
基于OpenCV和Keras的人脸识别系列手记:
项目完整代码参见Github仓库。
本篇手记是上面这一系列的第八篇。
在系列上一篇也就是第七篇的最后我提到如果训练数据量比较大,在预测阶段KNN算法的时间复杂度就会比较高。
那么有没有更合适的算法呢?其实答案就在上篇手记最后的那张图里,这里我再把它放出来: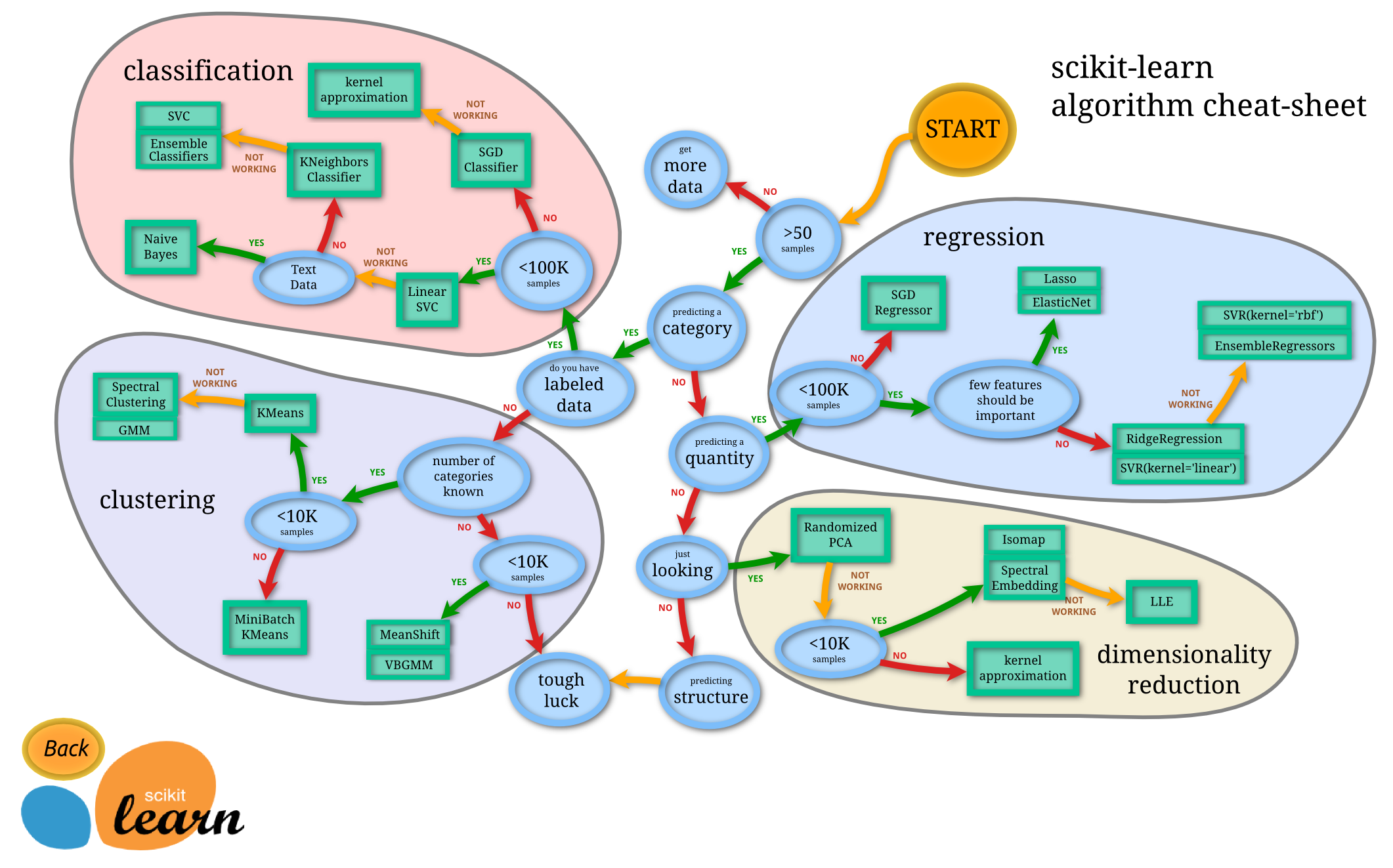
这张图是Scikit-learn官方教程里给出的机器学习算法选择指导,从图中可以看到,对于分类问题,当样本数量小于10万的时候可以优先考虑Linear SVC,也就是线性支持向量分类器,这就引出了支持向量机(SVM)算法,这篇手记里就要用SVM替换KNN,并对两者的性能进行简单的比较。另外,从这幅图中还可以看到,当样本数量大于10万的时候才用SGD Classifier,因此系列第四、五篇中直接用少量的数据训练一个带有大量参数的CNN模型其实是不恰当的,这也是为什么要写系列六、七、八篇的原因。
重新划分程序文件并用Pickle保存特征向量
在开始应用SVM算法之前,我首先要从工程角度对程序进行一点改进。之前训练KNN模型的时候,每次改变参数后再运行都要将图片加载到内存,然后通过facenet计算出图片的128维特征向量,而计算特征向量的这一步其实是比较耗时的,现在再训练SVM算法,可能也需要调整参数反复训练,每次调整过参数重新训练SVM模型都重复计算特征向量就很浪费时间。
好在Python 3提供了一个Pickle模块,可以用来对对象数据结构进行序列化和反序列化操作。
序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换成可取用格式(例如存成文件,存于缓冲,或经由网络中发送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。
用Pickle可以把算好的特征向量保存到数据文件里,需要训练KNN、SVM或其他分类模型的时候,就只用从数据文件加载特征向量,这比加载图片再计算特征向量要快得多。
另一方面,之前的程序文件在功能上分得不够细,face_knn_classifier.py这个文件把加载图片并用facenet提取128维特征向量和训练KNN模型两部分代码都放到了一起,这样导致单个文件过长,而对于训练KNN或SVM模型的功能来说,用facenet提取特征向量其实属于准备数据的过程,把准备数据和训练模型的功能分开有利于对不同的功能模块分别修改,而且加载facenet模型和计算特征向量的过程其实比较慢,不应该每次训练KNN或SVM模型的时候都重复运行这一部分代码,现在用了Pickle保存特征向量,正好把提取特征向量准备数据这一部分功能单独拿出来放到另一个文件里。
因此我重新进行了文件划分,最终的全部程序文件具体如下:
save_face_image.py:用来采集人脸图片的程序,和之前一样;feature_extract.py:加载facenet模型,从采集的人脸图片提取128维特征向量并用Pickle保存到文件,当需要修改数据(比如人脸图片的增删改)的时候就只需单独运行此程序;face_classifier.py:加载保存的128维特征向量,训练KNN或者SVM分类器,调整模型参数进行迭代的时候就只需单独运行此程序;face_recognition.py:加载KNN或者SVM分类器模型,实现人脸识别,后续我增加了人脸分类,所以对这个文件有所改动,会在后面提到;logs.py:日志模块,在后续比较性能的时候将信息记录到日志文件并附带上日期和时间,这样比将信息直接打印到console控制台再复制粘贴到文件方便多了,后面详细介绍;
先来看feature_extract.py,还是先引入所需的模块:
import os
import numpy as np
import cv2
from keras.models import load_model
import pickle
指定输入到facenet模型的图像大小,然后定义resize_image和load_dataset函数,和之前的load_face_dataset.py一样:
IMAGE_SIZE = 160 # 指定图像大小
# 按指定图像大小调整尺寸
def resize_image(image, height = IMAGE_SIZE, width = IMAGE_SIZE):
top, bottom, left, right = (0,0,0,0)
# 获取图片尺寸
h, w, _ = image.shape
# 对于长宽不等的图片,找到最长的一边
longest_edge = max(h,w)
# 计算短边需要增加多少像素宽度才能与长边等长(相当于padding,长边的padding为0,短边才会有padding)
if h < longest_edge:
dh = longest_edge - h
top = dh // 2
bottom = dh - top
elif w < longest_edge:
dw = longest_edge - w
left = dw // 2
right = dw - left
else:
pass # pass是空语句,是为了保持程序结构的完整性。pass不做任何事情,一般用做占位语句。
# RGB颜色
BLACK = [0,0,0]
# 给图片增加padding,使图片长、宽相等
# top, bottom, left, right分别是各个边界的宽度,cv2.BORDER_CONSTANT是一种border type,表示用相同的颜色填充
constant = cv2.copyMakeBorder(image, top, bottom, left, right, cv2.BORDER_CONSTANT, value = BLACK)
# 调整图像大小并返回图像,目的是减少计算量和内存占用,提升训练速度
return cv2.resize(constant, (height, width))
def load_dataset(data_dir):
images = [] # 用来存放图片
labels = [] # 用来存放类别标签
sample_nums = [] # 用来存放不同类别的人脸数据量
