new 而是直接复用
Netty使用
1.2.2 Recycler的创建
- 创建方式为直接new 一个 Recycler 对象,然后重写
newObject方法 - 转到构造方法


再看看每个Recycler 的结构是如何的
- 每个Recycler 中对应每条线程都持有一个 Stack 对象
- 下面图示说明

看下 Stack对象 的 element 参数,一些默认处理器的数组,该数组实际存放对象池,每个处理器都包装了一个对象,handler 可被外部对象引用.,从而回收该对象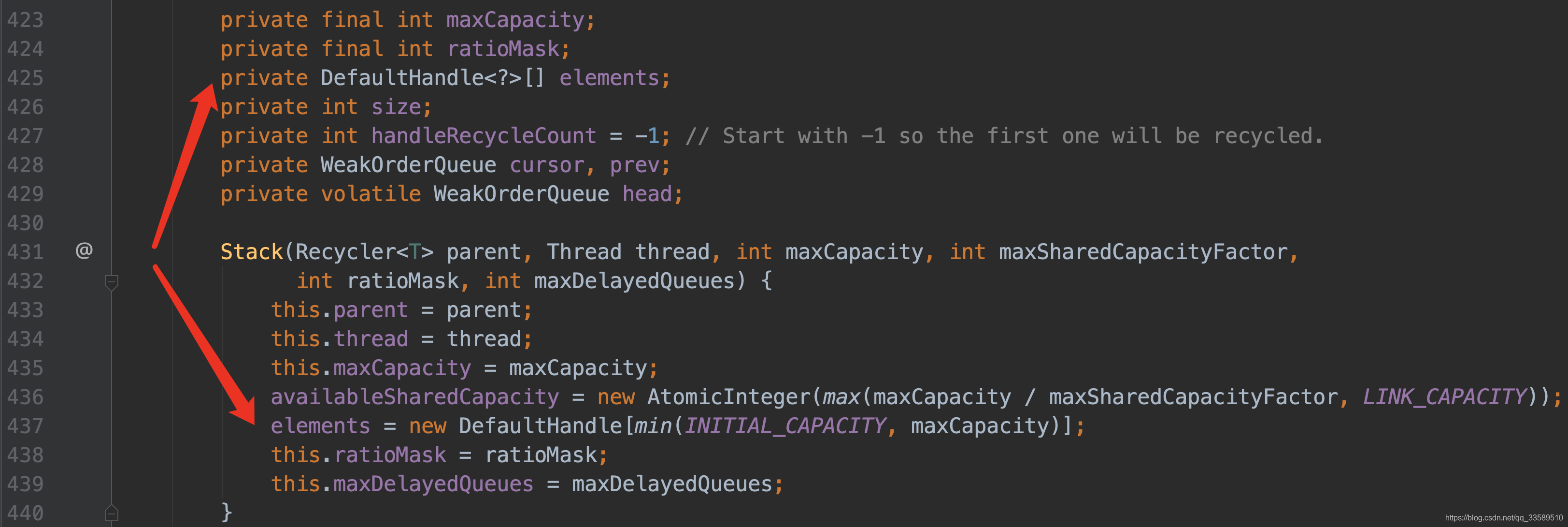
-
参数列表
-
其中,radiomask 控制对象回收的比率,所以并非每次调用recycler 都会发生回收
-
maxcapacity 池子最大元素容量
-
线程1残留的对象会缓存到线程2中继续释放
所以 maxdelayedqueues 也就是可以缓存对象的线程数.如若再有个线程3,而队列结构在线程2,那3会直接抛弃1的残留对象. -
availablesharedcapacity:线程1中创建的对象能够在其他线程中缓存的对象的最大个数.
以上即为 Stack 对象所有成员变量.


下面回到Recycler的构造方法,看其入参.



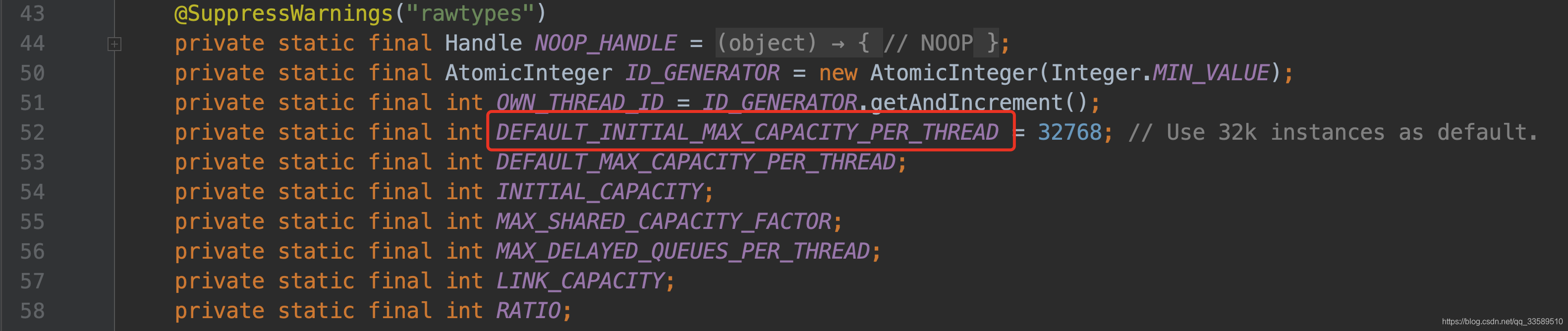
该数值即为Stack 数组元素能有多少个
- 再看看如下构造方法的参数.
- 默认值为2
- 看看新的构造器的 radio 参数
- 默认值8
- 两倍CPU核心数
- 自然该值为7






