
背景介绍–公司介绍
茄子科技(海外 SHAREit Group)是一家全球化互联网科技公司,主要从事移动互联网软件研发与全球移动广告变现解决方案、跨境支付解决方案等互联网服务等业务。茄子快传(SHAREit)是茄子科技旗下的代表产品, 是一款一站式数字娱乐内容与跨平台资源分享平台,累计安装用户数近 24 亿。茄子科技作为一家出海企业,已经在东南亚、南亚、中东以及非洲等地区,打造了多款工具和内容的应用,并且在 Google Play 的下载榜上常年名列前茅。
背景介绍–业务特点及选型
茄子科技的产品矩阵较多,产品形态相对比较复杂,包括了工具、内容、游戏、广告、支付等。针对相对复杂的业务场景,根据不同的业务形态,我们做了不同的数据库选型。目前,茄子科技使用的六款最主要的数据库包括:
- 自研持久化 KV:特征平台、用户画像、行为记录等
- Redis Cluster:业务缓存、session 信息等
- Cassandra:内容库
- MySQL: Hue、Metadata、运营平台等
- ClickHouse:数据分析、实时报表
- TiDB:用户增长、APM 系统、云账单等
TiDB的应用实践–业务痛点及TiDB的优势
基于业务层面的痛点思考,我们在多个业务场景引入了 TiDB:
第一,茄子科技作为一家出海企业引入了多家公有云作为基础设施,所以在数据库的层面,要考虑业务在多云架构下的业务适配、数据迁移、数据库的兼容以及数据同步的问题。
第二,茄子有多款高流量的 APP 产品,业务呈现高速增长的态势,传统的 DRS 数据库,比如 MySQL,因为需要分库分表,阻碍业务快速发展。
第三,Cassandra、HBase 等 NoSQL 数据库,无法满足分布式事务,多表 join 等复杂场景。
茄子科技的 APM 等系统,有一些是 HTAP 场景,同一份业务数据既有 OLTP 又有 OLAP 的需求,我们希望一套数据库可以搞定。
引入 TiDB 之后,TiDB 在多个方面发挥出独特优势,帮助茄子科技打造可持续发展的数据库生态:
