
事故
一个风和日丽的下午,程序员小齐和往常一样,正在写bug。。。

突然接到客服那边的消息,说接到大量用户投诉,页面打不开了。小齐心里一咯噔,最近就自己发布了新代码,加了一个新功能,不会是那部分代码出问题了吧?!!

赶紧切流到备库,回滚代码。然后查看错误日志,发现数据库连接池报了大量的超时错误,这种情况一般有两种可能:
-
一种是数据库或者连接数据库的网络发生了某种意外,导致数据库连接不上了,达到超时时间了;
-
另一种可能是有大量线程执行慢查询,老线程还在执行查询,新线程只能陷入等待,等待太久达到超时时间了。
最终定位到是数据库慢查询的问题导致的这个故障。一个高频查询没有命中索引,导致全表扫描,单个查询最少就需要一秒多,所以大量查询请求堆积,超时。
复盘
痛定思痛,小齐决定在本地复盘一下这个故障。
首先,来一个极其简单的demo表,再创建一个错误的索引age, score:
create table demo
(
id int auto_increment
primary key,
name varchar(255) null,
age int null,
score int null
);
create index idx_age_score
on demo (age, score);
开启慢SQL日志:
SET GLOBAL slow_query_log=1;
然后,用python撸一个500w条随机数据的SQL文件,出问题的那个线上表也差不多就这个量级:
import random
if name == ‘main’:
SQL_file = open(’./batch_jq.SQL’, ‘w’, encoding=‘utf-8’)
a1 = [‘张’, ‘金’, ‘李’, ‘王’, ‘赵’]
a2 = [‘玉’, ‘明’, ‘龙’, ‘芳’, ‘军’, ‘玲’]
a3 = [’’, ‘立’, ‘玲’, ‘’, ‘国’, ‘’]
_len = 5000 # 5k次循环
while _len >= 1:
line = 'insert into demo(name, age, score) values '
arr = []
每次批量插入1k条
for i in range(1, 1001):
name=random.choice(a1)+random.choice(a2)+random.choice(a3)
arr.append((name, random.randint(1, 100), random.randint(1, 10000000)))
_SQL = line + str(arr).strip(’[]’)
SQL_file.write(_SQL + ‘;\n’)
_len -= 1
PS:这里用的是批量插入,而不是一条一条插数据,这样在运行SQL的时候能快一点点。
然后运行SQL插入500w条数据:
…
[2020-04-19 20:05:22] 24000 row(s) affected in 636 ms
…
[2020-04-19 20:05:23] 24000 row(s) affected in 638 ms
.
[2020-04-19 20:05:23] 8000 row(s) affected in 193 ms
[2020-04-19 20:05:23] Summary: 5000 of 5000 statements executed in 3 m 42 s 989 ms (106742400 symbols in file)
然后用SpringBoot + JdbcTemplate撸一个简单的应用程序:
@RestController
public class DemoController {
private static final Logger LOGGER = LoggerFactory.getLogger(DemoController.class);
@Resource
private JdbcTemplate jdbcTemplate;
// 引发慢查询业务的入口
@GetMapping(“trigger”)
public String trigger() {
long before = System.currentTimeMillis();
jdbcTemplate.query(“select * from demo.demo where score < 20 limit 50”, (set) -> {
});
long after = System.currentTimeMillis();
LOGGER.info(“调用时间: {} ms”, after - before);
return “success”;
}
}
尝试调用了一下http://localhost:8080/trigger,发现差不多用了一秒多。虽然慢了点,但是还能接受。
于是上ab压测一下:
