
本系列介绍
本系列《剖析缓存系列》,由浅到深的对缓存进行分析介绍,从缓存形式,更新策略,常见问题,以及JAVA缓存使用(JCache,Spring cache,Ehcache)和缓存服务器redis
系列目录
缓存
缓存形式
缓存形式分为种静态资源,动态资源,数据缓存
静态资源
静态资源一般指js、css、img 等非服务器动态运行生成的文件,该文件变更频率很低。
浏览器缓存(HTTP缓存)
浏览器缓存目的是为了节约网络的资源加速浏览和服务器压力。把一个已经请求过的资源拷贝一份存储起来,当下次需要该资源时,浏览器会根据缓存机制决定直接使用缓存资源还是再次向服务器发送请求
浏览器缓存又分为强制缓存和协商缓存
- 强制缓存
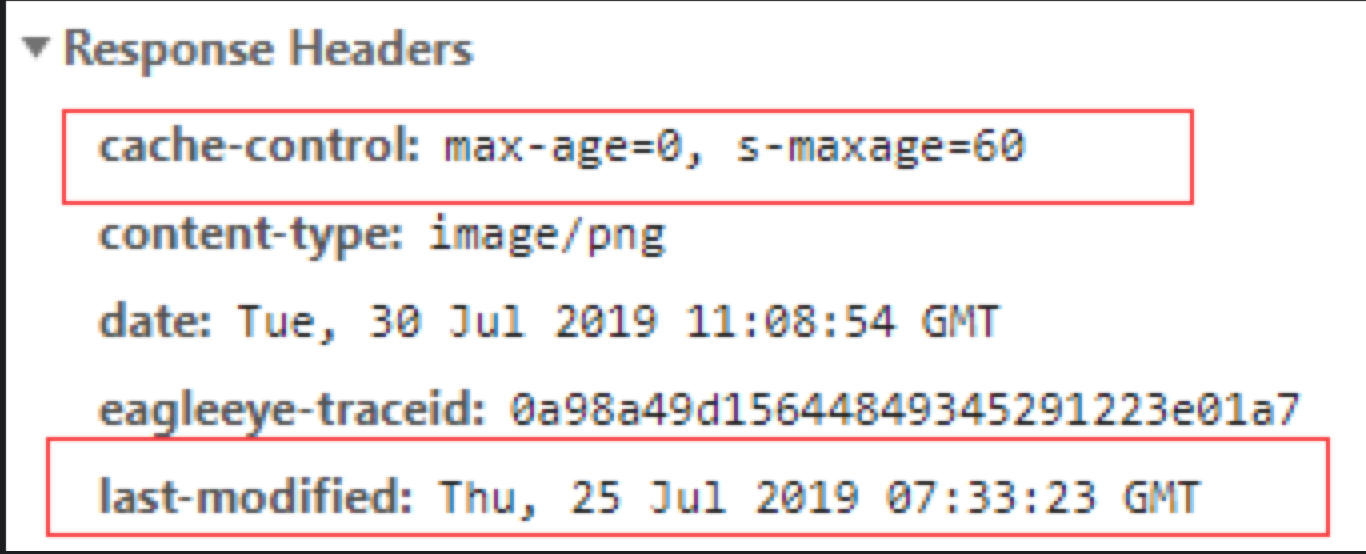
浏览器访问一资源的时候,会先判断资源请求头的header字段信息,根据两个字段Expires/Cache-Control判断是否命中缓存。如果命中缓存,那么就不会向服务器请求资源
两个header字段:
- Expires:
资源过期时间,0代表已过期。http1.0版本,已不推荐使用
示例:Expires: Wed, 21 Oct 2015 07:28:00 GMT - Cache-Control:
通过指定指令来实现缓存机制。http1.1版本新增的字段。
Cache-Control的请求header命令列表
| 字段名称 | 说明 |
|---|---|
| max-age=seconds | 缓存最大时间 |
| max-stale[=seconds] | 接受超过缓存时间secondes秒的资源 |
| min-fresh=seconds | 接收在secondes内刷新过的资源 |
| no-cache | 不使用缓存 |
| no-store | 内存不会存在临时文件中 |
| no-transform | 接收没有被转换的数据,例如没有被压缩的数据 |
| only-if-cached | 只接受已缓存的响应 |
Cache-Control的响应header命令列表
| 字段名称 | 说明 |
|---|---|
| public | 表明响应可以被任何对象(包括:发送请求的客户端,代理服务器,等等)缓存 |
| private | 表明响应只能被单个用户缓存,不能作为共享缓存(即代理服务器不能缓存它) |
| proxy-revalidate | 接收在secondes内刷新过的资源 |
| no-cache | 不使用缓存 |
| no-store | 内存不会存在临时文件中 |
| no-transform | 接收没有被转换的数据,例如没有被压缩的数据 |
| max-age=seconds | 设置缓存存储的最大周期,超过这个时间缓存被认为过期(单位秒) |
| s-maxage=seconds | 设置缓存最大周期,覆盖max-age或者Expires头 |