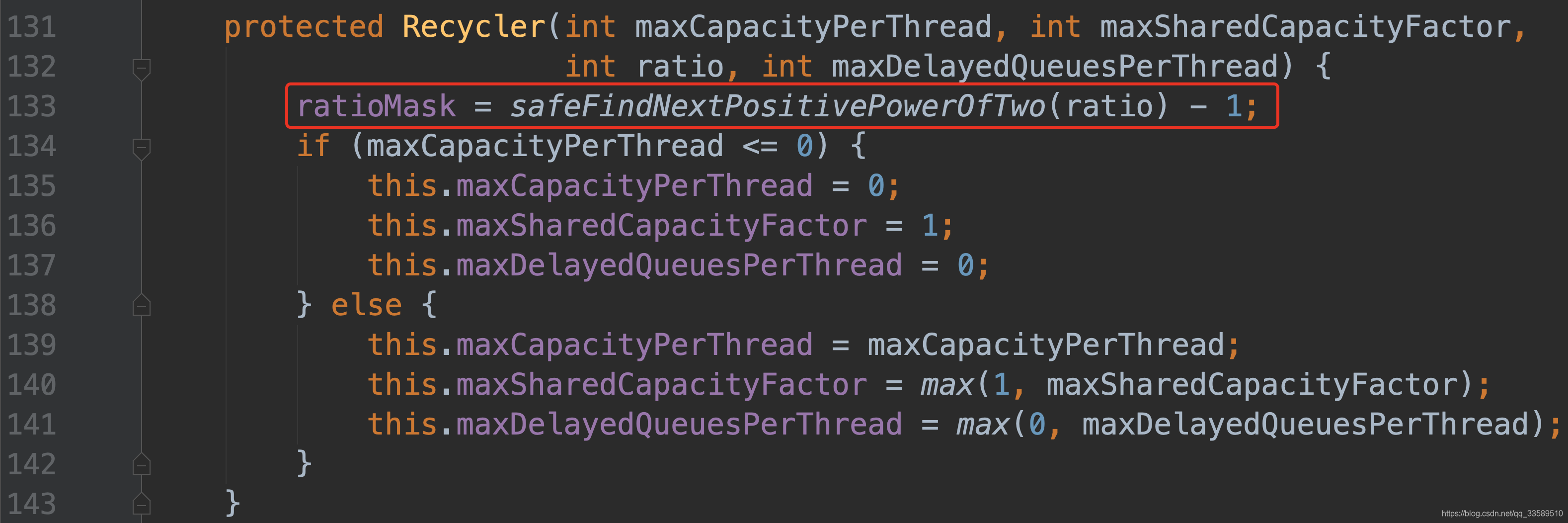

1.2.3 回收对象到 Recycler
1.2.3.1 同线程回收
- 客户端开始调用
- Recycler抽象类
- 将当前对象压栈
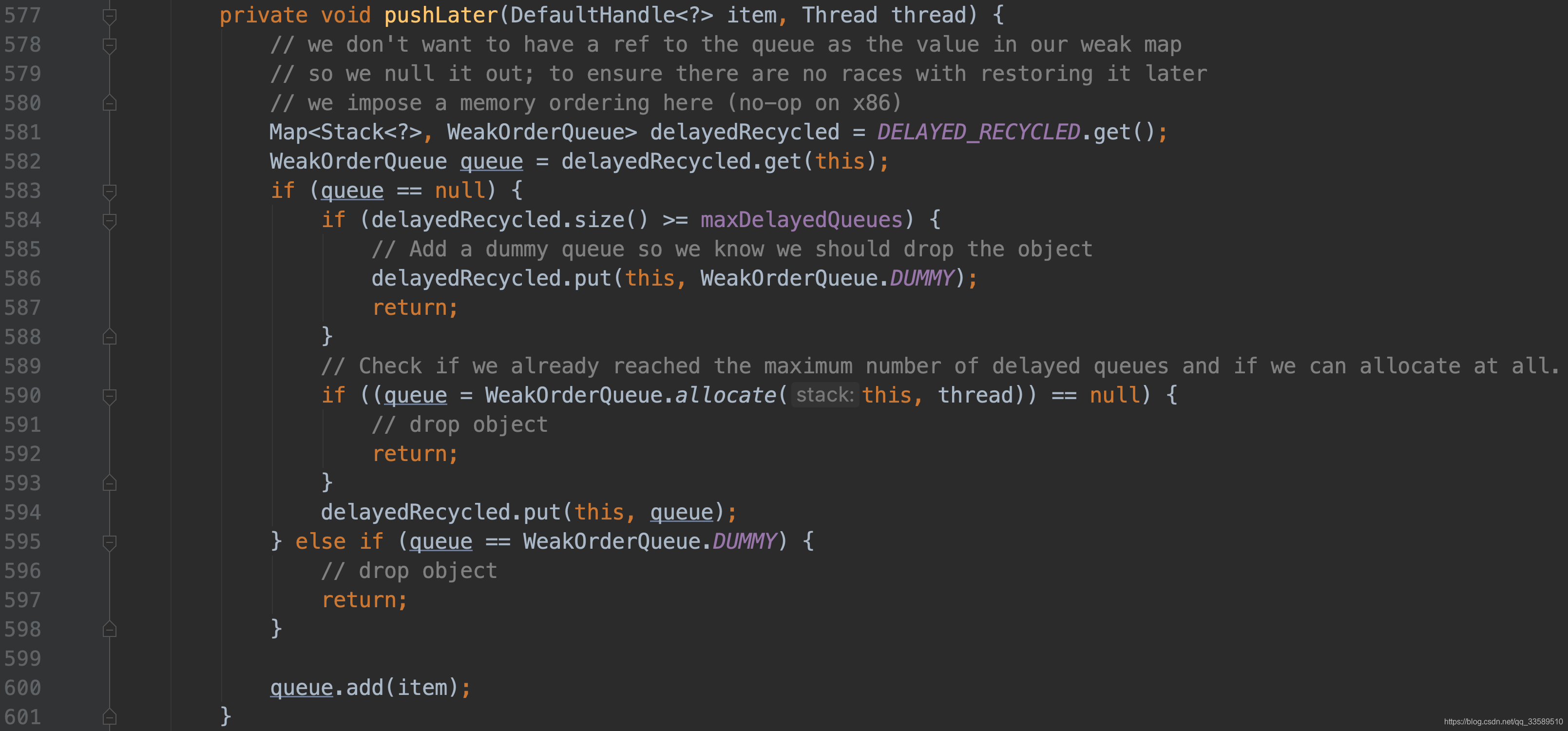
- 如下,首先判断当前线程,thread 即为S tack 对象中保存的成员变量,若是创建该 stack 的线程,则直接压栈Stack 中,若不是再 pushlater.先分析 pushnow.

