
乾明 发自 凹非寺
量子位 报道
理科生文艺起来,可能真没文科生什么事了。
不信?你看下这首七言绝句:

有网友读完之后表示:
真??啊,押韵,意境,内涵都很赞。
不仅能够写诗,还能作词,比如这首满江红:

而且,还能写藏头诗:

你能想象,这是完全不懂写诗的理工生的杰作吗?
但它就是。
这些诗来自华为诺亚方舟实验室新推出的写诗AI“乐府”。
问世之处便引发了不少关注。
对于它的作品,有人称赞:
蕴意丰富的诗,工整不乏意趣,程序做的实在牛逼,给开发人员点赞
还有人“搞事情”,表示:
一声塞雁江南去,几处家书海北连。莫道征鸿无泪落,年年辛苦到燕然。要说这个 AI 写的没有北大中文系平均水平好我是不信的。

甚至有人说“李白看了会沉默,杜甫看了会流泪”。

当然,也有人指出问题:
很工整,不过感觉目前大多还是syntax层面的,没有到semantics层面。稍微欠缺些灵魂。
也有“真相帝”出来发声:
辛弃疾的流水散文式用典,老杜的沉郁顿挫拗救法,都是AI比较难学会的。问题不是AI太厉害,而是读者已经看不出格律诗里面比较精密的手法了…

对于这些问题,华为诺亚方舟实验室语音语义首席科学家刘群也在微博进行了答疑,披露了不少这只AI背后的故事:
其实我们也不懂诗,我们也没有用诗的规矩去训练这个系统,完全是系统自己学到的。
那么,这一AI到底是如何学的?论文已经公布。
理工男の文艺源自GPT
与自由生成文本不同,生成中国的古诗词是一个挑战,通常需要满足形式和内容两个方面的要求。
中国的古诗词有各种各样的形式,比如五绝、七绝、五律、七律、满江红、西江月、水调歌头等各种词牌以及对联,每一种都有相应的字数、押韵、平仄、对仗等规定;
内容方面虽然简单,但要求更加难以琢磨:一首诗要围绕着一个主题展开,内容上还要具有连贯性。
华为提出的“乐府”系统,与当前大多数解决方案不同,不需要任何人工设定规则或者特性,也没有设计任何额外的神经元组件。
整个研究中,需要做的就是把训练用的诗词序列化为格式化的文本序列,作为训练数据。
然后通过对语言模型token的抽样,生成满足形式和内容要求的诗词,比如绝句、律诗、词,以及对联等等。
而且,他们还提出并实现了一种对模型进行微调以生成藏头诗的方法。
这背后的能量来自GPT,一个由OpenAI提出的预训练自然语言模型,核心理念是先用无标签的文本去训练生成语言模型,然后再根据具体的任务通过有标签的数据对模型进行微调。
乐府AI是首个基于GPT打造的作诗系统,而且与谷歌提出的BERT息息相关。
整体的GPT模型是在BERT的源代码基础上实现的,Transformer大小的配置与BERT-Base相同,也采用了BERT中发布的tokenization 脚本和中文 vocab。
具体来说,训练诗歌生成模型的过程如下: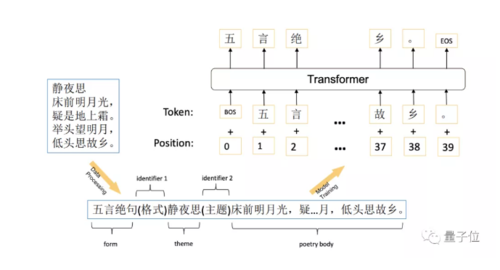
整个模型训练过程一共有两个阶段: 预训练和微调。
华为的这个GPT模型,是用一个中文新闻语料库进行预训练的,然后通过收集了公开可得的中国古诗词进行微调。
如上图所示,首先将示例诗歌转换为格式化序列。序列包括三个主要部分:格式、主题和诗体,中间用标识符分开。
在对联中,因为没有主题,就上句为主题,第二行为正文。所以,在生成对联的时候,就成了给出上联,生成下联的模式,也符合了“对对子”的习惯。
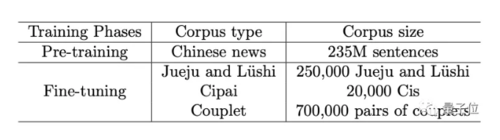
整体的数据集规模并不小,预训练用的中文新闻语料库,有2.35亿句子。微调用的数据集有25万绝句和律师,2万首词以及70万对对联。
预训练是在华为云上完成的,使用8块英伟达V100(16G) GPU训练了4个echo,一共耗费了90个小时。
微调的过程是将所有诗歌序列输入Transformer,并训练一个自回归语言模型。目标是观测任何序列的概率最大化:
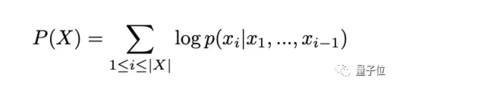
微调的过程,不需要特别长的时间,如果训练过长,这个模型就在生成过程中,就会倾向于从语料库中直接用原始句子了。
训练完成后,先将要生成的诗歌的格式和主题转化为一个初始序列,然后将初始序列输入到模型中,然后对诗体部分的剩余字段按token进行解码。
在解码过程中,并不使用硬约束来保证格式的正确性,而是让模型自动为特定位置分配逗号和句号,在识别到token为“EOS”的时候,解码过程结束。
而且,采用截断 top-k 抽样策略来获得不同的诗歌,而不是束搜索。具体是每次采样一个Token时,首先选择具有 top-k 最大概率的Token,然后从 top-k Token中采样一个特定的token。
他们说,即使采用截短的 top-k 抽样策略,生成的诗歌仍然是正确的形式。
论文中介绍称,训练藏头诗的方法也是这样,只是在格式化序列的时候方法有所不同:用每一行中第一个字符的组合来代替一首诗的原始主题:“五言绝句(格式)床疑举低(藏头诗)床前明月光,疑…月,低头思故乡。”
效果如何,华为也在论文中进行了充分的展示,比如下面这四首“江上田家”,只有一首是唐朝诗人写的,其他三首都是来自乐府AI。