$ ab -n500 -c20 http://localhost:8080/trigger
代表共500请求,每次并发数量为20
这一压测,发现日志打印出的时间基本上在15秒左右,虽然已经很慢了,但没有报错,业务也还能正常用一用,而且数据库里也没有慢查询:
2020-04-19 20:56:21.665 INFO 18908 — [nio-8080-exec-3] c.e.s.controller.DemoController : 调用时间: 15260 ms
2020-04-19 20:56:21.779 INFO 18908 — [io-8080-exec-10] c.e.s.controller.DemoController : 调用时间: 15445 ms
…
再加大一点并发数量:
$ ab -n500 -c50 http://localhost:8080/trigger
代表共500请求,每次并发数量为50
这个时候可以看到控制台打印出的调用时间慢慢激增,然后开始打印出一些异常信息:
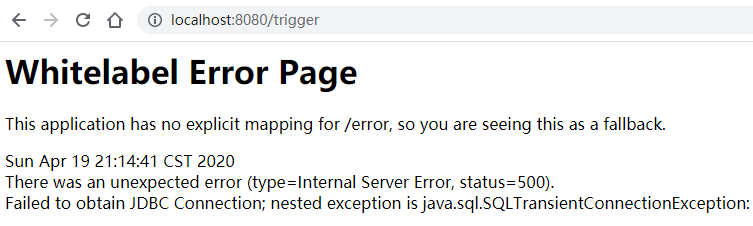
2020-04-19 21:02:55.277 ERROR 17100 — [io-8080-exec-45] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is java.SQL.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30000ms.] with root cause
java.SQL.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30000ms.
at com.zaxxer.hikari.pool.HikariPool.createTimeoutException(HikariPool.java:689) ~[HikariCP-3.4.2.jar:na]
at com.zaxxer.hikari.pool.HikariPool.getConnection(HikariPool.java:196) ~[HikariCP-3.4.2.jar:na]
示例代码用的SpringBoot自带的数据库连接池Hikari,默认超时时间是30秒,如果超过30秒就会抛出异常。不论什么连接池,虽然功能可能有些许不同,但基本上都会有超时时间这个配置。
这个时候在数据库里也多了一些慢SQL记录:
SHOW GLOBAL STATUS LIKE ‘%Slow_queries%’;
| Slow_queries | 51 |
接下来是问题定位,执行下列SQL可以打印出当前的连接状态,可以看看是什么SQL语句在占用时间:
SHOW FULL processlist;
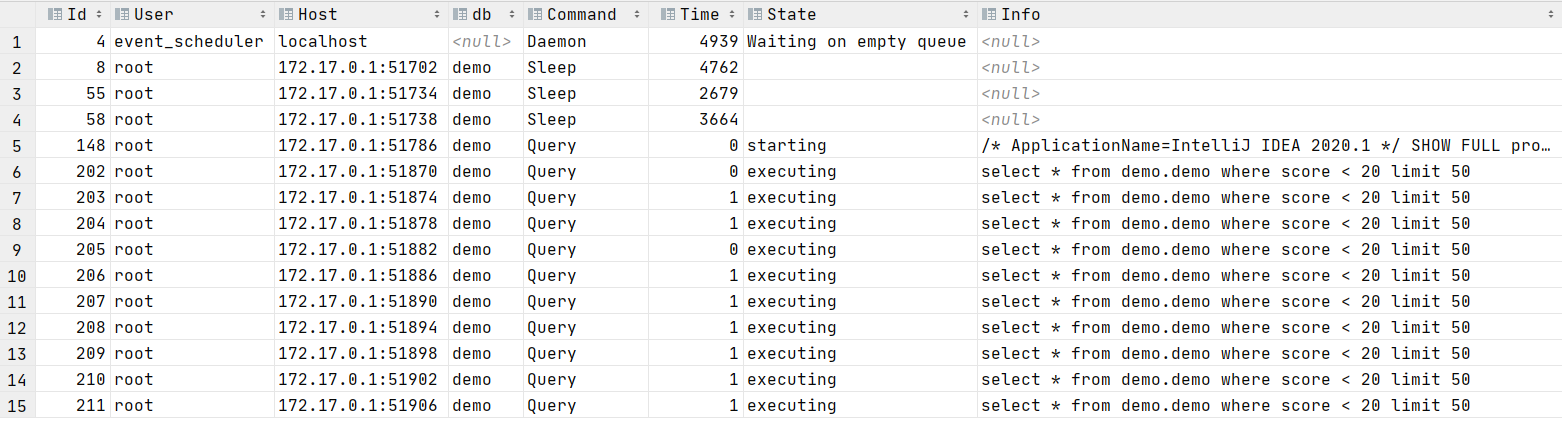
可以很轻易地发现我们的SQL执行时间超过了1秒。我们拿着这个SQL去explain一下,发现走的是全表扫描。
当然了,实际项目的表并不是这么简单,SQL语句和索引也更加复杂,这里只是为了演示方便创建了一个简单的实例。
而且现在有很多优秀的数据库监控工具,能够更方便美观地展示日志和排查数据库问题,比如阿里的Druid等。
调优后,在本地同样用50并发压测一次,发现响应时间基本上维持在十几毫秒左右,完全无压力。
调优
使用索引
很多时候,慢SQL都可以通过使用索引来解决。
通过问题定位我们发现,我们对于某一个字段有高频的查询需求,但没有为其建索引。MySQL的索引都是“最左匹配原则”,所以现有的联合索引age, score并不能命中我们的这个高频查询。
当然了,建太多索引也是有弊端的,这个根据自己的业务来就好。
使用缓存
通过分析我们发现,这些慢SQL其实执行的查询条件都是一模一样的。也就是说,我们可以把查询结果放到缓存里,这样后续的查询就可以直接去缓存取,可以大幅提升性能。
其实现在主流的ORM框架都是支持缓存的,甚至可以多级缓存,Spring也提供了缓存框架Spring Cache可以根据自己的需要去配置和使用。
反思
复盘与调优完了,接下来就到了面壁思过的时间了。

利用好explain
我们的SQL语句,在使用前可以尽量先explain一下,看有没有命中索引,如果没有命中,考虑一下是不是高频语句,是不是需要调优。
进行充分的压测
线上无小事,切勿盲目自信,认为自己写的程序就一定没有问题,直接部署到生产环境。如果能够在上线之前做一些压测,就能够尽早发现性能问题,及时止损。
利用好日志和监控
通常情况下,我们是在晚上等用户使用量低的时候发布上线的。如果我们能够配置好错误日志的采集、以及数据库监控与告警,或许就能赶在大量用户发现之前注意到这个问题。那就可以尽早解决,减小用户和公司的损失。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