classes = os.listdir(data_dir) # 通过数据集路径下文件夹的数量得到所有类别
category = 0 # 分类标签计数
for person in classes: # person是不同分类人脸的文件夹名
person_dir = os.path.join(data_dir, person) # person_dir是某一分类人脸的路径名
person_pics = os.listdir(person_dir) # 某一类人脸路径下的全部人脸数据文件
for face in person_pics: # face是某一分类文件夹下人脸图片数据的文件名
img = cv2.imread(os.path.join(person_dir, face)) # 通过os.path.join得到人脸图片的绝对路径
if img is None: # 遇到部分数据有点问题,报错'NoneType' object has no attribute 'shape'
pass
else:
img = resize_image(img, IMAGE_SIZE, IMAGE_SIZE)
images.append(img) # 得到某一分类下的所有图片
labels.append(category) # 给某一分类下的所有图片赋予分类标签值
sample_nums.append(len(person_pics)) # 得到某一分类下的样本量
category += 1
images = np.array(images)
labels = np.array(labels)
print("Number of classes: ", len(classes)) # 输出分类数
for i in range(len(sample_nums)):
print("Number of the sample of class ", i, ": ", sample_nums[i]) # 输出每个类别的样本量
return images, labels
加载facenet模型,定义img_to_encoding函数提取特征向量:
# 建立facenet模型
facenet = load_model('./model/facenet_keras.h5') # bad marshal data (unknown type code),用Python2实现的模型时会报这个错
def img_to_encoding(images, model):
# 这里image的格式就是opencv读入后的格式
images = images[...,::-1] # Color image loaded by OpenCV is in BGR mode. But Matplotlib displays in RGB mode. 这里的操作实际是对channel这一dim进行reverse,从BGR转换为RGB
images = np.around(images/255.0, decimals=12) # np.around是四舍五入,其中decimals是保留的小数位数,这里进行了归一化
# https://stackoverflow.com/questions/44972565/what-is-the-difference-between-the-predict-and-predict-on-batch-methods-of-a-ker
if images.shape[0] > 1:
embedding = model.predict(images, batch_size = 256) # predict是对多个batch进行预测,这里的128是尝试后得出的内存能承受的最大值
else:
embedding = model.predict_on_batch(images) # predict_on_batch是对单个batch进行预测
# 报错,operands could not be broadcast together with shapes (2249,128) (2249,),因此要加上keepdims = True
embedding = embedding / np.linalg.norm(embedding, axis = 1, keepdims = True) # 注意这个项目里用的keras实现的facenet模型没有l2_norm,因此要在这里加上
return embedding
接着就是提取特征向量并用Pickle保存了:
if __name__ == "__main__":
images, labels = load_dataset('./dataset_image/')
# 生成128维特征向量
X_embeddings = img_to_encoding(images, facenet) # 考虑这里分批执行,否则可能内存不够,这里在img_to_encoding函数里通过predict的batch_size参数实现
# pickle保存数据
file_embeddings = open('./dataset_pkl/embeddings.pkl', 'wb')
pickle.dump(X_embeddings, file_embeddings)
file_embeddings.close()
file_labels = open('./dataset_pkl/labels.pkl', 'wb')
pickle.dump(labels, file_labels)
file_labels.close
上面的代码里用Python的open方法创建了一个pkl格式文件对象,然后只需调用Pickle模块的dump方法将特征向量保存到文件里。需要注意的是因为存储的是特征向量数据而不是文本,所以在文件打开模式上选择的是wb(如果是文本应该选择w),也就是:
以二进制格式打开一个文件只用于写入
另外对文件操作完成后一定要调用close()方法关闭文件对象。
运行这个程序,得到embeddings.pkl和labels.pkl,人脸特征向量和分类标签数据就准备好了。
训练一个简单的SVM分类器实现人脸分类和识别
SVM算法相对KNN算法要复杂,不过,如果掌握了高等数学的知识,理解起来并不困难,我简单总结一下我学习之后的理解:
