
相比于逻辑回归,在很多情况下,SVM算法能够对数据计算从而产生更好的精度。而传统的SVM只能适用于二分类操作,不过却可以通过核技巧(核函数),使得SVM可以应用于多分类的任务中。
本篇文章只是介绍SVM的原理以及核技巧究竟是怎么一回事,最后会介绍sklearn svm各个参数作用和一个demo实战的内容,尽量通俗易懂。至于公式推导方面,网上关于这方面的文章太多了,这里就不多进行展开了~
1.SVM简介
支持向量机,能在N维平面中,找到最明显得对数据进行分类的一个超平面!看下面这幅图:
如上图中,在二维平面中,有红和蓝两类点。要对这两类点进行分类,可以有很多种分类方法,就如同图中多条绿线,都可以把数据分成两部分。
但SVM做的,是找到最好的那条线(二维空间),或者说那个超平面(更高维度的空间),来对数据进行分类。这个最好的标准,就是最大间距。
至于要怎么找到这个最大间距,要找到这个最大间距,这里大概简单说一下,两个类别的数据,到超平面的距离之和,称之为间隔。而要做的就是找到最大的间隔。
这最终就变成了一个最大化间隔的优化问题。
2.SVM的核技巧
核技巧,主要是为了解决线性SVM无法进行多分类以及SVM在某些线性不可分的情况下无法分类的情况。
比如下面这样的数据:
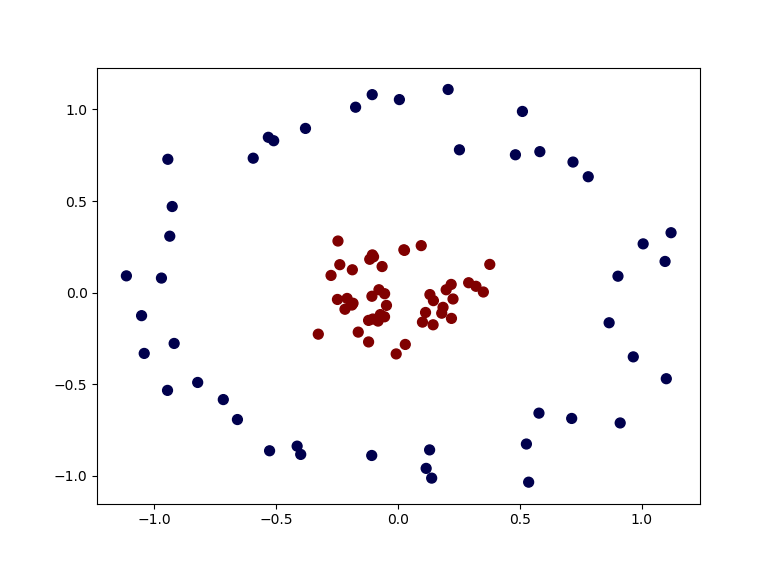
这种时候就可以使用核函数,将数据转换一下,比如这里,我们手动定义了一个新的点,然后对所有的数据,计算和这个新的点的欧式距离,这样我们就得到一个新的数据。而其中,离这个新点距离近的数据,就被归为一类,否则就是另一类。这就是核函数。
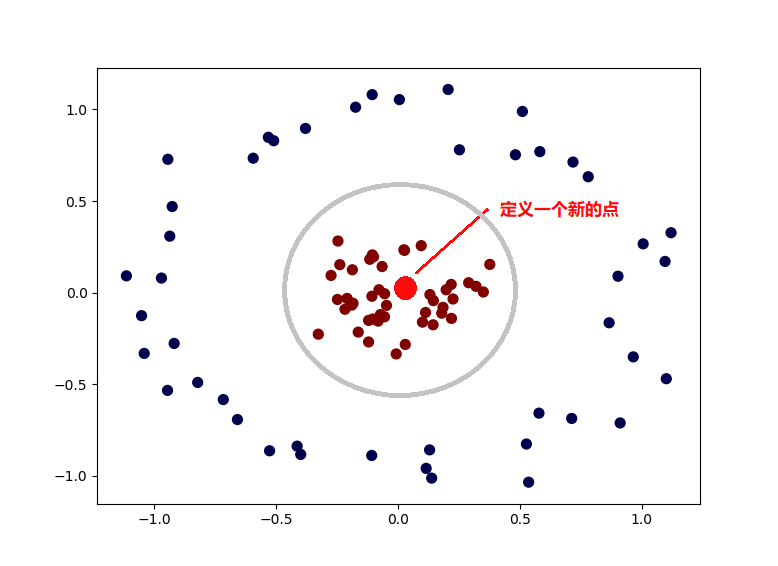
这是最粗浅,也是比较直观的介绍了。通过上面的介绍,是不是和Sigmoid有点像呢?都是通过将数据用一个函数进行转换,最终得到结果,其实啊,Sigmoid就是一钟核函数来着,而上面说的那种方式,是高斯核函数。
这里补充几点:
- 1.上面的图中只有一个点,实际可以有无限多个点,这就是为什么说SVM可以将数据映射到多维空间中。计算一个点的距离就是1维,2个点就是二维,3个点就是三维等等。。。
- 2.上面例子中的红点是直接手动指定,实际情况中可没办法这样,通常是用随机产生,再慢慢试出最好的点。
- 3.上面举例这种情况属于高斯核函数,而实际常见的核函数还有多项式核函数,Sigmoid核函数等等。
OK,以上就是关于核技巧(核函数)的初步介绍,更高级的这里也不展开了,网上的教程已经非常多了。
接下来我们继续介绍sklearn中SVM的应用方面内容。
3.sklearn中SVM的参数
def SVC(C=1.0,
kernel='rbf',
degree=3,
gamma='auto_deprecated',
coef0=0.0,
shrinking=True,
probability=False,
tol=1e-3,
cache_size=200,
class_weight=None,
verbose=False,
max_iter=-1,
decision_function_shape='ovr',
random_state=None)
- C:类似于Logistic regression中的正则化系数,必须为正的浮点数,默认为 1.0,这个值越小,说明正则化效果越强。换句话说,这个值越小,越训练的模型更泛化,但也更容易欠拟合。
- kernel:核函数选择,比较复杂,稍后介绍
- degree:多项式阶数,仅在核函数选择多项式(即“poly”)的时候才生效,int类型,默认为3。
- gamma:核函数系数,仅在核函数为高斯核,多项式核,Sigmoid核(即“rbf“,“poly“ ,“sigmoid“)时生效。float类型,默认为“auto”(即值为 1 / n_features)。
- coef0:核函数的独立项,仅在核函数为多项式核核Sigmoid核(即“poly“ ,“sigmoid“)时生效。float类型,默认为0.0。独立项就是常数项。