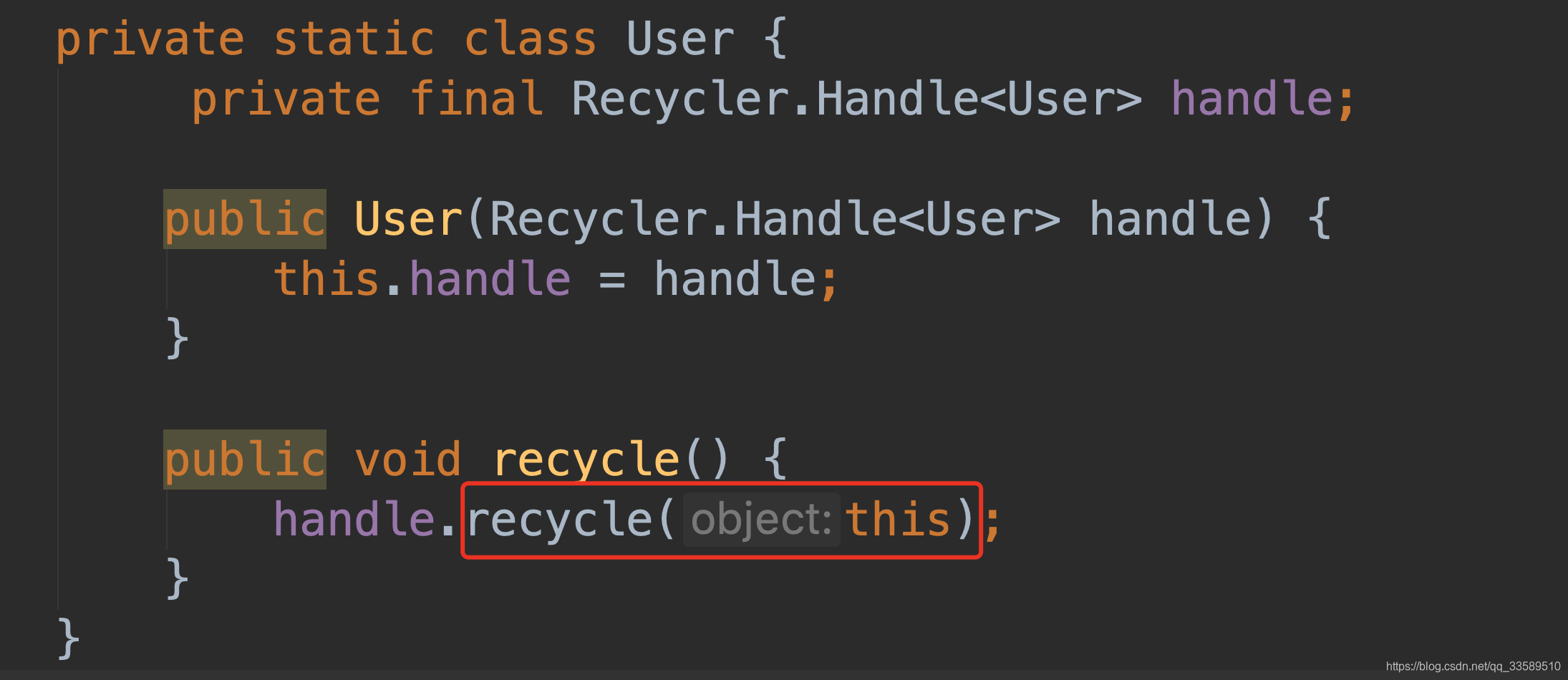



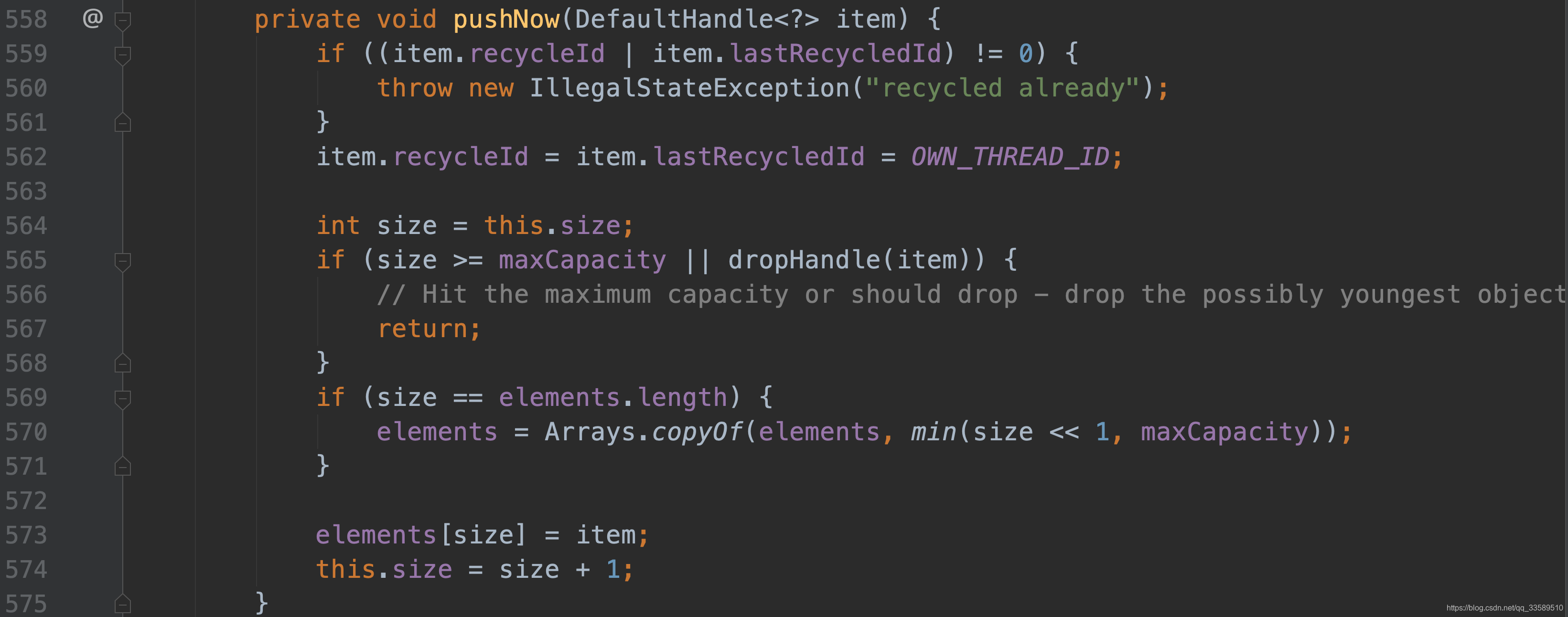
-
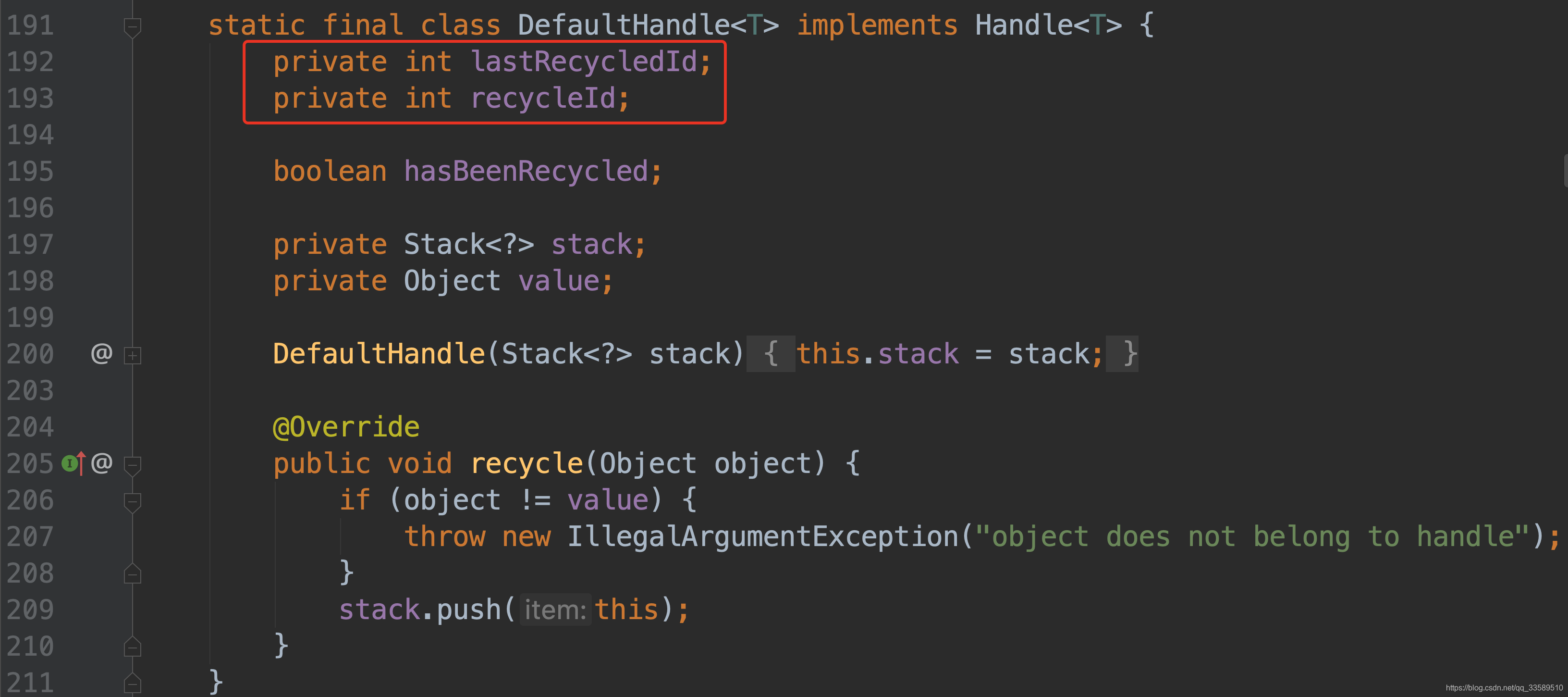
首先验证两个 id,由于默认初始值为0,所以通过判断.
-
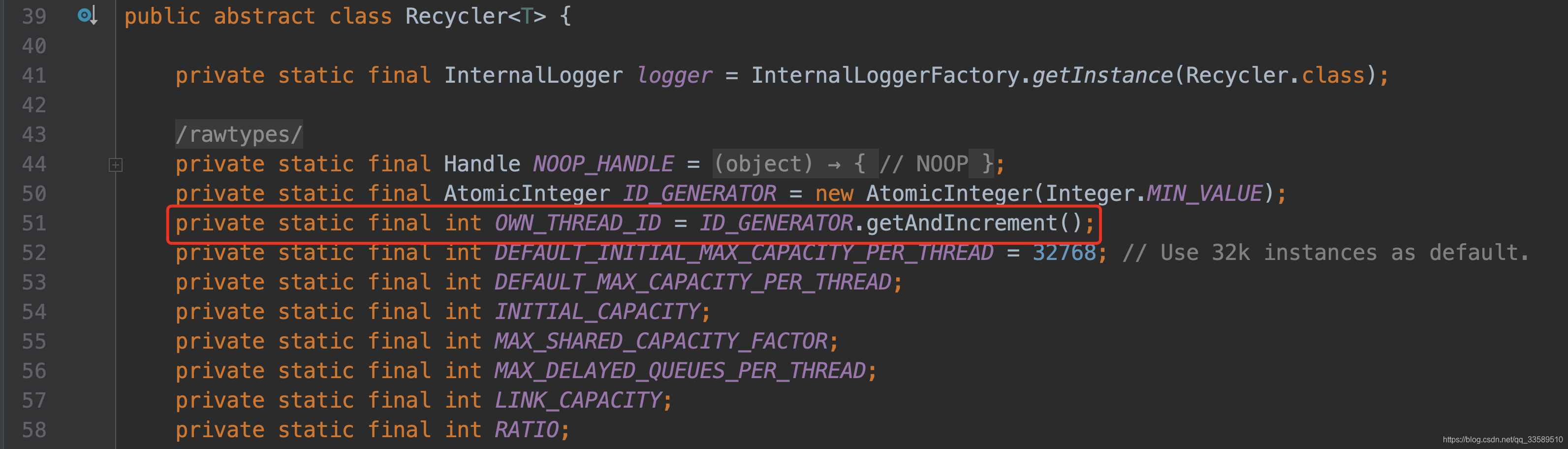
