
一、private修饰的方法可以通过反射访问,那么private的意义是什么
主要抓住两点:
- Java的private修饰符并不是为了绝对安全性设计的,更多是对用户常规使用Java的一种 约束;
- 从外部对对象进行常规调用时,能够看到清晰的类结构
二、Java类初始化顺序
- 基类静态代码块,基类静态成员字段(并列优先级,按照代码中出现的先后顺序执行,且只有第一次加载时执行)
- 派生类静态代码块,派生类静态成员字段(并列优先级,按照代码中出现的先后顺序执行,且只有第一次加载时执行)
- 基类普通代码块,基类普通成员字段(并列优点级,按代码中出现先后顺序执行)
- 基类构造函数
- 派生类普通代码块,派生类普通成员字段(并列优点级,按代码中出现先后顺序执行)
- 派生类构造函数
三、对方法区和永久区的理解以及它们之间的关系
方法区是jvm规范里要求的,永久区是Hotspot虚拟机对方法区的具体实现。前者是规范,后者是实现方式。jdk1.8作了改变。
四、一个Java文件有3个类,编译后有几个class文件
3个。文件中有几个类,编译后就有几个class文件。
五、局部变量使用前需要显式地赋值,否则编译通过不了,为什么这么设计?
- 成员变量是可以不经初始化的,在类加载过程的准备阶段即可给它赋予默认值,但局部变量使用前需要显式赋予初始值。javac足够有能力推断出局部变量并初始化默认值,然而它并没有这样做。
- 对于成员变量而言,其赋值和取值访问的先后顺序具有不确定性,对于成员变量可以在一个方法调用前赋值,也可以在方法调用后进行,这是运行时发生的,编译器决定不了,交给jvm去做比较合适。
- 而对于局部变量而言,其赋值和取值访问顺序是确定的。这样设计是一种约束,尽最大程度减少使用者犯错的可能(假使局部变量可以使用默认值,开发者可能无意间忘记赋值,进而导致不可预期的情况出现)。
六、ReadWriteLock读写之间互斥吗
ReadWriteRock 读写锁,使用场景可分为读/读、读/写、写/写,除了读和读之间是共享的,其它都是互斥的。怎样实现互斥锁和同步锁, 涉及到AQS,CAS。
七、AQS和CAS原理
抽象队列同步器AQS(AbstractQueuedSychronizer),如果说java.util.concurrent的基础是CAS的话,那么AQS就是整个Java并发包的核心了,ReentrantLock、CountDownLatch、Semaphore等都用到了它。AQS实际上以双向队列的形式连接所有的Entry,比方说ReentrantLock,所有等待的线程都被放在一个Entry中并连成双向队列,前面一个线程使用ReentrantLock好了,则双向队列实际上的第一个Entry开始运行。AQS定义了对双向队列所有的操作,而只开放了tryLock和tryRelease方法给开发者使用,开发者可以根据自己的实现重写tryLock和tryRelease方法,以实现自己的并发功能。
比较并替换CAS(Compare and Swap),假设有三个操作数:内存值V、旧的预期值A、要修改的值B,当且仅当预期值A和内存值V相同时,才会将内存值修改为B并返回true,否则什么都不做并返回false,整个比较并替换的操作是一个原子操作。CAS一定要volatile变量配合,这样才能保证每次拿到的变量是主内存中最新的相应值,否则旧的预期值A对某条线程来说,永远是一个不会变的值A,只要某次CAS操作失败,下面永远都不可能成功。
CAS虽然比较高效的解决了原子操作问题,但仍存在三大问题。
- 循环时间长开销很大。
- 只能保证一个共享变量的原子操作。
- ABA问题。
八、Semaphore拿到执行权的线程之间是否互斥
Semaphore拿到执行权的线程之间是否互斥,Semaphore、CountDownLatch、CyclicBarrier、Exchanger 为Java并发编程的4个辅助类,面试中常问的 CountDownLatch CyclicBarrier之间的区别,面试者肯定是经常碰到的, 所以问起来意义不大,Semaphore问的相对少一些,有些知识点如果没有使用过还是会忽略,Semaphore可有多把锁,可允许多个线程同时拥有执行权,这些有执行权的线程如并发访问同一对象,会产生线程安全问题。
九、B树和B+树是解决什么样的问题的,怎样演化过来,之间区别
B树和B+树,这题既问mysql索引的实现原理,也问数据结构基础。首先从二叉树说起,因为会产生退化现象,提出了平衡二叉树;再提出怎样让每一层放的节点多一些来减少遍历高度,引申出m叉树,m叉搜索树同样会有退化现象,引出m叉平衡树,也就是B树。这时候每个节点既放了key也放了value,怎样使每个节点放尽可能多的key值,以减少遍历高度呢(访问磁盘次数),可以将每个节点只放key值,将value值放在叶子结点,在叶子结点的value值增加指向相邻节点指针,这就是优化后的B+树。然后谈谈数据库索引失效的情况,为什么给离散度低的字段(如性别)建立索引是不可取的,查询数据反而更慢,如果将离散度高的字段和性别建立联合索引会怎样,有什么需要注意的?
