
线性回归
简单线性回归
机器学习三要素 – 模型 策略 算法
线性回归
输入空间为
模型:假设函数
模型参数:
思考:如何拟合模型参数 使得假设函数不断逼近实际值?
策略1 : 梯度下降法
设置代价函数 如果代价函数不断的减小 说明模型参数在不断的逼近实际值
已知
代价函数 :
假设函数与代价函数 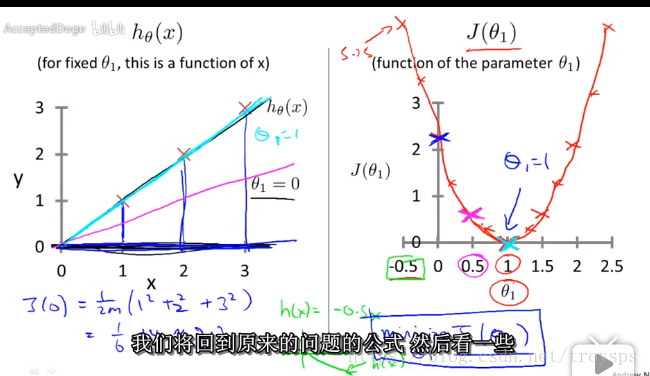
代价函数与代价函数轮廓图 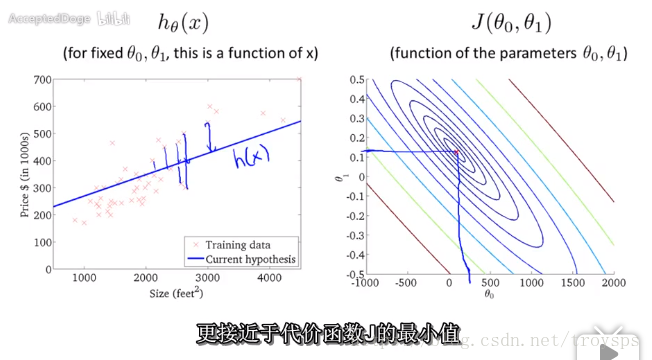
策略1: 梯度下降法
不断的迭代更新
注意点:学习速率选择
α表示迭代至稳定值的速率。当θ用公式进行迭代,两次迭代之间的Δθ的值小于某个值(一般可以用10-3),则可以认为代价函数已经最小。 对于α,可以使用下列数据进行测试: 0.001、0.01、0.1、1、10…,或者可以用0.001、0.003、0.01、0.03、0.1、0.3、1…,即可以用3倍或10倍的速度,将α的值慢慢调整到一个区间,再进行微调。123456
梯度下降法以及多元线性回归实现原理 
分析:
梯度下降法 
梯度下降法及代价函数 
算法实现:
简单线性回归
import numpy as np"""梯度下降法
---方法实现1 比实现2精度更高?
---为啥子
"""def createData():
x = [1, 2, 3, 4, 5, 6]
y = [13, 14, 20, 21, 25, 30] return x, y# 简单线性回归 实现def linearRegression(x, y):
"""
cost function min
同时更新theta0 theta1
目标:代价函数最小化
:param x: 特征值x
:param y: 目标变量y 实际值y
:return: h(x)
"""
epsilon = 0.01
error = 0 #
alpha = 0.001 # 步长
maxCycle = 20 # 最大迭代次数
count = 0
theta0 = 0
theta1 = 0
m = len(x) while True:
diff = [0, 0]
count += 1
for i in range(m):
diff[0] += theta0 + theta1 * x[i] -y[i]
diff[1] += (theta0 + theta1 * x[i] -y[i]) * x[i]
print('diff---------------------', diff)
theta0 = theta0 - alpha/m * diff[0]
theta1 = theta1 - alpha/m * diff[1]
print('theta0', theta0)
print('theta1', theta1)
error1 = 0
for i in range(m):
error1 += (theta0 + theta1 * x[i] - y[i]) ** 2
if abs(error1 - error) < epsilon: break
if count > 200: break
print(theta0, theta1, error1) return theta0, theta1, error1if __name__ == '__main__':
x, y = createData() # print(x) [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# print(y) [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
weights = linearRegression(x, y)
print(weights) # print(linearRegression2(x, y))用矩阵思维看数据集 优化算法 
算法优化
def linearRegression2(x, y): x = np.mat(x) y = np.mat(y) m, n = np.shape(x) print(m, n) weights = np.zeros((1, m+1)) print(np.shape(weights)) alpha = 0.0013 esplion = 70 maxCycle= 2000 count = 0 while True: count += 1 diff = [0, 0] diff[0] = np.sum(x.T * weights - y.T) print(diff[0]) diff[1] = np.sum((x.T * weights - y.T).T * x.T) print(diff[1]) print(diff) weights[0, 0] = weights[0, 0] - alpha/(2*n) * diff[0] print(weights) weights[0, 1] = weights[0, 1] - alpha/(2*n) * diff[1] error = np.sum(np.array(x.T * weights - y.T) ** 2) if error < esplion: break if count > maxCycle: break print(weights, '-------------------', error) return weights, error
策略2 : 标准方程法
标准方程法是与梯度下降法功能相似的算法,旨在获取使代价函数值最小的参数θ。代价函数公式如下:
代价函数 :
原理:在一个标准方程中求其最小值 求其偏导数 令值为0 就可以得到
根据上述代价函数,令J对每个θ的倒数都为0,可以解得
特殊情况
由于用标准方程法时,涉及到要计算矩阵XTX的逆矩阵。但是XTX的结果有可能不可逆。 当使用python的numpy计算时,其会返回广义的逆结果。 主要原因: 出现这种情况的主要原因,主要有特征值数量多于训练集个数、特征值之间线性相关(如表示面积采用平方米和平方公里同时出现在特征值中)。 因此,首先需要考虑特征值是否冗余,并且清除不常用、区分度不大的特征值。
3、比较标准方程法和梯度下降算法
这两个方法都是旨在获取使代价函数值最小的参数θ,两个方法各有优缺点: 1)梯度下降算法 优点:当训练集很大的时候(百万级),速度很快。 缺点:需要调试出合适的学习速率α、需要多次迭代、特征值数量级不一致时需要特征缩放。
2)标准方程法
优点:不需要α、不需要迭代、不需要特征缩放,直接解出结果。 缺点:运算量大,当训练集很大时速度非常慢。
4、综合
因此,当训练集百万级时,考虑使用梯度下降算法;训练集在万级别时,考虑使用标准方程法。在万到百万级区间时,看情况使用,主要还是使用梯度下降算法。
参考文献
机器学习(Machine Learning)- 吴恩达(Andrew Ng)
http://www.cnblogs.com/linhxx/p/8412687.html
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