接下来将其都赋值为第三个 id,该值在整个Recycler 中都是唯一确定值
紧接着判断当前 size是否已到 maxcapacity,若达到上限,直接丢弃该对象即直接 return;否则继续判断 drop 处理器
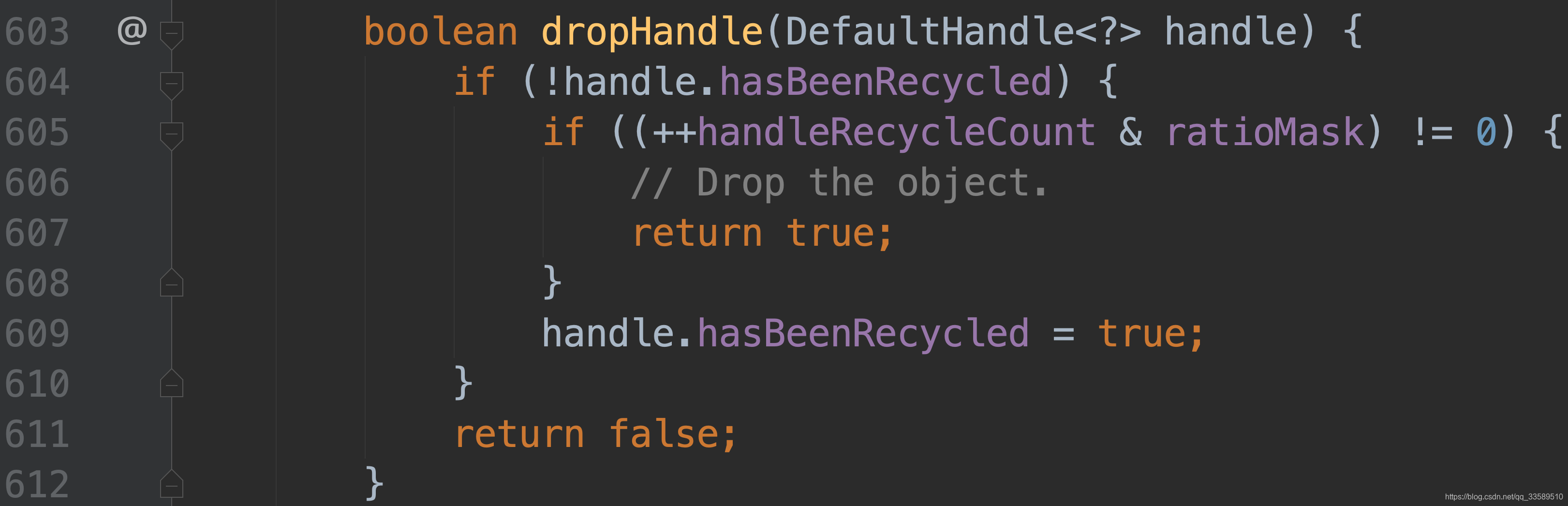
首先判断,若该对象之前未被回收过,继续判断;
至今已经回收了多少个对象,其中 rm 为7,即111(二进制表示),即每隔8个对象,就会来此判断一次,将其与7进行与运算后,若不为0,则返回 