- SVM要解决的基本问题:在二分类问题中,可能有多个能把两类数据点完全分开的超平面,SVM要在这些超平面中,找到最佳的分类超平面;
- 最佳分类超平面到两类数据中距离这个超平面最近的点距离相等且距离最大,这个距离的两倍是分类间隔,具有最大分类间隔的超平面就是SVM要找的最佳超平面;
- 最佳超平面两侧距离最近的这些数据点在坐标系中对应的向量就是支持向量,可以看到最佳分类超平面只和支持向量有关,支持向量机就是由支持向量决定的最佳分类超平面。
因此,SVM是一个最优化问题:
- 优化对象:最佳分类超平面
- 优化目标:使分类间隔最大
- 限制条件:所有数据点到最佳超平面的距离都大于等于最大分类间隔的一半
字面上的理解就是这么简短,但SVM背后的数学推导相对KNN要复杂,幸好有scikit-learn这样的机器学习库,要使用scikit-learn实现SVM,只要在理解算法的基础上知道有哪些超参数需要调节以及如何调节即可。我根据自己的学习写了一篇笔记,只用到少量的数学公式,帮助理解和记忆:SVM简化理解。
有了人脸特征向量数据,也了解了SVM算法的基本原理,就可以开始训练SVM分类器。思路和之前训练KNN分类器一样,加载数据,然后定义并训练SVM分类器模型,这一部分功能我放到了face_classifier.py文件里,先加载所需模块:
import numpy as np
import pickle
import time
from feature_extract import resize_image, facenet, img_to_encoding
from sklearn.model_selection import cross_val_score, ShuffleSplit, KFold, learning_curve
from sklearn.neighbors import KNeighborsClassifier
from sklearn.externals import joblib
import matplotlib.pyplot as plt
from sklearn.svm import SVC
import h5py
import cv2
接着定义Dataset类,实现加载特征向量和分类标签数据集的功能:
class Dataset:
# http://www.runoob.com/python3/python3-class.html
# 很多类都倾向于将对象创建为有初始状态的。
# 因此类可能会定义一个名为 __init__() 的特殊方法(构造方法),类定义了 __init__() 方法的话,类的实例化操作会自动调用 __init__() 方法。
# __init__() 方法可以有参数,参数通过 __init__() 传递到类的实例化操作上,比如下面的参数path_name。
# 类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
# self 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类。
def __init__(self, path_name):
# 训练集
self.X_train = None
self.y_train = None
# 数据集加载路径
self.path_name = path_name
# 加载数据集
def load(self):
# 加载数据集到内存,pickle方式
file_embeddings = open(self.path_name + 'embeddings.pkl', 'rb')
# 加载128维特征向量
X_embeddings = pickle.load(file_embeddings) # 考虑这里分批执行,否则可能内存不够,这里在img_to_encoding函数里通过predict的batch_size参数实现
file_embeddings.close()
file_labels = open(self.path_name + 'labels.pkl', 'rb')
labels = pickle.load(file_labels)
file_labels.close()
# 输出训练数据集的维数和数量
print('X_train shape', X_embeddings.shape)
print('y_train shape', labels.shape)
print(X_embeddings.shape[0], 'train samples')
# 这里对X_train就不再进一步normalization了,因为已经在facenet里有了l2_norm
self.X_train = X_embeddings
self.y_train = labels
然后定义svm_Model类,训练SVM模型。
我用scikit-learn中的SVC类来实现SVM分类器,注意在使用SVM算法的时候,通常先采用线性核,如果线性核效果不好,才进一步尝试其他非线性核。SVC方法用kernel参数控制核函数的类型,默认是rbf高斯核,这里改成linear即可。
之前用KNN的时候我只分了两类,这次我分三类,分别是我、女朋友和其他人(其他人的数据还是来自LFW数据集)。从前面SVM算法的简单介绍可以看到,SVM本身是解决二分类问题的,要用SVM来解决多分类的问题,也要用多次二分类来间接实现,主要有两种方案:
- one-vs-the-rest,训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。对新数据分类是就用这k个SVM分别推断其类别,结果中预测概率最大的类别就是分类结果,这种方式所用的SVM分类器个数是k个,较少,但由于是把剩余所有样本都归为一类,因此数据不平衡的问题会比较大;
- one-vs-one,训练时在每两类样本之间构造一个SVM,这样大大减轻了数据不平衡的问题,不过k个类别的样本就需要设计k(k-1)/2个SVM,当类别比较多的时候比one-vs-the-rest计算量要大不少,对新数据分类的时候,用k(k-1)/2个SVM对其计算分类,并对k个分类计数,最终也是最多数的类别就是分类结果。