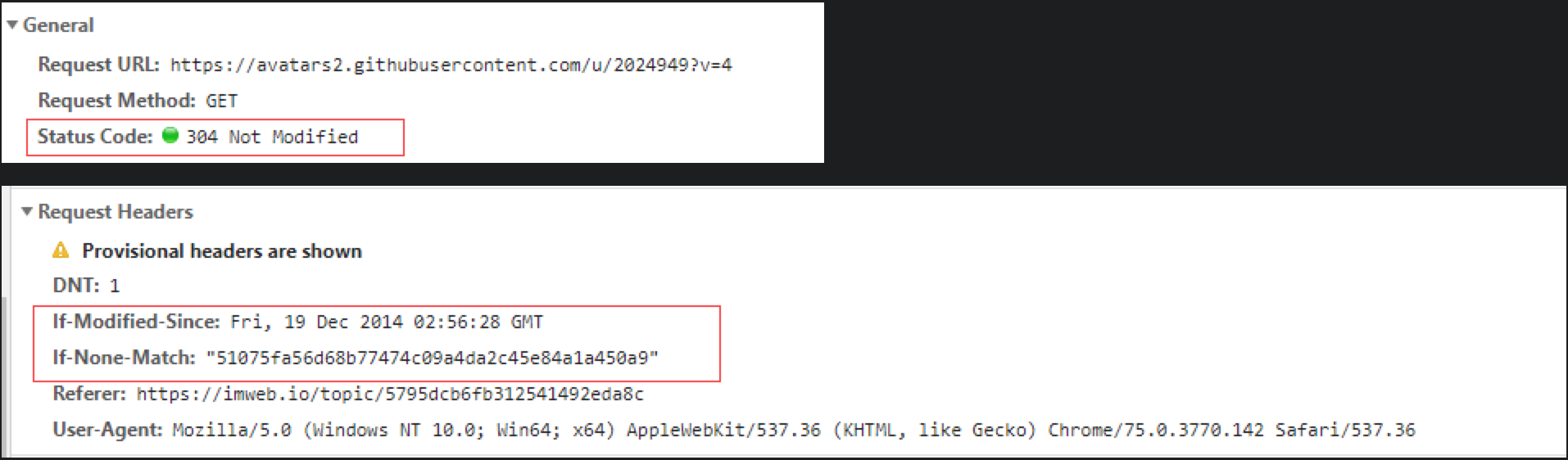
- 协商缓存
如果强制缓存没有命中或者已经过期,览器携带缓存标识请求服务器,当服务器返回200状态码浏览器会重新请求资源,当返回304状态码浏览器会重新使用该缓存。在这个过程中304状态码就是与服务器协商是否要重新更新缓存,虽然多了一次请求,但却不用重新请求资源,节省了请求资源的带宽。
协商缓存的header字段
-
Last-Modified或者Etag:第一次请求资源时,会带上该字段
- Last-Modified:比较服务器文件修改时间是否一致,如果一致,认为文件并没有修改,不需要重新请求资源。可能存在文件没修改内容,但是修改时间变了,导致浏览器重新请求资源。
- Etag:会对文件计算出一个唯一标识符,判断这个唯一标识符是否一致得知文件是否被修改。
-
If-Modified-Since或者If-None-Match :后续的请求,都会带上这个字段
- If-Modified-Since 是一个条件式请求首部,服务器只在所请求的资源在给定的日期时间之后对内容进行过修改的情况下才会将资源返回,状态码为 200。如果请求的资源从那时起未经修改,那么返回一个不带有消息主体的304 响应,而在 Last-Modified 首部中会带有上次修改时间。If-Modified-Since 只可以用在 GET 或 HEAD 请求中。
- If-None-Match 是一个条件式请求首部。对于 GETGET 和 HEAD 请求方法来说,当且仅当服务器上没有任何资源的 ETag 属性值与这个首部中列出的相匹配的时候,服务器端会才返回所请求的资源,响应码为 200 。对于其他方法来说,当且仅当最终确认没有已存在的资源的 ETag 属性值与这个首部中所列出的相匹配的时候,才会对请求进行相应的处理。
例:
刷新缓存行为,导致缓存方式都不一样
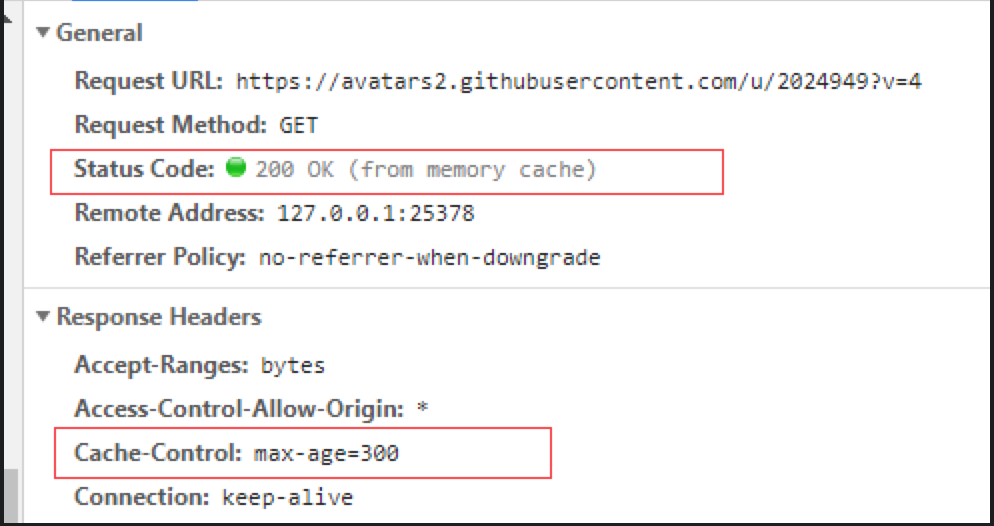
- 在URI输入栏中输入然后回车/通过书签访问
如下图,可以看到该资源是直接从缓存中读取,并没有发起请求 - F5/点击工具栏中的刷新按钮/右键菜单重新加载
如下图,刷新页面,浏览器会去请求服务器资源,但是由于服务器资源没有修改,会返回304 - Ctl+F5 强行刷新缓存
如下图,浏览器首先不会理会本地是否有缓存,而且也不会去比较服务器的缓存资源是否有修改,而是直接请求资源(为了服务器不会返回304,浏览器会将header的If-None-Match表示去掉)
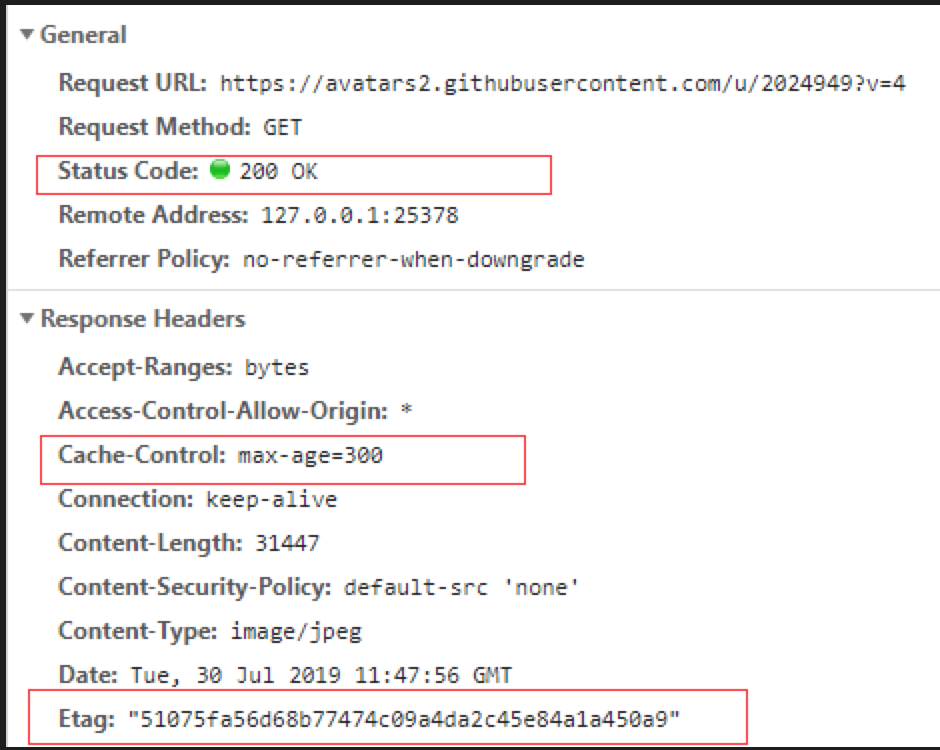
缓存实践:
- 通常会使用Cache-Control代替Expires。
- 对于所有可缓存资源,指定一个Cache-Control max-age以及一个Last-Modified或ETag至关重要。因为Cache-Control max-age不需要每次都发起一次请求来校验资源时效性,Last-Modified或ETag保证当资源未出现修改的时候不需要重新发送该资源。