十、mysql给离散度低的字段建立索引会出现什么问题,具体说下原因
先上结论:重复性较强的字段,不适合添加索引。mysql给离散度低的字段,比如性别设置索引,再以性别作为条件进行查询反而会更慢。
一个表可能会涉及两个数据结构(文件),一个是表本身,存放表中的数据,另一个是索引。索引是什么?它就是把一个或几个字段(组合索引)按规律排列起来,再附上该字段所在行数据的物理地址(位于表中)。比如我们有个字段是年龄,如果要选取某个年龄段的所有行,那么一般情况下可能需要进行一次全表扫描。但如果以这个年龄段建个索引,那么索引中会按年龄值根据特定数据结构建一个排列,这样在索引中就能迅速定位,不需要进行全表扫描。为什么性别不适合建索引呢?因为访问索引需要付出额外的IO开销,从索引中拿到的只是地址,要想真正访问到数据还是要对表进行一次IO。假如你要从表的100万行数据中取几个数据,那么利用索引迅速定位,访问索引的这IO开销就非常值了。但如果是从100万行数据中取50万行数据,就比如性别字段,那你相对需要访问50万次索引,再访问50万次表,加起来的开销并不会比直接对表进行一次完整扫描小。
当然如果把性别字段设为表的聚集索引,那么就肯定能加快大约一半该字段的查询速度了。聚集索引指的是表本身数据按哪个字段的值来进行排序。因此,聚集索引只能有一个,而且使用聚集索引不会付出额外IO开销。当然你得能舍得把聚集索引这么宝贵资源用到性别字段上。
可以根据业务场景需要,将性别和其它字段建立联合索引,比如时间戳,但是建立索引记得把时间戳字段放在性别前面。
十一、写一个生产者消费者模式
生产者消费者模式,synchronized锁住一个LinkedList,一个生产者,只要队列不满,生产后往里放,一个消费者只要队列不空,向外取,两者通过wait()和notify()进行协调,写好了会问怎样提高效率,最后会聊一聊消息队列设计精要思想及其使用。
十二、写一个死锁
死锁的四个条件:互斥条件、不可剥夺条件、请求与保持条件、循环等待条件。思想为:定义两个ArrayList,将他们都加上锁A、B,线程1、2。1拿住了锁A ,请求锁B;2拿住了锁B请求锁A,在等待对方释放锁的过程中谁也不让出已获得的锁。
十三、cpu 100%怎样定位
- 先用top定位最耗cpu的java进程 例如: 12430
工具:top或者 htop(高级)
方法:top -c 显示进程运行详细列表
键入 P (大写P),按照cpu进行排序 - 然后用top -p 12430 -H 定位到最耗cpu的线程 的ID 例如:12483
工具:top
方法:top -Hp 1865 ,显示一个进程的线程运行信息列表
键入P (大写p),线程按照CPU使用率排序 - 把第二步定位的线程ID,转成16进制,printf “%x\n” 12483 得到 :30c3
工具:printf
方法:printf “%x\n” 2747 - 从jstack 输出的线程快照中找到线程的对堆栈信息 jstack 12430 |grep 30c3 -A 60 |less
工具:pstack/jstack/grep
方法:jstack 10765 | grep ‘0x2a34’ -C5 --color`
十四、int a = 1; 是原子性操作吗?