这里我遵循scikit-learn官方文档的说明,选择第二种方案,也就是one-vs-one,因此decision_function_shape参数设为ovo。SVC类还有一个参数是C,是SVM优化目标函数里的错误项惩罚系数,通常取1,也就是不允许数据有错误的分类,这样一来,如果数据中有噪声,就容易过拟合,因此在训练模型的时候要验证是否存在过拟合的问题。scikit-learn提供了学习曲线learning_curve方法,通过对训练数据集从少到多的多个子集进行k折交叉验证并画出其准确度曲线来检查是否过拟合,具体代码如下:
class svm_Model:
def __init__(self):
self.model = None
def build_model(self):
self.model = SVC(kernel = 'linear', decision_function_shape = 'ovo')
def train(self, dataset):
self.model.fit(dataset.X_train, dataset.y_train)
# https://morvanzhou.github.io/tutorials/machine-learning/sklearn/3-3-cross-validation2/
cv = ShuffleSplit(random_state = 0)
train_sizes, train_accuracies, test_accuracies = learning_curve(self.model, dataset.X_train, dataset.y_train, cv = cv, scoring = 'accuracy', train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
train_accuracies_mean = np.mean(train_accuracies, axis = 1)
test_accuracies_mean = np.mean(test_accuracies, axis = 1)
print('train accuracies: ', train_accuracies_mean)
print('test accuracies: ', test_accuracies_mean)
plt.plot(train_sizes, train_accuracies_mean, 'o-', color="r", label="Training")
plt.plot(train_sizes, test_accuracies_mean, 'o-', color="g", label="Cross-validation")
plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
def save_model(self, file_path):
joblib.dump(self.model, file_path)
def load_model(self, file_path):
self.model = joblib.load(file_path)
def predict(self, image):
image = resize_image(image)
image_embedding = img_to_encoding(np.array([image]), facenet)
start = time.time()
label = self.model.predict(image_embedding) # predict方法返回值是array of shape [n_samples],因此下面要用label[0]从array中取得数值,https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html#sklearn.neighbors.KNeighborsClassifier.predict
log("Predicting one face using svm model took {} seconds.".format(time.time() - start))
return label[0]
接着还是训练并持久化模型的代码:
if __name__ == "__main__":
# pickle方式加载数据
dataset = Dataset('./dataset_pkl/')
dataset.load()
model = svm_Model()
model.build_model()
model.train(dataset)
model.save_model('./model/svm_classifier.model')
运行face_classifier.py程序,画出的学习曲线如下,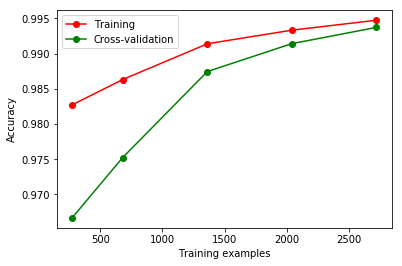
从曲线图可以看到,当只用十分之一的训练数据训练的时候,训练准确率比测试准确率大比较多,出随着训练数据量的增大,训练准确率和测试准确率都在提升,且越来越接近,最终用全部数据集训练并10折交叉验证的结果是:
训练准确率——0.99474651
测试准确率——0.99372937
二者的差距已经很小,说明模型的泛化能力有明显提升,过拟合问题大大减弱。
训练好了SVM分类器,就可以和之前一样实现人脸识别,这次我分三类,分别是“我”、“女友”和“其他人”。对face_recognition.py我也做了一些小小的改进:
- 直接读取人脸图片数据集路径下的文件夹名列表,方便人脸类别的扩展
- 将用矩形框标记人脸并显示身份文字的功能单独拿出来写到一个函数
mark_face里,具体如下:
from keras import backend as K
K.set_image_data_format('channels_first')
import cv2
#from face_classifier import Knn_Model
from face_classifier import svm_Model
#model = Knn_Model()
model = svm_Model()
#model.load_model('./model/knn_classifier.model')