- 有时候Cache-Control的过期时间很难控制。对于长期不会改变的资源,设置时间短了,会频繁请求服务器返回304。所以通常会将过期设置设置很长,通过在文件名或参数带上一串md5或时间标记符。文件没有变动的时候,浏览器不用发起请求直接可以使用缓存文件;而在文件有变化的时候,由于文件版本号的变更,导致文件名变化,请求的url变了,自然文件就更新了。例如:
https://doi.io/topic/index.js?43d3ea2083f1e631dbc4
服务器缓存
服务器缓存通常指的是将资源放在专门缓存服务器上,为了减轻业务服务器的压力。
此篇简单介绍一下CDN缓存和Nginx缓存
- CDN缓存:CDN服务商将源站的资源缓存到遍布全国的高性能加速节点上,当用户访问相应的业务资源时,用户会被调度至最接近的节点最近的节点ip返回给用户
- Nginx 静态资源缓存: 目前很多项目都是前后端分离,前端项目会部署在Nginx服务器,对于站点中不经常修改的静态内容(如图片,JS,CSS),可以在Nginx服务器中设置expires过期时间,控制浏览器缓存,达到有效减小带宽流量,降低服务器压力的目的
nginx配置例子
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$ {
#过期时间为30天,
#图片文件不怎么更新,过期可以设大一点,
#如果频繁更新,则可以设置得小一点。
expires 30d;
}
location ~ .*\.(js|css)$ {
expires 10d;
}
动态缓存
是在新内容发布以后,并不预先生成相应的静态页面,直到对相应内容发出请求时,如果前台缓存服务器找不到相应缓存,就向后台内容管理服务器发出请求,例如数据库,后台系统会生成相应内容的静态页面,用户第一次访问页面时可能会慢一点,但是以后就是直接访问缓存了。例如:对动态页面.jsp、.asp/.aspx、.php、.js(nodejs)等动态页面缓存。通常动态页面一般都会涉及动态计算、数据库缓存、数据库操作,所以每一次访问同一个页面,所获得的数据可能都有所不同。所以动态缓存并适合所有的场景。
详细链接
数据缓存
数据缓存通常是把计算量大,访问耗时,请求频率高的数据放在内存中,主要提高计算效率,减少请求响应时间,减少无谓的数据库和网路的访问。数据缓存是本系列的重点,以下篇幅都是围绕数据缓存展开。
缓存的成本和收益
- 计算量,缩短请求流程(减少网络io或者硬盘io)
- 减少用户请求的带宽和减少服务器压力
优点:
| 优点 | 描述 |
|---|---|
| 缩短请求流程(减少网络io或者硬盘io) | 浏览器缓存,cdn缓存,可以减少请求资源的过程,加快响应速度 |
| 降低后端负载 | 对耗时高的请求,可以很大程度降低了后端的负载 |
| 缺点 | 描述 |
|---|---|