是。
十五、可以用for循环直接删除ArrayList的特定元素吗?可能会出现什么问题?怎样解决?
for循环直接删除ArrayList中的特定元素是错的,不同的for循环会发生不同的错误,泛型for会抛出 ConcurrentModificationException,普通的for想要删除集合中重复且连续的元素,只能删除第一个。
错误原因:打开JDK的ArrayList源码,看下ArrayList中的remove方法(注意ArrayList中的remove有两个同名方法,只是入参不同,这里看的是入参为Object的remove方法)是怎么实现的,一般情况下程序的执行路径会走到else路径下最终调用faseRemove方法,会执行System.arraycopy方法,导致删除元素时涉及到数组元素的移动。针对普通for循环的错误写法,在遍历第一个字符串b时因为符合删除条件,所以将该元素从数组中删除,并且将后一个元素移动(也就是第二个字符串b)至当前位置,导致下一次循环遍历时后一个字符串b并没有遍历到,所以无法删除。针对这种情况可以倒序删除的方式来避免。
解决方案:用 Iterator。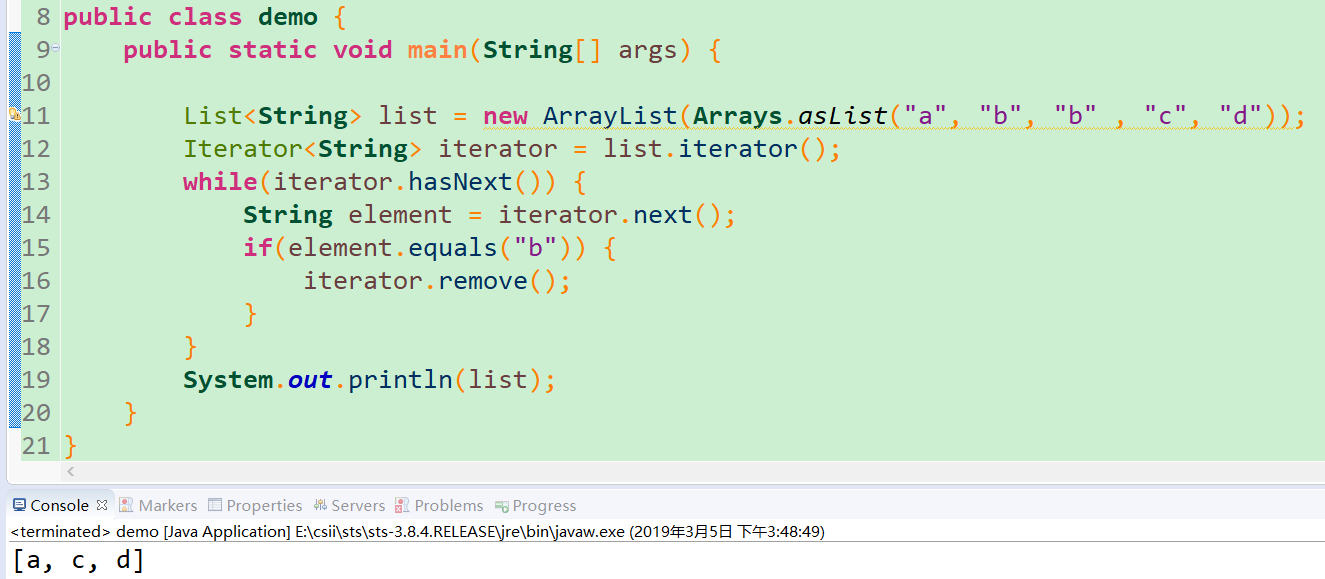
扩展: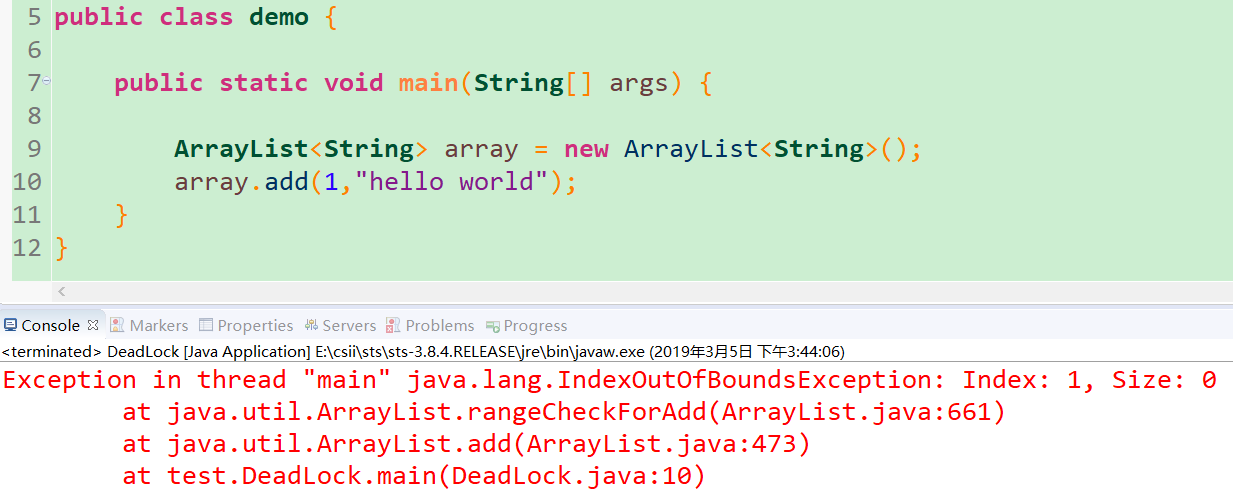
十六、新的任务提交到线程池,线程池是怎样处理
第一步 :线程池判断核心线程池里的线程是否都在执行任务。如果不是,则创建一个新的工作线程来执行任务。如果核心线程池里的线程都在执行任务,则执行第二步。
第二步 :线程池判断工作队列是否已经满。如果工作队列没有满,则将新提交的任务存储在这个工作队列里进行等待。如果工作队列满了,则执行第三步。
第三步 :线程池判断线程池的线程是否都处于工作状态。如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务。
十七、synchronized底层实现原理
synchronized (this)原理:涉及两条指令:monitorenter,monitorexit;再说同步方法,从同步方法反编译的结果来看,方法的同步并没有通过指令monitorenter和monitorexit来实现,相对于普通方法,其常量池中多了ACC_SYNCHRONIZED标示符。
