
这次的代码,结合上次的批量文件合并,可以使代码能够先给特征数据集添加列名,然后批量合并,形成自动化的预处理😎
完整代码:
import os
import pandas as pd
import numpy as np
import math
# 获取文件名
def get_data_set(path):
data_directory = path + "/data"
data_files = []
files = os.listdir(data_directory)
files.sort()
for f in files:
try:
data_files.append(f)
except Exception:
msg = traceback.format_exc()
print (msg)
print('Warning: unknown file', f)
return data_files #返回一个文件名列表
#根据文件名读文件
def data_read(path,file_name):
data_file_path = path + "/data/"
data_file_path = data_file_path + file_name
name,extension = file_name.split(".")
if extension == "csv":
try:
data = pd.read_csv(data_file_path,encoding = "gbk",header = None)
except:
data = pd.read_csv(data_file_path,encoding = "utf-8",header = None)
elif extension == "txt":
try:
data = pd.read_csv(data_file_path,encoding = "gbk",header = None,sep = "\t")
except:
data = pd.read_csv(data_file_path,encoding = "utf-8",header = None,sep = "\t")
else:
data = pd.read_excel(data_file_path)
return data
#删除无用字段,替换原文件
def data_clean(path):
data_files = get_data_set(path)
#前N-1个文件
#删除0,1,2,3,5,6,7,8列
for i in range(len(data_files) - 1):
d1 = data_read(path,data_files[i])
d1 = d1.drop([0,1,2,3,5,6,7,8],axis = 1)
f1_name = data_files[i]
print (f1_name)
d1.to_csv(path+"/data/"+f1_name,header=False,index=False)
#第N个文件
#删除0,1,2,4,5,6,7列
d2 = data_read(path,data_files[len(data_files) - 1])
d2 = d2.drop([0,1,2,4,5,6,7],axis = 1)
f2_name = data_files[len(data_files) - 1]
print (f2_name)
d2.to_csv(path+"/data/"+f2_name,header=False,index=False)
File_columns_dict = \
"d1.csv:ID,x1_class,x2_class,x3_class,x4_class,x5_num,x6_num,x7_num,x8_class \
|d2.csv:ID,x9_class,x10_class,x11_class,x12_class,x13_num,x14_num,x15_num,x16_class,x17_num \
|d3.csv:ID,x18_class,x19_class,x20_class,x21_class,x22_num,x23_num,x24_num,x25_class,x26_num,x27_num \
|d4.csv:ID,x28_class,x29_class,x30_class,x31_class,x32_num,x33_num,x34_num,x35_class,x36_num,x37_num,x38_class,x39_num \
|d5.csv:ID,x40_class,x41_class,x42_class,x43_class,x44_num,x45_num,x46_num,x47_class,x48_num,x49_num,x50_class,x51_num,x52_num"
#config_str = File_columns_dict
def get_all_factor_dict(config_str):
columns_name_dict = {}
config_items = config_str.split('|')
for config_item in config_items:
config_pair = config_item.split(':')
File_columns_key = config_pair[0]
File_columns_values = config_pair[1]
name_list = []
item_value_arr = File_columns_values.split(',')
for i in range(len(item_value_arr)):
name_list.append(item_value_arr[i])
columns_name_dict[File_columns_key] = name_list
return columns_name_dict
"""
预计输出结果:
输出一个字典:
{
'd1.csv':['ID','x1_class','x2_class','x3_class','x4_class','x5_num','x6_num','x7_num','x8_class'],
'd2.csv':['ID','x9_class','x10_class','x11_class','x12_class','x13_num','x14_num','x15_num','x16_class','x17_num'],
'd3.csv':['ID','x18_class','x19_class','x20_class','x21_class','x22_num','x23_num','x24_num','x25_class','x26_num','x27_num'],
'd4.csv':['ID','x28_class','x29_class','x30_class','x31_class','x32_num','x33_num','x34_num','x35_class','x36_num','x37_num','x38_class','x39_num'],
'd5.csv':['ID','x40_class','x41_class','x42_class','x43_class','x44_num','x45_num','x46_num','x47_class','x48_num','x49_num','x50_class','x51_num','x52_num']
}
"""
#给字段加列名,替换原文件
def data_set_columns(path,file_columns_dict):
data_files = get_data_set(path)
for i in range(len(data_files)):
data_file = data_read(path,data_files[i])
file_column = file_columns_dict[data_files[i]]
data_file.columns = file_column
f1_name = data_files[i]
data_file.to_csv(path+"/data/"+f1_name,index=False)
def main():
path = "E:/AnaLinReg/BFM/code_test/DataSet1"
#data_clean(path)
config_str = File_columns_dict
file_columns_dict = get_all_factor_dict(config_str)
data_set_columns(path,file_columns_dict)
print ("Done")
if __name__ == "__main__":
main()
示例文件及效果
原始文件: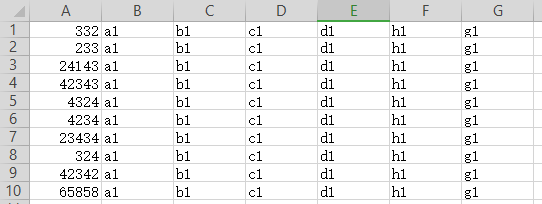
代码运行后: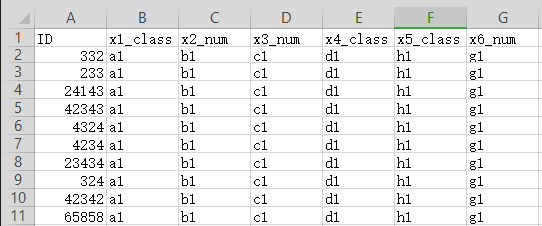
需要被预处理的文件列表:
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中



感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