- shrinking:不断缩小的启发式方法可以加快优化速度。 就像在FAQ中说的那样,它们有时会有所帮助,有时却没有帮助。 我认为这是运行时问题,而不是收敛问题。
- probability:是否使用概率评估,布尔类型,默认为False。开启的话会评估数据到每个分类的概率,不过这个会使用到较多的计算资源,慎用!!
- tol:停止迭代求解的阈值,单精度类型,默认为1e-3。逻辑回归也有这样的一个参数,功能都是一样的。
- cache_size:指定使用多少内存来运行,浮点型,默认200,单位是MB。
- class_weight:分类权重,也是和逻辑回归的一样,我直接就搬当时的内容了:分类权重,可以是一个dict(字典类型),也可以是一个字符串"balanced"字符串。默认是None,也就是不做任何处理,而"balanced"则会去自动计算权重,分类越多的类,权重越低,反之权重越高。也可以自己输出一个字典,比如一个 0/1 的二元分类,可以传入{0:0.1,1:0.9},这样 0 这个分类的权重是0.1,1这个分类的权重是0.9。这样的目的是因为有些分类问题,样本极端不平衡,比如网络攻击,大部分正常流量,小部分攻击流量,但攻击流量非常重要,需要有效识别,这时候就可以设置权重这个参数。
- verbose:输出详细过程,int类型,默认为0(不输出)。当大于等于1时,输出训练的详细过程。仅当"solvers"参数设置为"liblinear"和"lbfgs"时有效。
- max_iter:最大迭代次数,int类型,默认-1(即无限制)。注意前面也有一个tol迭代限制,但这个max_iter的优先级是比它高的,也就如果限制了这个参数,那是不会去管tol这个参数的。
- decision_function_shape:多分类的方案选择,有“ovo”,“ovr”两种方案,也可以选则“None”,默认是“ovr”,详细区别见下面。
- random_state:随时数种子。
sklearn-SVM参数,kernel特征选择
kernel:核函数选择,字符串类型,可选的有“linear”,“poly”,“rbf”,“sigmoid”,“precomputed”以及自定义的核函数,默认选择是“rbf”。各个核函数介绍如下:
“linear”:线性核函数,最基础的核函数,计算速度较快,但无法将数据从低维度演化到高维度
“poly”:多项式核函数,依靠提升维度使得原本线性不可分的数据变得线性可分
“rbf”:高斯核函数,这个可以映射到无限维度,缺点是计算量比较大
“sigmoid”:Sigmoid核函数,对,就是逻辑回归里面的那个Sigmoid函数,使用Sigmoid的话,其实就类似使用一个一层的神经网络
“precomputed”:提供已经计算好的核函数矩阵,sklearn不会再去计算,这个应该不常用
“自定义核函数”:sklearn会使用提供的核函数来进行计算
说这么多,那么给个不大严谨的推荐吧
样本多,特征多,二分类,选择线性核函数
样本多,特征多,多分类,多项式核函数
样本不多,特征多,二分类/多分类,高斯核函数
样本不多,特征不多,二分类/多分类,高斯核函数
当然,正常情况下,一般都是用交叉验证来选择特征,上面所说只是一个较为粗浅的推荐。
sklearn-SVM参数,多分类方案
其实这个在逻辑回归里面已经有说过了,这里还是多说一下。
原始的SVM是基于二分类的,但有些需求肯定是需要多分类。那么有没有办法让SVM实现多分类呢?那肯定是有的,还不止一种。
实际上二元分类问题很容易推广到多元逻辑回归。比如总是认为某种类型为正值,其余为0值。
举个例子,要分类为A,B,C三类,那么就可以把A当作正向数据,B和C当作负向数据来处理,这样就可以用二分类的方法解决多分类的问题,这种方法就是最常用的one-vs-rest,简称OvR。而且这种方法也可以方便得推广到其他二分类模型中(当然其他算法可能有更好的多分类办法)。
另一种多分类的方案是Many-vs-Many(MvM),它会选择一部分类别的样本和另一部分类别的样本来做二分类。
听起来很不可思议,但其实确实是能办到的。比如数据有A,B,C三个分类。