JVM就是根据该标示符来实现方法的同步的:当方法被调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同一个monitor对象。
这个问题会接着追问:java对象头信息,偏向锁,轻量锁,重量级锁及其他们相互间转化。
十八、volatile作用,指令重排相关
理解volatile关键字的作用的前提是要理解Java内存模型,volatile关键字的作用主要有两点:
多线程主要围绕可见性和原子性两个特性而展开,使用volatile关键字修饰的变量,保证了其在多线程之间的可见性,即每次读取到volatile变量,一定是最新的数据
代码底层执行不像我们看到的高级语言—-Java程序这么简单,它的执行是Java代码–>字节码–>根据字节码执行对应的C/C++代码–>C/C++代码被编译成汇编语言–>和硬件电路交互,现实中,为了获取更好的性能JVM可能会对指令进行重排序,多线程下可能会出现一些意想不到的问题。使用volatile则会对禁止语义重排序,当然这也一定程度上降低了代码执行效率
从实践角度而言,volatile的一个重要作用就是和CAS结合,保证了原子性,详细的可以参见java.util.concurrent.atomic包下的类,比如AtomicInteger。
十九、AOP和IOC原理
AOP 和 IOC是Spring精华部分,AOP可以看做是对OOP的补充,对代码进行横向的扩展,通过代理模式实现,代理模式有静态代理,动态代理,Spring利用的是动态代理,在程序运行过程中将增强代码织入原代码中。IOC是控制反转,将对象的控制权交给Spring框架,用户需要使用对象无需创建,直接使用即可。AOP和IOC最可贵的是它们的思想。
二十、Spring怎样解决循环依赖的问题
什么是循环依赖,怎样检测出循环依赖,Spring循环依赖有几种方式,使用基于setter属性的循环依赖为什么不会出现问题,接下来会问:Bean的生命周期。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