| 对硬件要求高 | 一般缓存都是放在内存中,内存是稀缺资源 |
| 数据不一致问题 | 相当于增加了一个数据源,当数据发生变化,会出现脏数据现象 |
| 维护成功高 | 加入缓存后,需要同时处理缓存层和存储层的逻辑,增加了开发者维护代码的成本 |
动态缓存
是在新内容发布以后,并不预先生成相应的静态页面,直到对相应内容发出请求时,如果前台缓存服务器找不到相应缓存,就向后台内容管理服务器发出请求,例如数据库,后台系统会生成相应内容的静态页面,用户第一次访问页面时可能会慢一点,但是以后就是直接访问缓存了。例如:对动态页面.jsp、.asp/.aspx、.php、.js(nodejs)等动态页面缓存。通常动态页面一般都会涉及动态计算、数据库缓存、数据库操作,所以每一次访问同一个页面,所获得的数据可能都有所不同。所以动态缓存并适合所有的场景。
详细链接
数据缓存
数据缓存通常是把计算量大,访问耗时,请求频率高的数据放在内存中,主要提高计算效率,减少请求响应时间,减少无谓的数据库和网路的访问。数据缓存是本系列的重点,以下篇幅都是围绕数据缓存展开。
缓存更新策略
| 策略 | 一致性 | 维护成本 |
|---|---|---|
| LRU/LIRS/FIFO算法剔除 | 最差 | 低 |
| 超时剔除 | 较差 | 较低 |
| 主动更新 | 强 | 高 |
LRU/LIRS/FIFO算法剔除
LRU
将最近最少使用的数据清理掉,这个算法很普通。Mysql的内存中存储数据就是使用LRU策略,只存储热点数据
LFU
淘汰一定时期内被访问次数最少的数据
FIFO
前进先出队列,旧缓存先被清除
超时剔除
这种策略对数据一致性要求不高。
定时删除
设置缓存的过期时间,当时间到的时候,自动删除缓存。例如redis的expire过期时间一样。
缺点:对应业务项目如果使用定时删除,那么每个缓存都需要有一个定时器,或者一个监听线程,这样会占用cpu资源,会导致cpu过度紧张。而且还需要开发和维护定时器,提高了开发成本
懒惰删除
设置一个过期时间,只有当请求获取这个缓存的时候,才会对这个缓存进行过期检查。如果过期,就会执行过期策略(删除或者刷新)。
例如 java的缓存框架guava cache就是用这种策略。
优点:可以不占用新的资源去管理缓存
缺点:对于过期的缓存,无法即时释放。过期缓存过多,会占用大量的内存
定期删除
建立一个线程定期去扫描过期的缓存,将过期的缓存执行策略
优点:占用小量的cpu资源,解决了过期缓存过多导致占用大量内存的问题
缺点:扫描时间设置要合理,否则也会造成cpu浪费
主动更新
这种策略是对数据一致性要求比较高。
- Cache Aside
最常用的一种模式。
- 失效:请求从缓存中获取数据,没有得到,则从数据库中获取
- 命中:应用程序从缓存中获取数据,返回
- 更新:先更新数据库,成功后,再更新缓存
特点:需要维护两个数据源(缓存和数据库)。更新数据库的过程中,其他读请求从缓存读取的数据是旧的。
- Read/Write Through