从上到下,ABCD,你能辨别出来哪个是真迹吗?(答案在文末揭晓)
谁是第一AI诗人?
中国古诗词生成AI,华为“乐府”并不是第一个,也不是最后一个。
在此之前,就有清华大学孙茂松团队提出的“九歌”。

根据官方介绍,这一系统的采用深度学习技术,结合多个为诗歌生成专门设计的模型,基于超过80万首人类诗人创作的诗歌进行训练学习,具有多模态输入、多体裁多风格、人机交互创作模式等特点。
近日,也有人基于中文版的语料训练出了中文版的GPT-2,并将其用于诗歌生成。
就在“乐府”上线的这一天,还有北京大学、国防科大等机构联合发布了新的作诗模型,基于无监督机器翻译的方法,使用基于分段的填充和强化学习根据白话文生成七言律诗。
那么,哪一个更强呢?
因为中文版GPT-2和北京大学联队的系统还没有开放体验,参与这场“华山论剑”的就只有华为“乐府”和清华“九歌”两个选手。
第一轮:主题“夏日”,七言绝句
清华九歌赋诗一首:
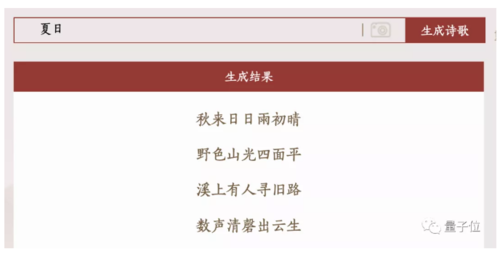
华为乐府赋诗是这样的:

两个AI都有瑕疵的地方,清华九歌一张嘴就开始说“秋来”,华为乐府也提到了“四月”,并没有特别的意思,显然都与夏日有些出入。
但相比之下,华为乐府的夏日元素也更多一些,比如荷香,夏阴等等。
第二轮:主题“长夜”,五言绝句
来自清华九歌的诗是这样的:

不须愁独坐,相对倍凄然?这个意境Emmm……婚姻要破裂了?
华为乐府的作品:

直观上来看,意境刻画不错,但冲击力有所不足。
这一轮,两个AI表现都不错,而且都有相应的意境体现出来。相对来说, 清华九歌的情感层次更丰富一些。
第三轮,藏头诗“神经网络”,七言绝句
清华九歌作品是这样的:

从押韵和意境来看,都还不错。华为乐府给出了这样一首诗:

同样,这首藏头诗也能够展现几分意境。
这一轮,两只AI都能较确切地完成任务,给出了具有几分意境的诗词。
至此,经过三轮比拼,整体上来说,高下难分。其差别,在于双方的实现方式。
清华九歌,基于多个为诗歌生成专门设计的模型,相对来说比较复杂,在诗歌的格式上,控制比较严格,虽然严肃但作诗速度的确比较慢。
而华为的乐府,只是基于GPT,按照刘群的话来说,他们也不懂诗歌,并没有用诗的规矩去训练这个系统,完全是系统自己学到的,生成诗歌的时候速度很快。
对于乐府AI生成的诗歌水平,刘群也颇为谦虚:
我们找过懂诗的人看,说韵律平仄并不完全符合规矩,只是外行读起来还比较顺口而已。
至于两种方式孰优孰劣,也不妨参考下那句老话:文无第一。
华为诺亚方舟实验室
华为诺亚方舟实验室成立于2012年,隶属于华为2012实验室。
诺亚方舟为名,也能体现出这一实验室在华为内部的重要性。此前,任正非也提到过,希望这些实验室能够成为华为的“诺亚方舟”。
目前,这一实验室在深圳、香港、北京、上海、西安、北美和欧洲等城市设有分部。研究方向包括计算机视觉、自然语言处理、搜索推荐、决策推理、人机交互、AI理论、高速计算等。
关于乐府AI,华为也在论文中标注说明,这是他们在研究GPT时的一个副产品。目前,华为乐府AI已经在小程序EI体验空间上线。
支持五言绝句、七言绝句、五言律诗和七言律诗,以及藏头诗模式。作词、对对子还没有上线。
最后,附上一首乐府生成的七言律诗人工智能。

对了,答案选C。
相关传送门:
乐府AI论文
GPT-based Generation for Classical Chinese Poetry
https://arxiv.org/pdf/1907.00151.pdf
清华九歌作诗网站:
http://118.190.162.99:8080/
— 完 —
共同学习,写下你的评论
评论加载中...
作者其他优质文章