model.load_model('./model/svm_classifier.model')
# Face Recognition
#框住人脸的矩形边框颜色
cv2.namedWindow('Detecting your face.') # 创建窗口
color = (0, 255, 0)
classifier = cv2.CascadeClassifier('haarcascade_frontalface_alt2.xml') # 加载分类器
#捕获指定摄像头的实时视频流
cap = cv2.VideoCapture(0)
name_list = os.listdir('./dataset_image/')
def mark_face(name):
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness = 2)
cv2.putText(frame, name,
(x + 30, y + 30), #坐标
cv2.FONT_HERSHEY_SIMPLEX, #字体
1, #字号
(255,0,255), #颜色
2)
while cap.isOpened():
ok, frame = cap.read() # type(frame) <class 'numpy.ndarray'>
if not ok:
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 灰度化
faceRects=classifier.detectMultiScale(gray,scaleFactor=1.2,minNeighbors=3,minSize=(32,32))
if len(faceRects) > 0:
for faceRect in faceRects:
x, y, w, h = faceRect
#截取脸部图像提交给模型识别这是谁
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
if image is None: # 有的时候可能是人脸探测有问题,会报错 error (-215) ssize.width > 0 && ssize.height > 0 in function cv::resize,所以这里要判断一下image是不是None,防止极端情况 https://blog.csdn.net/qq_30214939/article/details/77432167
break
else:
faceID = model.predict(image)
name = name_list[faceID]
mark_face(name)
cv2.imshow("Detecting your face.", frame)
#等待10毫秒看是否有按键输入
k = cv2.waitKey(10)
#如果输入q则退出循环
if k & 0xFF == ord('q'):
break
#释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
上面的代码里定义了一个name_list列表型变量用来存储每个人脸类别的身份名称,用os.listdir()方法去读取图片数据集文件夹下的每个文件夹名称,再赋值给name_list变量,这样当有新的类别加入的时候,更易于扩展。
最后我在进行实际人脸识别的时候,在光线条件较好的情况下,准确度还是很高的,之前在用支付宝的刷脸支付功能的时候也发现,晚上室外光线不好的时候,经常识别不出来(我的手机比较老,本身不带人脸识别功能),这也说明了对于普通的人脸识别算法,光照条件对准确率的影响很大。另外在上一篇用KNN识别的手记最后我还提到要采集女朋友离镜头较远的图片来训练,尝试之后发现效果还不错,女朋友远离摄像头也能较好地识别出来,这说明有了合适的算法以后,采集更丰富多样的训练数据,训练出的模型效果泛化能力会更强。
日志
以上我完成了facenet+SVM实现人脸识别的方案,不过还有一些遗留问题需要说明,比如一开始我探究用SVM的方案是因为KNN是一种懒惰算法,预测时的时间开销太大,那么用了SVM以后就应该量化地比较一下SVM和KNN算法在预测时的速度,这就要分别运行KNN算法和SVM算法程序预测单张图片,并记录时间,之前的程序运行结果我都是直接输出到Spyder IDE自带的IPython Console里,这样虽然比较直观,但是如果想把结果数据保存下来就要手动复制粘贴到文件里然后保存,如果程序算法需要迭代改进反复运行的话,很费力也容易出错,而且关闭Spyder后IPython Console里的内容就没有了。
还好Python提供了logging模块实现日志功能,可以方便地将程序运行过程中想要记录和监控的信息以及程序运行结果记录到文件里保存下来。
下面我结合具体代码来讲解如何使用logging模块实现日志功能。
首先新建一个logs.py文件用来配置日志功能,引入logging模块和sys模块:
import logging
import sys
定义log函数实现输出日志功能,参数就是要输出的日志具体信息。第一步是用getLogger方法实例化日志对象:
def log(message):
# 实例化日志对象,参考https://docs.python.org/3/howto/logging.html#logging-basic-tutorial
logger = logging.getLogger('Test')
接着调用格式器Formatter对象设置日志格式:
# 指定日志输出格式,-8s表示八位字符串,asctime表示日志记录时间,levelname表示日志等级,message是日志具体信息,formatter object具体参考https://docs.python.org/3/howto/logging.html#formatters
# 三个参数,fmt是日志信息格式,datefmt是日期时间格式,style是fmt参数的样式
# 如果不指定fmt,那么就只有原始信息
# 如果不指定datefmt,就会显示到毫秒
# 具体时间格式参考https://docs.python.org/3/howto/logging.html#displaying-the-date-time-in-messages和https://docs.python.org/3/library/time.html#time.strftime
# style indicator默认是'%', 此时message format string uses %(<dictionary key>)s,下面的asctime、levelname和message都是LogRecord attributes
formatter = logging.Formatter('%(asctime)s %(levelname)-8s: %(message)s', '%m/%d/%Y %I:%M:%S %p')