- 利用 TiDB 的跨集群迁移、数据同步的能力打造多云架构下的业务扩展能力,满足多云架构下的业务架构设计。
- TiDB 提供自动水平弹性扩展的能力,做到业务无感知,解决分库分表的问题。
- TiDB 高度兼容 MySQL,在大容量、高并发的场景下学习成本低、迁移成本低。
- 利用 TiDB HTAP 的能力,满足业务在一份数据上的 OLTP 与 OLAP 的双重需求。
TiDB的应用实践–APM 场景应用
茄子科技的 APM(Application Performance Management)系统提供 APP 崩溃、性能等问题的监控、分析、看板、修复的一体化能力,用来支撑多款高增长的 APP 应用。这个系统的第一个特点就是信息量大,每天产生百亿条的数据,需要保留 30 天;第二个特点是时效性要求比较高,针对一些比较棘手的情况,比如说崩溃以及严重的性能问题,如果时效性不能满足的话会直接影响到用户的体验,甚至是产品的营收;第三个特点是需要打通工单系统,提供问题追踪、修复的一体化能力;第四个特点是在 OLTP 事务场景的基础上需要兼顾 OLAP 的分析场景。
首先分析一下早期 APM 的数据流转,从 APP 数据上报到日志收集,最后到 ClickHouse,整个数据流转是一个类似批处理的流程,大概需要两个多小时,整体时效性偏弱,问题暴露不及时,会对用户体验产生影响。另外,这套系统里面有 MySQL 和 ClickHouse 两套数据库。为什么这么设计?因为 ClickHouse 可以用来做数据的分析聚合,MySQL 主要是用来打造流程工单,同时有两套数据库在支撑,在成本上比较高。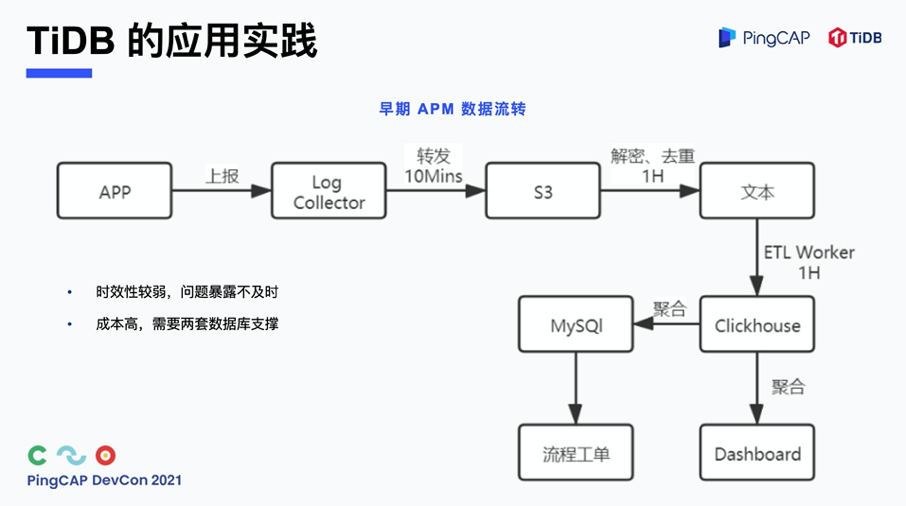
再来看引入了 TiDB 之后的新版 APM 数据流转,可以看到从 APP 的上报,到看板展示,到报警,再到流程工单,实现分钟级的准实时看版展示和报警。这部分主要是借助了 TiDB 的 HTAP 能力,通过聚合分析向看版进行展示,向报警中心进行及时的报警。同时,利用 TiDB 的 OLTP 能力进行看板的行更新。所以,我们可以通过一套 TiDB 数据库打通看版、监控、问题的追踪和修复流程。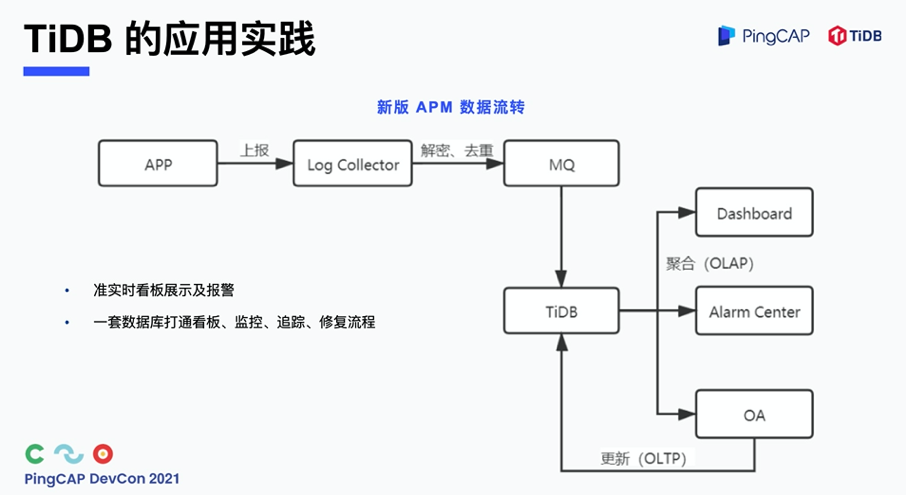