只让请求维护一个数据源,数据库对请求来说是透明的
-
Read Through Pattern
读取数据时的策略
当缓存没有命中(缓存中没有得到数据),由缓存服务来加载数据。同时,请求可能会阻塞等待或者返回。 -
Write Through
更新数据时的策略
请求更新数据的时候,如果缓存没有数据,直接更新数据库,如果缓存有数据,直接更新缓存,同时缓存服务会将缓存数据更新到数据库中,当数据库更新成功,才认为更新数据成功
特点:代码实现会比较复杂。当写请求更新到缓存的时候,同时读请求是可以在缓存中读取到数据,提高了读的效率。但是这会增加写请求的响应时间,因为写请求需要更新缓存和数据库。
- Write Behind
与Read/Write Through 模式相似,但是更加最求响应速度
当更新缓存的时候,Write Through是同步更新数据库,而Write Behind是异步更新数据库,写请求只需要写入到缓存就可以返回,缓存服务会异步同步到数据库中。
特点:代码实现复杂,需要考虑很多场景,例如 内存不够,更新数据过多,更新线程还没写到持久层就宕机导致数据丢失等等
缓存数据格式
缓存是一个类map的key-value的数据格式。key-value通常都是非null的,key-value都可以是引用也可以是基本数据类型(字符串,数字等)。key在整个缓存中是唯一。
缓存常见现象
缓存穿透
缓存穿透是指缓存没有发挥作用,导致请求需要读取数据源数据。具体有两种情况:
- 没有命中缓存:
由于被访问的数据是空数据,不存在的,所以缓存中不会存在。一般来说,访问不存在的数据的请求不多,不会对服务器造成很大的影响,但是如果有人恶意去访问这些不存在的数据,那么这些请求都会落到数据源中请求,对数据源造成很大的压力。
解决办法:- 如果查询存储系统的数据没有找到,则直接设置一个默认值(可以是空值,也可以是具体的值)存到缓存中,这样第二次读取缓存时就会获取到默认值,而不会继续访问存储系统。
- 对这种请求,通过nginx或者网关层直接拒绝,或者添加ip白名单过滤掉
- 使用布隆过滤器,可以将不可能存在的数据在这个布隆过滤器中拦截掉
- 无法完全缓存数据
查询的数据太大,无法完全缓存起来,因为会占用很大的内存空间。例如分页,很多用户只会看前几页的数据,所以存储前几页的数据才是最优解。
解决办法:对应这种场景,可以对数据进行切割,只缓存前几页的数据。如果遇到爬虫或者恶意查询,可以通过监控服务器状态,发现问题后及时处理。
缓存雪崩
缓存雪崩是指当缓存失效(过期)后引起系统性能急剧下降的情况。当缓存过期被清除后,业务系统需要重新生成缓存,因此需要再次访问数据源,再次获取数据,这个处理步骤耗时几十毫秒甚至上百毫秒(因为大部分缓存的数据都是耗时操作)。而对于一个高并发的业务系统来说,
QPS都是上百上千的,这些请求都会直接访问数据源,导致数据源压力瞬间增大。
解决办法:
-
锁机制
