
前两天逛豆瓣,发现有些影评确实精彩,但是有些就。。。于是乎,就简单的爬了下豆瓣最受欢迎的影评,来看看受欢迎的影评都是何方大神写的。
使用到的页面
先来看看,我们准备对哪几个页面下手
一、最受欢迎影评页面
https://movie.douban.com/review/best/
在这个页面,我们主要要拿到的数据有:
用户名称
用户评论 ID
有用数量
无用数量
回复数量
用户主页 URL
二、用户影评页面
https://movie.douban.com/review/9593388/
抓取用户的影评内容
三、用户主页
https://www.douban.com/people/132758789/
抓取用户的位置信息
按页面写代码
最受欢迎影评页面
可以看到总共才三页,每页的 URL 也是按照20这个步长来递增的,所以我们循环访问这三个页面,并抓取想要的信息:
1 start = ['0', '20', '40']
2 base = 'https://movie.douban.com/review/best/?start='
3 details = []
4 for i in start:
5 url = base + i
6 response = requests.get(url).text
7 content = BeautifulSoup(response, "html.parser")
8 tmpid = content.find_all('div', attrs={'class': 'main review-item'})
9 for k in tmpid:
10 div_id = content.find('div', attrs={'id': k['id']})
11 name = div_id.find('a', attrs={'class': 'name'}).text
12 youyong = div_id.find('span', attrs={'id': 'r-useful_count-' + k['id']}).text.split('\n')[1].strip(' ')
13 wuyong = div_id.find('span', attrs={'id': 'r-useless_count-' + k['id']}).text.split('\n')[1].strip(' ')
14 reply = div_id.find('a', attrs={'class': 'reply'}).text.replace('回应', '')
15 user = div_id.find('header', attrs={'class': 'main-hd'}).find('a', attrs={'class': 'avator'})['href']
16 details.append([name, k['id'], youyong, wuyong, reply, user])
用户影评页面和用户主页
在这两个页面我们分别抓取用户的影评和所在位置
1 for i in details:
2 res = requests.get('https://movie.douban.com/review/' + i[1]).text
3 content = BeautifulSoup(res, "html.parser")
4 review = content.find('div', attrs={'id': 'link-report'}).text.strip('\n').replace(',', ',').replace('\n', ' ')
5 star_span = content.find('span', attrs={'class': 'main-title-hide'})
6 if star_span is None:
7 star = 3
8 else:
9 star = star_span.text
10 header_link = content.find('header', attrs={'class': 'main-hd'}).find_all('a')
11 movie_name = header_link[1].text
12 movie_link = header_link[1]['href']
13 res2 = requests.get(i[5]).text
14 content2 = BeautifulSoup(res2, "html.parser")
15 try:
16 user_local = content2.find('div', attrs={'class': 'user-info'}).find('a').text.replace(',', ',')
17 i.append(user_local)
18 i.append(star)
19 i.append(movie_name)
20 i.append(movie_link)
21 i.append(review)
22 except:
23 user_local = "未知"
24 i.append(user_local)
25 i.append(star)
26 i.append(movie_name)
27 i.append(movie_link)
28 i.append(review)
29 continue
由于有些用户并没有设置位置信息,对于这种用户直接设置为”未知“
同时对于无法获取到 star 的用户,默认设置为 star = 3
获取电影的总体 star 数量
1def get_movie_star(details):
2 print('start get movie star')
3 for i in details:
4 res = requests.get(i[-2]).text
5 content = BeautifulSoup(res, "html.parser")
6 div_class = content.find('div', attrs={'class': 'rating_right '}).div['class']
7 movie_star = div_class[2][-2:]
8 i.append(movie_star)
9 print('finish get movie star')
10 return details
保存到 csv
写个函数,把数据放进去:
1def save_csv(review):
2 print('start save to csv')
3 with open('best_review.csv', 'w', encoding='utf-8') as f:
4 f.write('name,id,youyong,wuyong,reply,user,local,review\n')
5 for i in review:
6 try:
7 rowcsv = '{},{},{},{},{},{},{},{}'.format(i[0], i[1], i[2], i[3], i[4], i[5], i[6], i[7])
8 f.write(rowcsv)
9 f.write('\n')
10 except:
11 continue
12 print('finish save to csv')
简单分析
数据拿到了,下面基本是使用 pyechart 来作图分析的。
首先看看是哪些大神的评论这么受欢迎了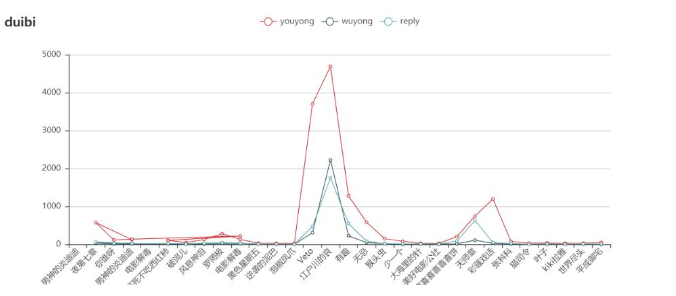
可以看到,江户川的悲哀,啊没有悲是点赞数量最多的,相应的点”无用“的数量也是最多,当然回复量也最高。
下面再看看这些最受欢迎的影评都包含哪些词呢
那江户川的哀又喜欢使用哪些词呢
再来看看各大神的地域分布情况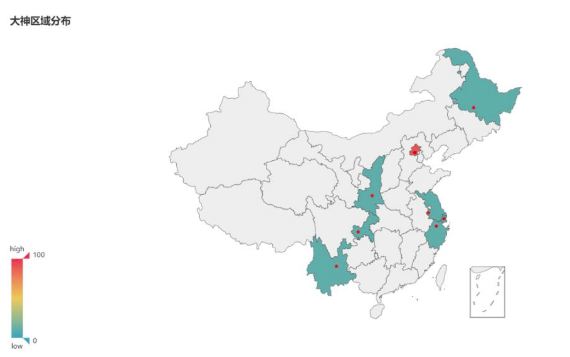
毫无疑问,北京地区,物华天宝,人杰地灵!
最后再看看大神们的评分会不会影响该电影的总体分数呢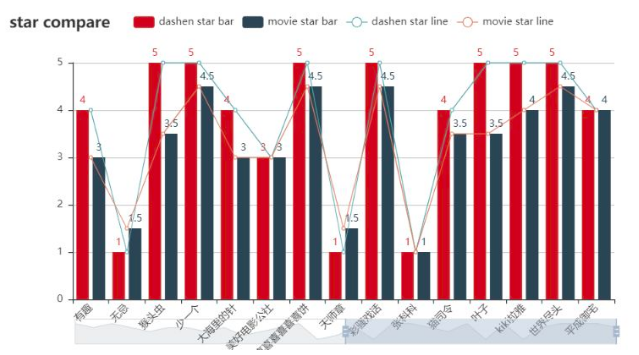
其实能够大致看出,大神们的评分与电影总体分数基本一致,虽然这并不能说明这些大神真的能左右某个电影的评分,但是大神的评分,也基本可以反应出广大影迷们对电影的评价了。
最后再放上源码的 GitHub 地址:
共同学习,写下你的评论
评论加载中...
作者其他优质文章



