
一、前言
仅仅只是关于编码问题的一些小思考,简单过一下。
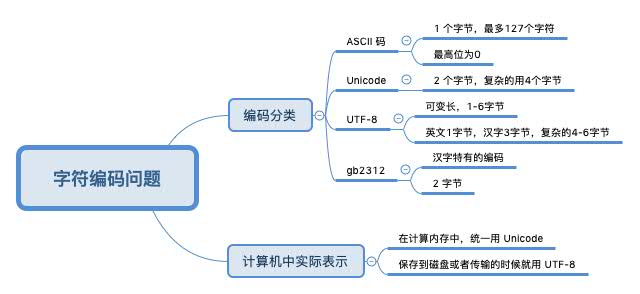
二、关于编码
三、验证
以往我们可能了解的都是一些理论知道,下面我们来通过 Python3 来验证一下。分别来看看英文字符 ‘A’ 和 ‘中’ 分别在不同编码下的实际情况。
A 的 ASCII 、UTF-8、GB2312 编码
>>> 'A'.encode('ascii')
b'A'
>>> 'A'.encode('utf-8')
b'A'
>>> 'A'.encode('gb2312')
b'A'
中的 ASCII 、UTF-8、GB2312 编码
>>> '中'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character '\u4e2d' in position 0: ordinal not in range(128)
>>> '中'.encode('utf-8')
b'\xe4\xb8\xad'
>>> '中'.encode('gb2312')
b'\xd6\xd0'
可以看到中文是不能进行 ASCII 编码的。
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