true,表示只回收八分之一的对象.
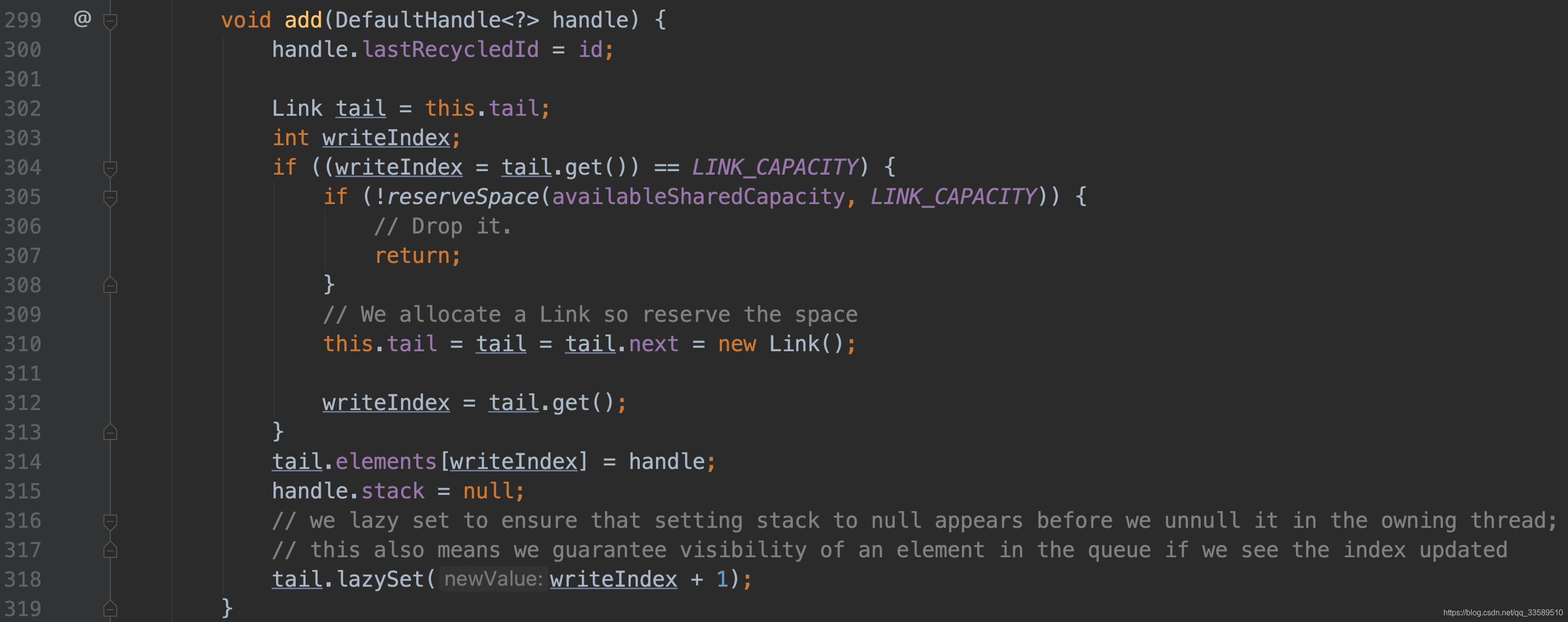
继续回到 pushnow 的流程,接下来判断 size 是否等于数组的容量.
因为 element 是一个数组,并不是一开始就创建maxcapacity 容量大小,若容量不够了,则进行两倍大小扩容,再将其加入数组.
1.2.3.2 异线程回收对象
- 本节食用指南

1.2.3.2.1 获取 WeakOrderQueue(以下简称WOQ)
由前面 pushnow 进入同线程回收, pushlater 即进入异线程回收过程.
- 先看看这么个东西是啥
其类型就很神奇了,首先是个FTL,即每个线程都有一个 map,map 的key=stack 表示对于不同线程,对不同 stack 来说对应于不同的WOQ.
那么它为何要定义成一个 map 结构呢,假设有3个线程T1/2/3;
T1创建的对象肯可能跑到T3中回收,T2中创建的对象也可能到了T3回收.
那么元素就是T1以及T2的WOQ.


假设当前在T2中,接下呢就通过get(this)拿到T1的WOQ,其中的 this 指的就是T1的 Stack.
然后若 queue==null,即表示T2从未回收过T1的对象,接下来开始判断
当前的即T2已经回收过的线程数 size,若不小于 mDQ,说明已经不能再回收其他线程的对象了!
给WOQ设置 dummy 标志,即对应下面的若下次看到一个线程标志了 dummy 直接return;什么也不做.
以上即为第一个过程,从FTL中拿一个Stack 对应的WOQ.
1.2.3.2.2 创建 WeakOrderQueue
若之前没拿到呢,那就直接创建一个WOQ吧!
- 接下来让我们看看一个线程创建WOQ是如何与待回收对象的Stack 进行绑定的.
其中的 this 即为 stack,是在T1中维护的,thread 即表示当前线程T2.
allocat就是为了给当前线程T2分配一个在T1中的Stack 对应的一个WOQ.
首先判断,T1中的 Stack还能否再分配LINK_capacity 个内存,若不能直接返回 null;
若可以,就直接 new 一个WOQ.
让我们具体看看其实现.
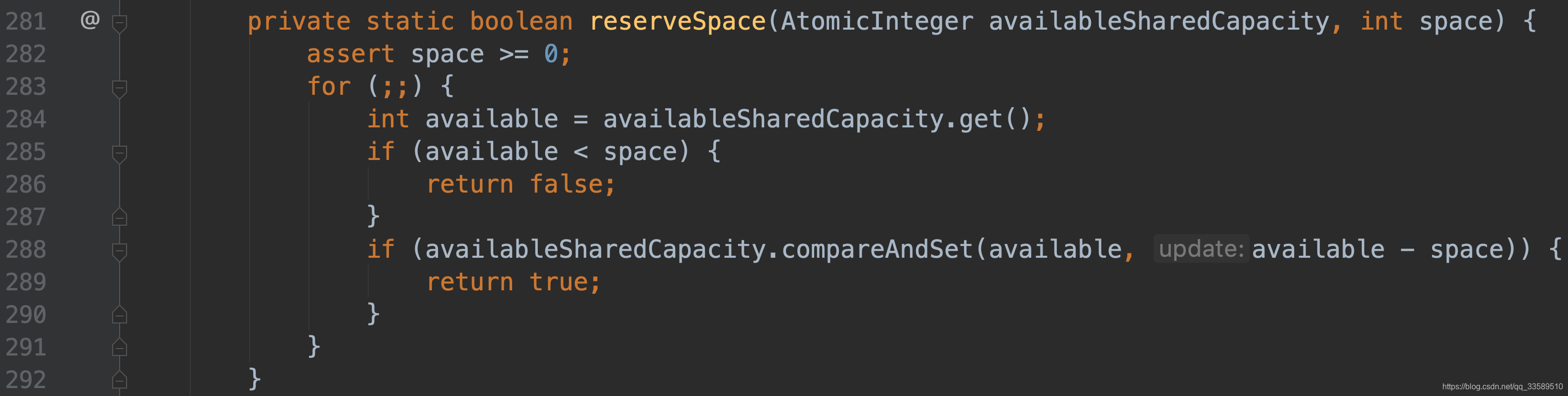
此函数意义为:该 Stack 允许外部线程给它缓存多少个对象
经过CAS操作设置该值为Stack 可为其他线程共享的回收对象的个数.


容量足够,则直接创建一个WOQ,下面来看看其数据结构.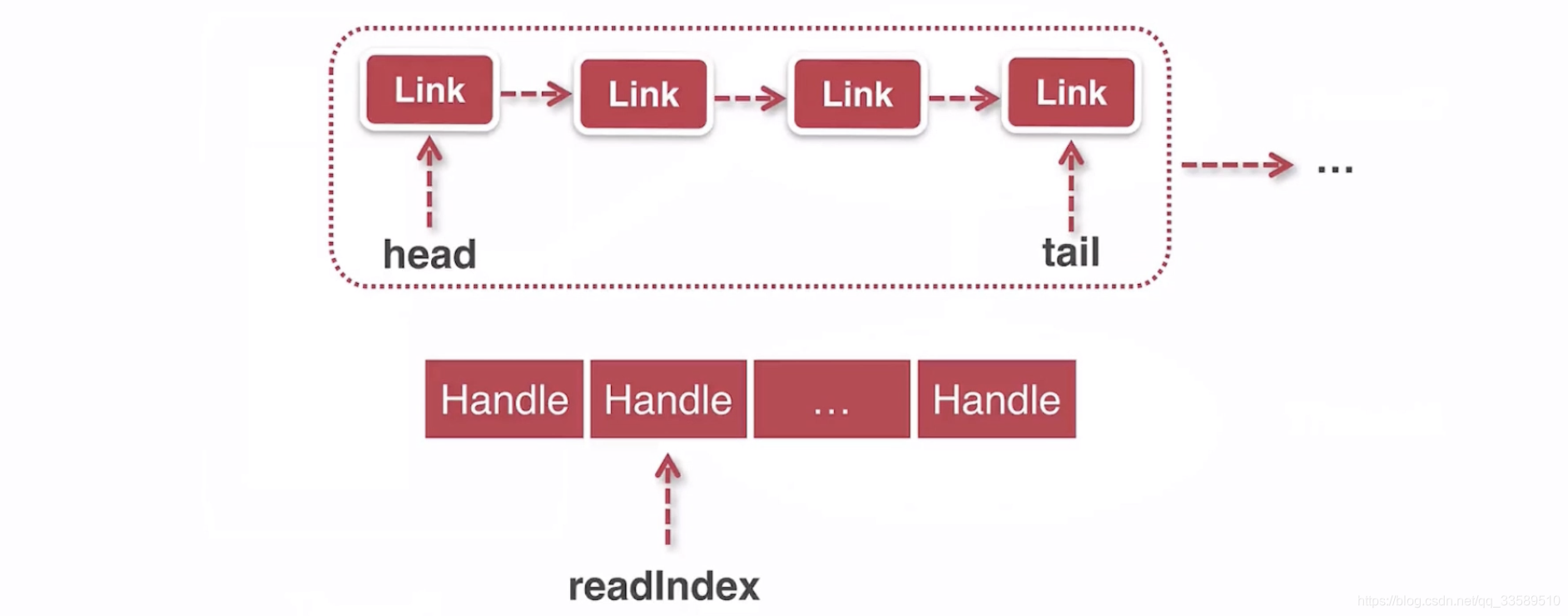
一个链表结构.将其 handle与Link 进行分离,极大地提升了性能,
因为不必判断当前T2能否回收T1的对象,而只需判断当前的L ink 中是否有空的,则可直接将 hande 塞进去.因为在前面一次性的判断过,从T1中是否能批量分配这么多对象(以减少很多操作的频率).

