
写在前面
字符串的一种基本操作是子字符串查找:给定一端长度为N的文本字符串text和一个长度为M(M<N)的模式字符串pattern,在文本字符串中查找和该模式字符串相同的子字符串。在这互联网时代,字符串查找的需求在很多情景都需要,如在文本编辑器或浏览器查找某个单词、在通信内容中截取感兴趣的模式文本等等。
子字符串查找最简单的实现肯定是暴力查找:
public static int search(String text, String pattern) { int N = text.length(); int M = pattern.length(); for (int i = 0; i < N-M; i++) { int j; for (j = 0; j < M; j++) { if (text.charAt(i+j) != pattern.charAt(j)) break;
} if (j == M) return i;
} return -1;
}可以看到,暴力查找的最坏时间复杂度为O(N*M),实际应用中往往文本字符串很长(成万上亿个字符),而模式字符串很短,这样暴力算法的时间复杂度是无法接受的。
为了改进查找时间,人们发明了很多字符串查找算法,而今天的主角KMP算法(D.E.Knuth,J.H.Morris和V.R.Pratt发明,简称KMP算法)就是其中的一种。
正文
暴力查找之所以慢是因为它每次的匹配都是从头开始,并且抛弃了之前已经算好的结果,KMP算法就是从这入手:匹配失败后,已知晓的一部分文本字符串的内容信息,再利用这些内容信息避免指针回退到所有这些已知的字符之前,也即减少模式字符串与文本字符串的匹配次数以达到快速匹配的目的。
举个例子,在文本字符串 “ababaababcabcd” 查找模式字符串 “ababcab” (图1中,红色字符代表正在比较的字符):
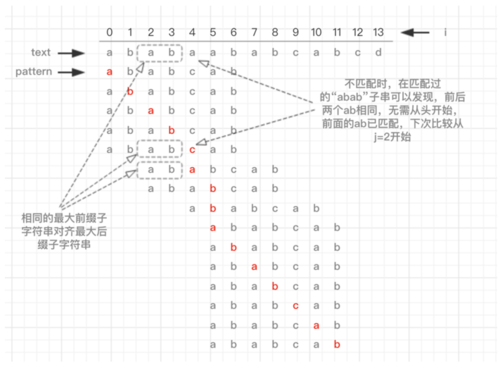
图1 KMP算法子字符串查找轨迹
在图1中,当匹配到i=4,j=4时,text的“a"不等于pattern的"c",在暴力算法中,会把j置零,重新开始比较。而KMP算法先不急把j置零,先尝试在之前匹配过的字符串中查找相同的无重叠的最大前缀子字符串和最大后缀子字符串。如“abab“,相同的无重叠的最大前缀子字符串和最大后缀子字符串为”ab“,记住,是“无重叠的”,字符串“ababa”的最大前缀子字符串和最大后缀子字符串是“a”而不是“aba”。
因为之前模式字符串的”abab“已经跟文本字符串匹配,所以文本字符串也存在”abab“,那么我们显然不需要再从头计算,把相同的最大前缀子字符串对齐最大后缀子字符串即可。如图2所示。
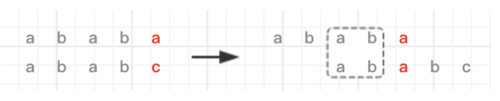
图2 KMP算法指针回退
KMP算法正是通过避免指针完成回退,从而加快匹配效率。j每次匹配失败时回退的位数取决于模式字符串,那么我们肯定不是每次匹配失败才去算j需要回退的位数(可能重复计算),我们大可在匹配前先算好模式字符串中从0到m(m在区间[0, M]内, M为模式字符串的长度)各个子字符串中的相同的无重叠的最大前缀子字符串和最大后缀子字符串,从而在匹配过程中直接使用,减少计算次数。
如字符串 “ababcab” 的从0到m各个子字符串中的相同的无重叠的最大前缀子字符串和最大后缀子字符串的长度k和索引j的关系:
| a | ab | aba | abab | ababc | ababca | ababcab | |
|---|---|---|---|---|---|---|---|
| k | 0 | 0 | 1 | 2 | 0 | 1 | 2 |
| j | -1 | -1 | 0 | 1 | -1 | 0 | 1 |
从上表的,j=k-1,因为在程序语言中,字符串的索引是从0开始的,所以减1,而j=-1,表示不存在相同的无重叠的最大前缀子字符串和最大后缀子字符串。我们在编程中,用到的是j的值。ok,我们现在来编程求出模式字符串中从0到m各个子字符串中的相同的无重叠的最大前缀子字符串和最大后缀子字符串,我们把值保存在一个next数组中。算法战5渣的我想出了一个算法:
/**
* 计算模式字符串的next数组
* @param pattern 模式字符串
* @return next数组,next数组的值对应模式字符串中从0到m各个子字符串中的相同的无重叠的最大前缀子字符串和最大后缀子字符串
*/private static int[] calNext(final String pattern) { int M = pattern.length(); int[] next = new int[M];
next[0] = -1; for (int i = 1; i < M; i++) {
next[i] = calSameSubStr(pattern.substring(0, i+1));
} return next;
}private static int calSameSubStr(final String subStr) { int M = subStr.length(); if (M < 1) return -1; int mid = M / 2; int l = 0; // 低位索引
int h = mid; // 高位索引
if (M % 2 == 1) h = mid + 1; // 长度为奇数
while (l < mid && h < M) { if (subStr.charAt(l) == subStr.charAt(h)) l++; else l = 0;