这种策略很常见,在GuavaCache中就用到了这种策略。当多个请求访问这个(缓存失效)缓存时,只允许一个线程去刷新缓存,其他线程则休眠等待或者返回空数据或者默认值。这种方法实现简单,但这是对于单机环境下来说的。
如果是在分布式环境下,几百台服务器,那么刷新缓存只能让某台服务器的单个线程去刷新缓存,这时候就需要分布式锁。典型的分布式锁有redis和zookeeper -
避免缓存失效
这种思路很巧,导致雪崩是因为缓存的失效,那么就让缓存不失效的同时也保证缓存的时效性。可以设置缓存永久存在,后台起一个刷新缓存的线程,定期去刷新缓存,那么就不会存在缓存失效的问题。
但这也存在一个问题,就是缓存的主动更新问题,如果由该线程去完成,那么就需要有一个消息队列来通知这个更新缓存线程去主动更新缓存,实现逻辑也会变得复杂。
后台更新机制还适合业务刚上线的时候进行缓存预热。缓存预热指系统上线后,将相关的缓存数据直接加载到缓存系统,而不是等待用户访问才来触发缓存加载。 -
缓存集群
这种方式涉及到分布式缓存,为了防止可能因为缓存服务宕机导致的缓存大量失效,可以使用memcache或者redis集群保证缓存高可用性
缓存降级
当访问量剧增,缓存服务扛不住这么大的访问量的时候,这时候需要对某些非核心功能的业务缓存数据进行降级,为了保证核心业务可用。
无底洞问题
当分布式缓存连接效率下降,就算添加缓存服务器也没有好转,这种情况就叫无底洞问题。
分布式缓存就算将不同的缓存存储在不同的服务器上,当请求的时候,通过计算定位缓存位置并向缓存服务器获取缓存。当请求是批量操作的时候,请求的缓存在多台缓存服务器上,就会出现多次io请求,出现无法避免的耗时
解决方案:
- 针对业务的特点,采取不同的缓存存储方案,通常有两种存储方式:哈希存储和顺序存储
| 分布方式 | 特点 | 典型产品 |
|---|---|---|
| 哈希分布 | 1.数据分散度高 2. key分布与业务无关 3. 无法顺序访问 4.支持批量操作 | 一致性哈希memcache |
| 顺序分布 | 1. 数据分散度易倾斜 2. key分布与业务有关 3.可以顺序访问 4.支持批量操作 | BigTable Hbase |
- 利用不同批量操作的方法:串行mget,串行io,并行io,hash tags
- 串行mget:时间复杂度高,操作时间=n次网络时间+n次命令时间,基本没有优化。
- 串行IO:对mget操作根据计算,算出查询key对应的节点,对相同节点的key合并成一次mget请求(相当于有mget涉及到多少个节点,就有多少个IO请求)。操作时间=node次网络时间+n次命令时间
- 并行IO:在串行IO的基础上,改为多线程请求缓存服务器。操作时间=1次网络时间+n次命令时间
- hash-tag: 强行将一些key缓存到指定的节点上,那么读取缓存就只需要直接去该节点读取就可以,例如redis 支持hash-tag操作。操作时间=1次网络时间+n次命令时间
共同学习,写下你的评论
评论加载中...
作者其他优质文章