使用同步,将WOQ插到Stack 的头部.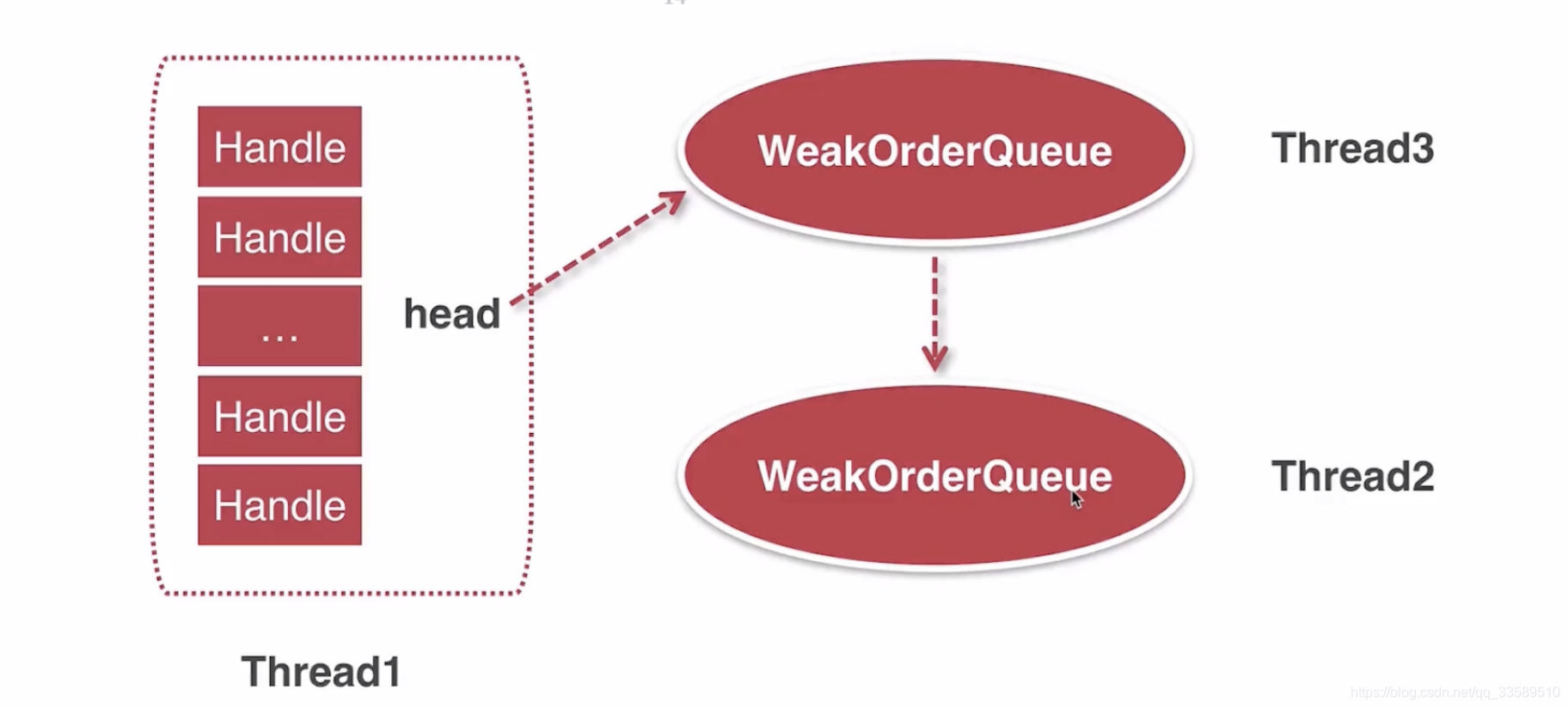
1.2.3.2.3 将对象追加到 WeakOrderQueue
-
一开始呢,就是这么创建一个WOQ,默认有16个 handle
-
T2已经拿到queue,接着就是添加元素.

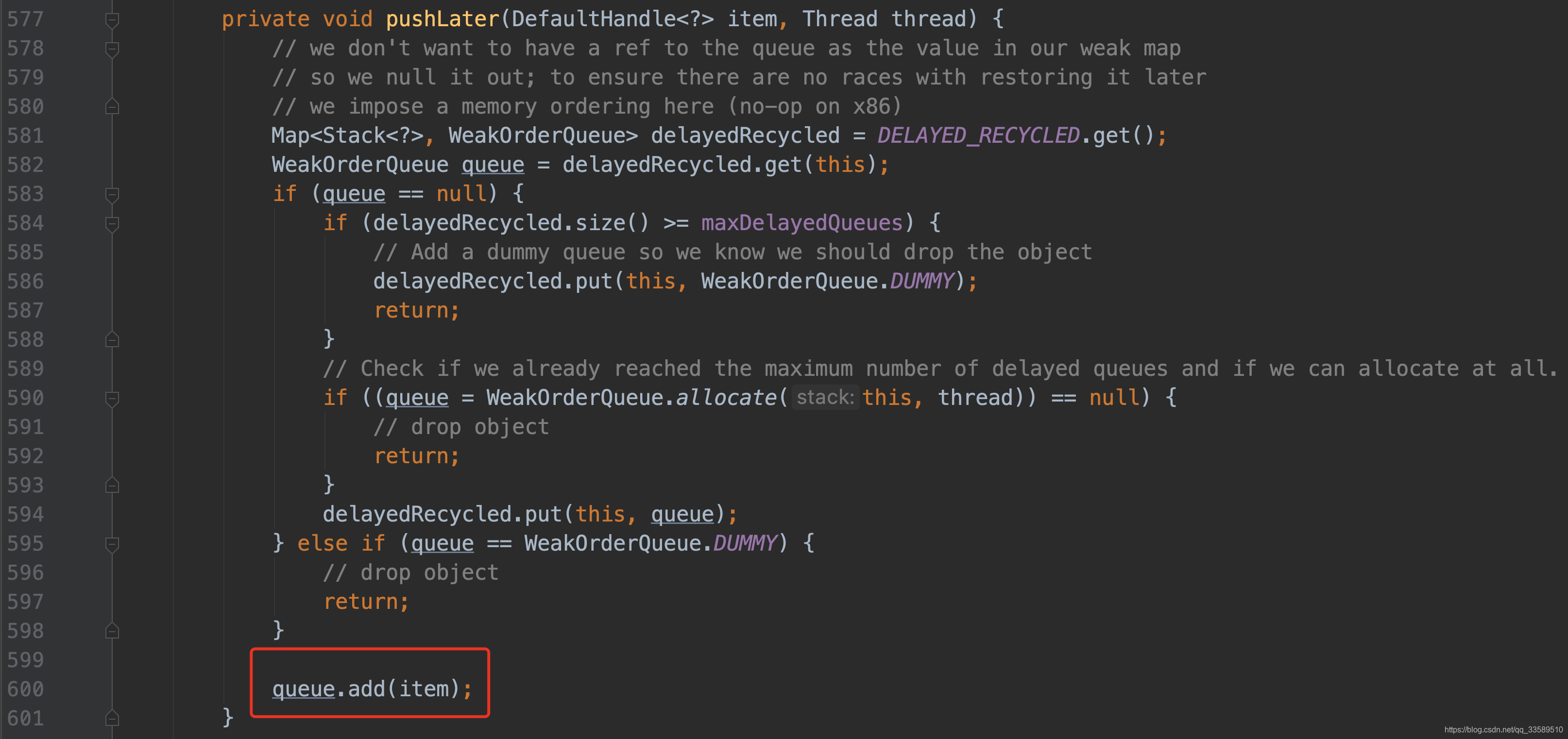
首先设置 上次回收 id.
- 该 id 为WOQ的 id,所以是以WOQ为基础的