格式器对象用来设置日志的顺序、结构和内容,主要有三个参数:
fmt:指定日志信息格式的字符串,也就是日志由哪些部分、以怎样的顺序构成datefmt:指定日志时间格式的字符串style:指定fmt参数中LogRecord attributes前面的符号,可以是%、{或$
以上面代码中Formatter对象的参数为例说明一下,第一个参数'%(asctime)s %(levelname)-8s: %(message)s中的三个%就是由style参数指定的,asctime、levelname和message都是LogRecord attributes,日志输出的时候就会按时间、日志等级名称和日志信息这个结构和先后顺序输出。
另外一点需要说明的是asctime默认的时间输出会精确到毫秒,这里我感觉不太必要,就用datefmt自己控制了时间输出,具体可以参考Python官方文档的说明
设置了日志的结构和格式,还需要指明日志需要输出到哪里,比如,像我之前那样,都输出到IPython Console,或者输出到文件,这就要用到处理器Handler对象。在运行程序的时候,我既希望能直接将信息输出到IPython Console里快速直接地看结果,也希望能将结果输出到日志文件里方便地保存下来,正好logging模块自带了StreamHandler和FileHandler能分别实现这两个目的:
# 控制台日志,StreamHandler是通过sys.stdout发送到console,FileHandler则发送到文件,参考https://docs.python.org/3/library/logging.handlers.html#logging.StreamHandler
console_handler = logging.StreamHandler(sys.stdout)
# 给输出到控制台的日志指定格式
console_handler.formatter = formatter
# 文件日志
file_handler = logging.FileHandler("performance.log")
file_handler.formatter = formatter
logger.addHandler(file_handler)
logger.addHandler(console_handler)
上面的代码里我创建了console_handler和file_handler分别用来把日志输出到IPython Console和performance.log文件,创建好以后再通过add_handler方法把这两个Handler添加到之前创建的logger实例上,后面输出日志的时候就会在IPython Console和performance.log文件同时输出。
接着再设置一下日志级别,并输出日志:
# 指定日志的最低输出级别,默认为WARN级别
logger.setLevel(logging.INFO)
logger.info(message)
logger.removeHandler(file_handler)
logger.removeHandler(console_handler)
值得一提的是上面的代码再输出日志后还调用了removeHandler方法,因为之前遇到了多次运行程序后会将一条日志重复写多次的问题,就是因为没有移除Handler。
SVM vs KNN
设置好了日志功能,就可以将其应用到主要程序中,先来比较一下之前训练好的SVM和KNN模型在预测单张图片时的速度,回到face_classifier.py,先引入刚才定义的log函数,在最后运行SVM算法的部分还要增加一些计时和输出日志的代码:
…………
…………
from logs import log
…………
…………
if __name__ == "__main__":
# pickle方式加载数据
dataset = Dataset('./dataset_pkl/')
dataset.load()
# 用一张图片测试knn和svm模型的预测速度
image = cv2.imread('./dataset_image/me/175.jpg')
model = svm_Model()
model.build_model()
model.train(dataset)
model.save_model('./model/svm_classifier.model')
start = time.time()
model.load_model('./model/svm_classifier.model')
log("Loading svm model took {} seconds.".format(time.time() - start))
start1 = time.time()
model.predict(image)
log("Predicting one face using svm model took {} seconds.".format(time.time() - start1))
运行程序后可以在perforance.log文件里看到:
01/07/2019 08:51:48 PM INFO : Predicting one face using svm model took 0.0010004043579101562
用同样的方式可以测试用KNN模型预测单张人脸的速度,结果如下:
01/07/2019 09:06:53 PM INFO : Predicting one face using knn model took 0.022997379302978516 seconds.