h++;
} return l-1;
}由于模式字符串一般比较简短,我这算法在一般场景应该还是能用上,但大神可不喜欢将就... KMP大神们竟然在计算next数组过程中就使用上了next数组,非常巧妙:
/**
* 计算模式字符串的next数组
* @param pattern 模式字符串
* @return next数组,next数组的值对应模式字符串中从0到m各个子字符串中的相同的无重叠的最大前缀子字符串和最大后缀子字符串
*/private static int[] calNext(final String pattern) { int M = pattern.length(); int[] next = new int[M];
next[0] = -1; // 第一个子字符串只有一个字符,肯定不存在相同前后缀子字符串
int k = -1; // k代表是相同的无重叠的最大前缀子字符串和最大后缀子字符串的长度减1,为-1表示不存在相同子串
for (int i = 1; i < M; i++) { // 这里k也充当了低位索引,i是高位索引
while(k > -1 && pattern.charAt(k+1) != pattern.charAt(i)) {
k = next[k]; // 字符不相等,k需要回溯
} if (pattern.charAt(k+1) == pattern.charAt(i)) {
k++;
}
next[i] = k;
} return next;
}大神们设计的这个算法比较难理解的是最里面的循环while,这里讲解下。k>-1,表示子串pattern[0, k]中已存在相同的无重叠的最大前缀子字符串和最大后缀子字符串,如果此时低位字符(k+1)跟高位字符(i)不匹配,k就需要回溯,回到哪里?最低位0(我写的算法就是回到0)?不是,这里显然已经用了我们上面已经讲过的思路,把指针回退到模式字符串子串[0, k]中的相同的无重叠的最大前缀子字符串和最大后缀子字符串的长度,而这个值之前已经计算过,就是next[k]。这段话可能有点难理解,理解不了的同学建议用个简短的字符串跟着程序走一遍就秒懂了。
这里求next数组已经用到上面讲解的KMP的核心思路了,后面可以看到,其实匹配时的算法跟求next数组的算法核心思路是一模一样的!这里只是模式字符串的子串充当了模式字符串,而整个模式字符串充当了文本字符串。
我们得到了next数组,每次出现不匹配时,我们就不需要每次都完成回退指针,减少了重复的比较,从而提高查找效率:
public static int search(final String text, final String pattern) { int[] next = calNext(pattern); int k = -1; int N = text.length(); int M = pattern.length(); for (int i = 0; i < N; i++) { while(k > -1 && pattern.charAt(k+1) != text.charAt(i)) { // 不匹配回溯找最大相同前后缀子字符串
k = next[k]; // 回溯方式讲解:
// 假设:
// text: ...abac...
// pattern: abad...
// i指向c时,k指向第二个a,此时k+1指向d不等于c,那么需要回溯
// 此时我们需要找的是 text[i-1-k, i-1] 子串中最大相同前后缀子字符串,
// 因为 pattern[0, k] == text[i-1-k, i-1]
// 而 pattern[0, k] 的最大相同前后子字符串之前已经算过了,是next[k]
} if (pattern.charAt(k+1) == text.charAt(i))
k++; if (k == M - 1) return i - M + 1; // 已找到匹配字符
} return -1; // 未找到匹配字符}KMP算法的时间复杂度为O(N+M),这可比暴力算法的O(NM)好多了。但KMP算法的效率依赖于模式字符串的字符重复度,如果字符无重复时,KMP算法甚至比暴力算法效率更低。
至此,KMP字符串查找算法已经分析完了,其实算是一种比较简单的算法,学习起来很快就能搞懂~
写在后面
KMP算法要求模式字符串具有重复度高的字符才能发挥强大的功力,但实际应用中这种场景并不多,学了似乎没什么用?其实我在学习了一些算法后发现,算法总是有利也有弊,牺牲时间换空间,或者牺牲空间换时间,总也不能十全十美,我们需要的是厚积薄发,在实际应用中遇到类似的场景,能想到有这么一种思路可以解决问题。其次,学算法最重要的是学思路而不是实现,如快排,你懂它的核心思路就行了,没必要死记硬背,实际工作中也不需要你自己写一遍,因为系统早已集成好了。而快排的分而治之的思路非常有用,这在工作中经常遇到,当你遇到这情景时,你能回忆起快排的分而治之的思路;“哦!好像这里可以用快排的分而治之的思路来解决喔!”,然后再去重看快排的具体实现,看下能不能借鉴下,我想,学习快排这算法就是没白费了~
而KMP算法的求next数组的方案和指针回退的方式都非常有学习价值,值得细细品味,应当收入囊中,期待下次的“哦!这种情景我有办法解决!”的顿悟。
作者:安卓大叔
链接:https://www.jianshu.com/p/f65cae7e00ef
共同学习,写下你的评论
评论加载中...
作者其他优质文章