基于 TiKV的演进 – 自研分布式 KV
大家知道 TiKV 是 TiDB 的存储层,同时也是一个 Key-Value 数据库,接下来谈谈茄子科技基于 TiKV 打造分布式 KV 系统的历程。茄子科技主要是提供工具和内容产品,产生的数据量非常大,KV 存储需要支撑两类场景:一类是数据的实时产生,实时写入;另一类是针对用户画像和特征引擎,将离线产生的大批量数据快速地加载到在线的 KV 存储,为在线业务提供快速的访问,即 Bulk Load 能力,实际业务中需要每小时 TB 级的吞吐量。
下图是茄子科技之前基于 Rocksdb 自研的分布式 KV,这个系统同时满足上述的两类对 KV 的需求。图中左边展示的架构主要是实时写入能力的实现,数据先从 SDK 到网络协议层,然后到拓扑层,再到数据结构的映射层,最后到 Rocksdb。右边是 Bulk Load 批量导入的流程。大家可能有一个疑问,为什么左边实时的写入流程不能满足小时级 TB 数据导入?主要原因有两点:一是因为 Rocksdb 的写放大,尤其在大key型场景下,Rocksdb写放大是非常严重的。另一点是受限于单块盘的网络带宽,导致了单机负载或者单机存储是有限的。右边整个批量导入的能力是怎么实现的?它是通过 Spark 把 Parquet 进行数据解析、预分片以及 SST 生成,把 SST 上传到 Rocksdb 的存储节点,最后通过 ingest & compact 统一加载到 KV 层,供在线的业务进行访问,单机吞吐每秒种可以达到百兆。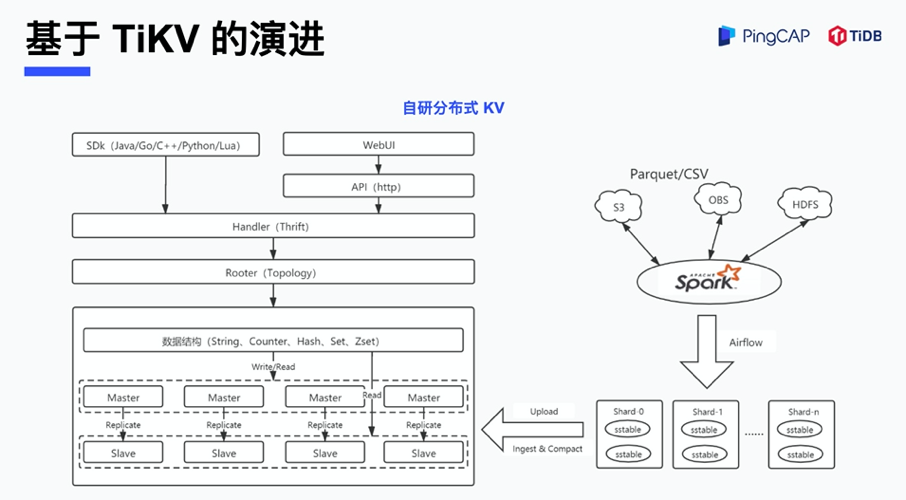
基于 TiKV的演进 – 基于TiKV的分布式KV
