
Demo1:
from keras.preprocessing.text import text_to_word_sequence,one_hot,Tokenizer
from keras.preprocessing.sequence import pad_sequences
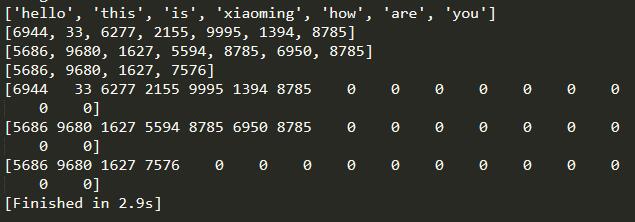
s1 = 'hello this is xiaoming! How are you ?'
s2 = 'I am fine thank you and you ?'
s3 = 'I am fine too !'
#英文分词
wordslist1 = text_to_word_sequence(s1)
wordslist2 = text_to_word_sequence(s2)
wordslist3 = text_to_word_sequence(s3)
print(wordslist1)
#one-hot
#vocab_size = 10000
oh1 = one_hot(s1,10000)
oh2 = one_hot(s2,10000)
oh3 = one_hot(s3,10000)
for each in [oh1,oh2,oh3]:
print(each)
#padding文本补齐:
pad_oh = pad_sequences([oh1,oh2,oh3],maxlen = 16,padding = 'post')
for each in pad_oh:
print(each)
Demo2:
from keras.preprocessing.text import text_to_word_sequence,one_hot,Tokenizer
from keras.preprocessing.sequence import pad_sequences
#词频统计,得到字典,文本向量化
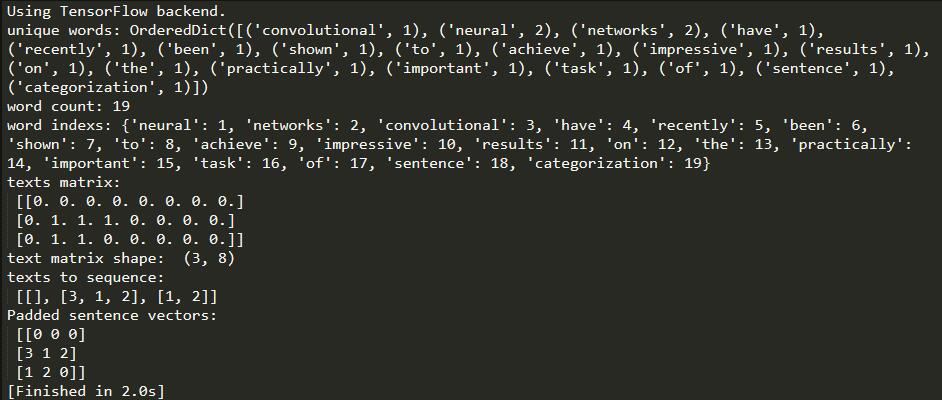
s1 = 'Evaluate on the evaluation data'
s2 = 'Convolutional Neural Networks for Sentence Classification models'
s3 = 'Sentence Classifications with Neural Networks'
#原始语料库
corpus = 'Convolutional Neural Networks Neural Networks have recently \
been shown to achieve impressive results \
on the practically important task of sentence categorization'
#在进行向量表示的时候,会只表示最常见的most_freq_num个词。当然,可以不设置。
most_freq_num = 8
t = Tokenizer(most_freq_num)
#利用语料库进行训练,学习关于这个语料的统计信息
t.fit_on_texts([corpus])
#得到所有词的一个词频统计字典
word_c = t.word_counts
print("unique words:",word_c)
print("word count:",len(word_c))
#给每个词都分配一个index,按照在语料库出现的词频来排序
word_indexs = t.word_index
print("word indexs:",word_indexs)
#将一系列句子转化成矩阵。选择count模式,则得到的每句子对应的行表示是“最常见的most_freq_num个词各自的词频”
#例如,[0. 2. 1. 1. 0. 0.] 表示的是最常见的6个词分别出现了0,2,1,1,0,0次。
t_matrix = t.texts_to_matrix([s1,s2,s3],mode = 'count')
print("texts matrix: \n",t_matrix)
print("text matrix shape: ",t_matrix.shape)
#将一系列句子转化成由词的index构成的向量。其中,不到most_freq_num的词则为空值
text_sequence = t.texts_to_sequences([s1,s2,s3])
print("texts to sequence: \n",text_sequence)
#将各个向量pad一下,得到定长的sentence
text_pad = pad_sequences(text_sequence,padding = 'post')
print("Padded sentence vectors: \n",text_pad)
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