我们将A,B作为正向数据,C作为负向数据,训练出一个分模型。再将A,C作为正向数据,B作为负向数据,训练出一个分类模型。最后B,C作为正向数据,C作为负向数据,训练出一个模型。
通过这三个模型就能实现多分类,当然这里只是举个例子,实际使用中有其他更好的MVM方法。限于篇幅这里不展开了。
MVM中最常用的是One-Vs-One(OvO)。OvO是MvM的特例。即每次选择两类样本来做二元逻辑回归。
对比下两种多分类方法,通常情况下,Ovr比较简单,速度也比较快,但模型精度上没MvM那么高。MvM则正好相反,精度高,但速度上比不过Ovr。
4.sklearn SVM实战
我们还是使用鸢尾花数据集,不过这次只使用其中的两种花来进行分类。首先准备数据:
import matplotlib.pyplot as plt
import numpy as np
from sklearn import svm,datasets
import pandas as pd
tem_X = iris.data[:, :2]
tem_Y = iris.target
new_data = pd.DataFrame(np.column_stack([tem_X,tem_Y]))
#过滤掉其中一种类型的花
new_data = new_data[new_data[2] != 1.0]
#生成X和Y
X = new_data[[0,1]].values
Y = new_data[[2]].values
然后用数据训练,并生成最终图形
# 拟合一个SVM模型
clf = svm.SVC(kernel='linear')
clf.fit(X, Y)
# 获取分割超平面
w = clf.coef_[0]
# 斜率
a = -w[0] / w[1]
# 从-5到5,顺序间隔采样50个样本,默认是num=50
# xx = np.linspace(-5, 5) # , num=50)
xx = np.linspace(-2, 10) # , num=50)
# 二维的直线方程
yy = a * xx - (clf.intercept_[0]) / w[1]
print("yy=", yy)
# plot the parallels to the separating hyperplane that pass through the support vectors
# 通过支持向量绘制分割超平面
print("support_vectors_=", clf.support_vectors_)
b = clf.support_vectors_[0]
yy_down = a * xx + (b[1] - a * b[0])
b = clf.support_vectors_[-1]
yy_up = a * xx + (b[1] - a * b[0])
# plot the line, the points, and the nearest vectors to the plane
plt.plot(xx, yy, 'k-')
plt.plot(xx, yy_down, 'k--')
plt.plot(xx, yy_up, 'k--')
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=80, facecolors='none')
plt.scatter(X[:, 0].flat, X[:, 1].flat, c='#86c6ec', cmap=plt.cm.Paired)
# import operator
# from functools import reduce
# plt.scatter(X[:, 0].flat, X[:, 1].flat, c=reduce(operator.add, Y), cmap=plt.cm.Paired)
plt.axis('tight')
plt.show()
最终的SVM的分类结果如下: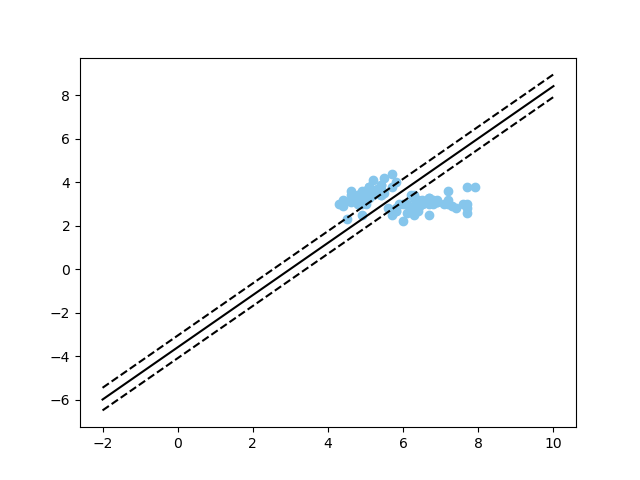
以上~
共同学习,写下你的评论
评论加载中...
作者其他优质文章