茄子科技既然已经自研了基于 Rocksdb 的分布式 KV,为什么还要用到 TiKV ?首先在技术层面,虽然自研分布式 KV 在生产已经运行了两年多的时间,支撑了上百 TB 的数据,但是有些技术问题,比如自动弹性升缩、强一致性、事务和大 key 等支持上还需要进一步投入研发。第二,在人才层面针对高质量数据库人才储备还有一定的欠缺。经过多次调研以及和 TiKV 研发同学的沟通,发现我们的需求和痛点与 TiKV 的产品规划是不谋而合的,这就促使了我们积极地拥抱 TiKV。我们借助 TiKV 可以在技术上打造存储与计算分离的 KV 产品。第三,TiKV 拥有活跃的开源社区,我们可以借助社区的力量共同打磨产品。
下图中的架构是茄子科技基于 TiKV 打造的一款分布式 KV。左侧部分主要是解决数据实时写入的一个流程,从 SDK 到网络存储,到数据计算,最后到 TiKV 的存储引擎。我们重点的研究方向是右侧部分整个 Bulk Load 能力的研发,与自研的分布式 KV 的不同,把整个 SST 的生成流程放在 TiKV 内部去做,这样做的原因是可以最大化地减少 Spark 部分的代码开发和维护成本,提升易用性。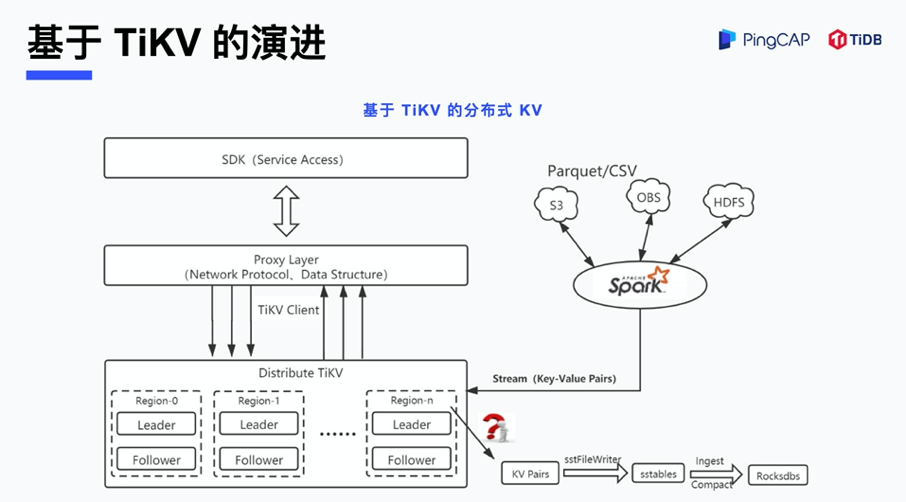
基于 TiKV的演进 – 测试结论
以下两张表是基于 TiKV 的 Bulk Load 能力进行实际测试的结果。上面这张表是在 E5 CPU,40 个 vcore,磁盘使用 NVMe 的情况下,最大可以达到 256 兆的单机吞吐。下边这张表是我们在进行 Bulk Load 的同时对 online reading 部分进行压测,可以看到 Latency 响应时间的抖动是非常小的,不管是 P99 还是 P99.99 ,都是处在一个比较稳定的状态。这个测试结果是一个 Demo 的验证,相信后续经过我们的优化,不管是存储吞吐还是响应延迟,都会有质的提升。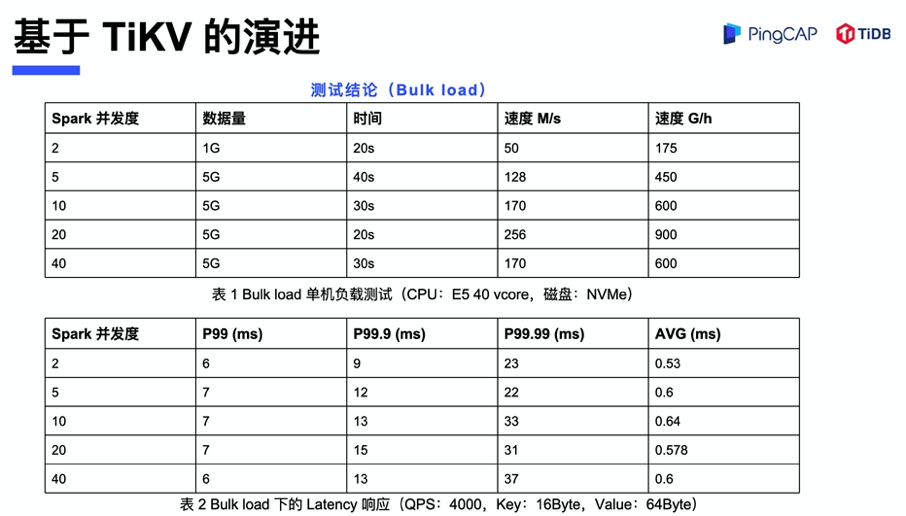
Bulk Load 的能力是我们和 TiKV 的研发同学一起,共同协作开发、共同演进的。我们相信开放的力量,后面我们会把整个架构,包括测试数据都会放到 GitHub 上公开,如果大家有相应的需求可以关注一下。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