然后拿到尾指针,获取Link 的长度,若已经等于 link_capacity,说明已经不可写了;
继续判断 想办法看看T1是否还能再分配一个Link来保存待回收的对象.
不允许,则直接丢弃;
允许,则直接创建Link并重新赋值 tail 节点.
创建完后,拿到其写指针,即 tail 的长度(0).所以 tail 节点也已经又有了足够的存储空间,将 handle 追加进去.再将该 handle 的 stack 指针重置为 null,因为已经不属于原来的 stack 了.
最后,写指针+1.
1.2.4 从 Recycler 获取对象

本节分析若当前 stack 为空

若当前线程T1去获取对象,若 stack 中有对象,则直接拿出.T1所拥有的对象即为T1拥有的 stack 中的对象,若发现其中为空,会尝试与 和T1的 stack 关联的WOQ中的 T1创建的,但是在其他线程中去回收的对象.那么,T1中对象不足,就需要在其他线程中去回收.
其中的 cusor 指针即当前所需要回收的对象
- 弹栈获取元素
- 若 size 为0,则从其他线程回收
若已经回收到则直接 return true.没有则重置两个指针,将 cusor 指向头结点,意味着准备从头开始回收.
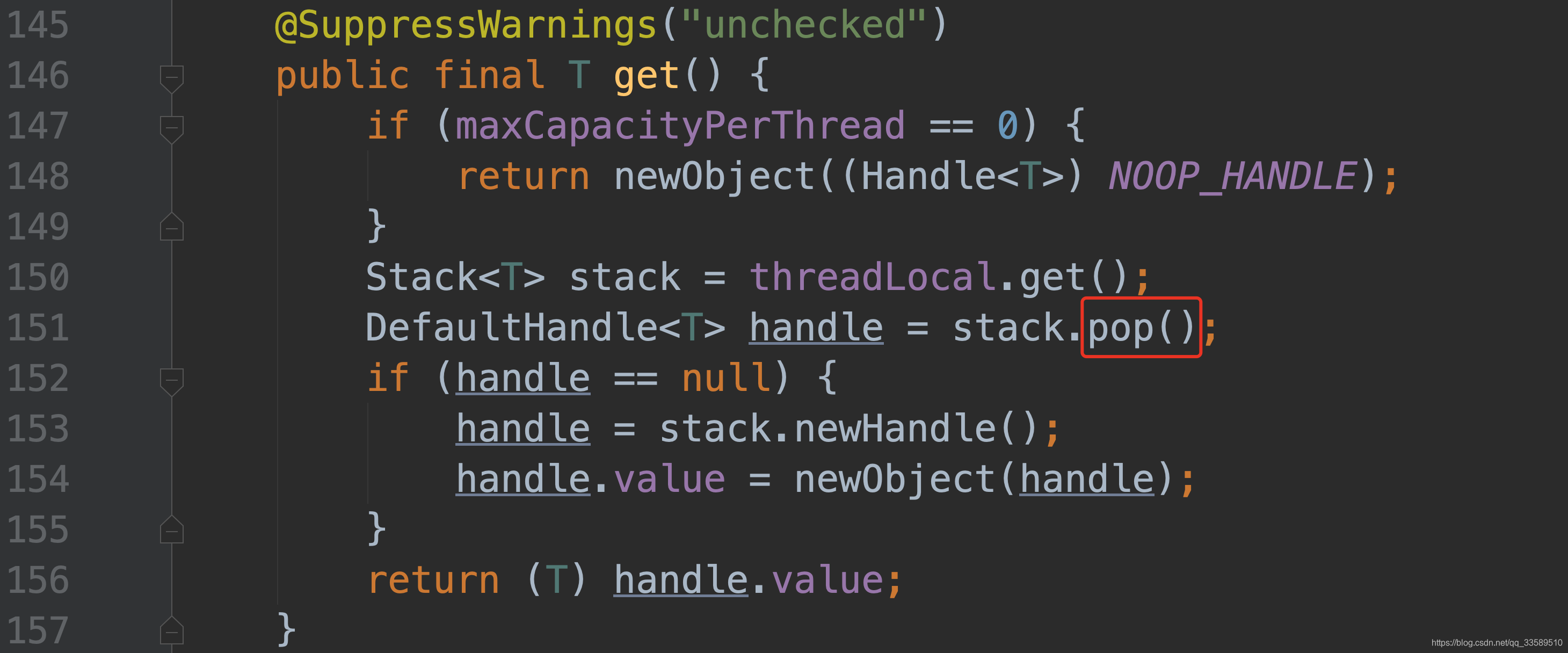


接下来具体分析这段长代码
boolean scavengeSome() {
WeakOrderQueue prev;
// 先拿到 cusor
WeakOrderQueue cursor = this.cursor;
// cusor 节点无对象
if (cursor == null) {
prev = null;
// 指向头结点
cursor = head;
// 头结点依旧为空,已经没有与之关联的WOQ,直接返回 false.
if (cursor == null) {
return false;
}
} else {
prev = this.prev;
}
boolean success = false;
// 此处 do/while 循环只为去寻找与 stack 关联的WOQ,看看到底能不能碰到一个对象.
do {
// transfer 即为了将WOQ中的对象传输到 stack 中.成功获取则结束循环!
if (cursor.transfer(this)) {
success = true;
break;
}
// 没有回收成功,则看往 cusor 的下一个节点
WeakOrderQueue next = cursor.next;
// owner 为与当前WOQ关联的一个线程(对应图中的T4)
// 为空,说明T4已经不存在!随后即,做一些善后清理工作
if (cursor.owner.get() == null) {
// If the thread associated with the queue is gone, unlink it, after
// performing a volatile read to confirm there is no data left to collect.
// We never unlink the first queue, as we don't want to synchronize on updating the head.
// 判断节点中是否还有数据
if (cursor.hasFinalData()) {
// 就需要想办法将数据传输到 stack 中
for (;;) {
if (cursor.transfer(this)) {
success = true;
} else {
break;
}
}
}
// 处理完该节点后,即将其删除,通过传统的指针的删除方法
if (prev != null) {
prev.setNext(next);
}
// T4还存活,继续看后继节点.
} else {
prev = cursor;
}
cursor = next;
// cusor 为空时,诶就结束循环啦!
} while (cursor != null && !success);
this.prev = prev;
this.cursor = cursor;
return success;
}
参考
共同学习,写下你的评论
评论加载中...
作者其他优质文章