可以看到SVM模型的预测速度比KNN模型要快的多。
上面的比较其实是比较简单的,也不够完善,毕竟这只是一个demo级别的项目,实际的人脸识别系统其算法肯定比这个项目要复杂的多,做这个比较只是说明在选择机器学习算法的时候要考虑算法的特点,从而判断是否适合要解决的问题,人脸识别广泛应用于安防、门禁、解锁、支付等对实时性要求比较高的场景,显然,识别速度更快的SVM比KNN更适合。
Pickle vs HDF5
有了合适的算法,我还想对特征向量的存储和加载做一些优化。前面用的Pickle是Python标准库中自带的模块,使用起来很方便,但是它有两个缺点:
- 对大型数据结构比如使用 array 或 numpy 模块创建的二进制数组效率并不高,当数据量较大的时候其存储、读取和压缩效率都不够高;
- 由于是Python标准库自带模块,对其他语言的支持就不够好。
一种比较好的改进方案是HDF,维基百科中HDF的介绍如下:
HDF(英语:Hierarchical Data Format)指一种为存储和处理大容量科学数据设计的文件格式及相应库文件。HDF最早由NCSA开发,目前在非盈利组织HDF小组维护下继续发展[1]。当前流行的版本是HDF5。
HDF5文件包含两种基本数据对象:
群组(group):类似文件夹,可以包含多个数据集或下级群组。
数据集(dataset):数据内容,可以是多维数组,也可以是更复杂的数据类型。
群组和数据集都支持元数据,用户可以自定义其属性,提供附加信息。
HDF现在被众多商业与非商业平台支持,包括Java,MATLAB/Scilab,Octave,IDL,Julia, Python和R。
可以看到HDF5对Python和JAVA等常用语言都能支持。具体到Python,有一个H5py包提供了HDF5二进制数据格式的接口。在学习吴恩达深度学习课程的时候看到里面的数据集都是h5后缀的文件,就是以hdf5格式存储并用H5py进行加载的,为了看看H5py是否比Pickle更好,我也做了实验,将feature_extract.py中Pickle保存数据的部分替换为HDF5的方式,其他不变:
import os
import numpy as np
import cv2
from keras.models import load_model
import pickle
import h5py
…………
#中间其他代码和之前一样
…………
if __name__ == "__main__":
images, labels = load_dataset('./dataset_image/')
# 生成128维特征向量
X_embeddings = img_to_encoding(images, facenet) # 考虑这里分批执行,否则可能内存不够,这里在img_to_encoding函数里通过predict的batch_size参数实现
# hdf5保存数据
# 创建h5文件的语句必须写在if __name__ == "__main__":里,否则运行face_classifier.py的时候会执行创建h5文件的语句
with h5py.File("./dataset_h5/face_embeddings.hdf5", "w") as f_faces:
d1 = f_faces.create_dataset("face_embeddings", data = X_embeddings)
with h5py.File("./dataset_h5/face_labels.hdf5", "w") as f_labels:
# Unable to open object (object 'face_embeddings' doesn't exist)
d2 = f_labels.create_dataset("face_labels", data = labels)
H5py的使用和Pickle类似,也是先创建文件用来存储数据,不同的是HDF5文件里保存的是数据集(datasets)和群组(groups)两类对象,数据集对象是数组形式的数据集合,群组对象是文件夹形式的容器,包含数据集和其他的群组。
在上面的代码中,我先用File方法创建文件对象,然后再用文件对象的create_dataset方法创建数据集对象,我的特征向量数据就保存在数据集对象里。
注意到上面在创建HDF5文件对象的时候用到了with语句,这是Python中最常用的一种上下文管理器(Context Manager),在这里起到的作用是即使with语句下面创建数据集的语句出现异常,也能确保最后HDF5文件被关闭,这就涉及到了资源管理问题。资源管理是程序设计中的一个常见问题,比如文件的开启和关闭,数据库的连接和断开等,如果没有及时关闭资源,就会影响程序执行的效率,甚至出现错误,之前我在使用H5py创建HDF5文件的时候没有用with语句,遇到报错:
OSError: Unable to create file (unable to truncate a file which is already open)
这就是因为忘记关闭文件对象,导致再次运行feature_extract.py的时候无法创建文件,看到这里应该可以想到之前用Pickle保存特征向量的部分,在创建文件的时候也应该改用with语句:
with open('./dataset_pkl/embeddings.pkl', 'wb') as file_embeddings:
pickle.dump(X_embeddings, file_embeddings)
with open('./dataset_pkl/labels.pkl', 'wb') as file_labels:
pickle.dump(labels, file_labels)
类似的,用Pickle加载特征向量部分的代码也可以改成:
# 加载数据集到内存,pickle方式,改用上下文管理器形式
with open(self.path_name + 'embeddings.pkl', 'rb') as file_embeddings:
X_embeddings = pickle.load(file_embeddings) # 考虑这里分批执行,否则可能内存不够,这里在img_to_encoding函数里通过predict的batch_size参数实现
# 加载128维特征向量
with open(self.path_name + 'labels.pkl', 'rb') as file_labels:
labels = pickle.load(file_labels)
而用HDF5方式加载数据的代码则为:
# hdf5方式加载数据
# KeyError: "Unable to open object (object 'face_embeddings' doesn't exist)"
with h5py.File(self.path_name + 'face_embeddings.hdf5', 'r') as f_faces:
# for key in f_faces.keys():
# print("keys: ", key)
# 读不到数据集,参考 https://www.pythonforthelab.com/blog/how-to-use-hdf5-files-in-python/
X_embeddings = f_faces['face_embeddings'][:]
with h5py.File(self.path_name + 'face_labels.hdf5', 'r') as f_labels:
labels = f_labels['face_labels'][:]
这段代码中值得一提的是X_embeddings = f_faces['face_embeddings'][:]和labels = f_labels['face_labels'][:]这两条最后都有一个[:],最开始我没有加[:],结果报错,看到这篇博文才知道,当我把f_faces['face_embeddings']赋值给X_embeddings的时候,并没有把文件中存储的特征向量数据读取出来,而是生成了一个指向数据的指针,加了[:]就能正常读取数据了。
我对H5py和Pickle读取数据的速度也做了简单的比较,不过由于这个项目里数据量很小,二者的差别并不明显,我就不放结果了。
总结与继续改进的方向
至此,这个人脸识别的小demo算是初步成型了,最终采用的Facenet+SVM的方案在识别准确度和识别速度上都较之前Facenet+KNN的方案有所提升,不过这毕竟是个demo级别的项目,本身还有许多可以改进和继续完善的地方:
- 可以尝试改用dlib和mtcnn等人脸检测算法并与当前用OpenCV自带的Haar检测器比较;
- 了解Insight face等更新的人脸分类算法;
- 考虑KD tree 和Ball tree等KNN改进算法,并与SVM比较预测速度;
- 了解face liveness detection & face anti-spoof;
- 了解估量算法性能的更标准的方法。
参考资料
- Choosing the right estimator——scikit-learn tutorials
- OpenFace学习(2):FaceNet+SVM匹配人脸
- pickle 保存数据——莫烦
- pickle — Python object serialization
- 序列化——维基百科
- davidsandberg/facenet —— Github
- Support Vector Machines——Classification——scikit-learn
- logging — Logging facility for Python
- 利用深度学习开发老板探测器,再也不担心刷着微博一回头突然看到老板了——雷锋网
- Hironsan/BossSensor
- Python3 File(文件) 方法——菜鸟教程
- What does ‘wb’ mean in this code, using Python?——StackOverflow
- 5.21 序列化Python对象—— python3-cookbook
- 支持向量机(Support Vector Machines-SVM)算法笔记(二)-scikit learn
- 交叉验证 2 Cross-validation——SK Learn机器学习教程
- Logging HOWTO——Basic Logging Tutorial
- Python之日志处理(logging模块)
- python logging 重复写日志问题
- HDF——维基百科
- 快速开始——H5py官方文档
- 谈一谈Python的上下文管理器
- Python 的with 语法使用教学:Context Manager 资源管理器
共同学习,写下你的评论
评论加载中...
作者其他优质文章



