
原标题:Spring认证中国教育管理中心-Apache Geode 的 Spring 数据教程十一(Spring中国教育管理中心)
6.8.配置日志
通常,为了准确了解 Apache Geode 正在做什么以及何时执行,有必要打开日志记录。
要启用日志记录,请使用@EnableLogging并设置适当的属性或关联属性来注释您的应用程序类,如下所示:
ClientCache启用日志记录的Spring应用程序
@SpringBootApplication@ClientCacheApplication@EnableLogging(logLevel="info", logFile="/absolute/file/system/path/to/application.log)
public class ClientApplication { .. }虽然logLevel可以使用所有基于缓存的应用程序注释(例如,@ClientCacheApplication(logLevel="info"))指定该属性,但使用@EnableLogging注释自定义日志记录行为更容易。
此外,您可以log-level通过
spring.data.gemfire.logging.level在application.properties.
有关 更多详细信息,请参阅@EnableLogging注释 Javadoc。
6.9.配置统计
要在运行时更深入地了解 Apache Geode,您可以启用统计信息。收集统计数据有助于系统分析和故障排除,当复杂问题发生时,这些问题通常在自然界中分布且时间是一个关键因素。
启用统计后,您可以使用 Apache Geode 的 VSD(可视统计显示)工具来分析收集的统计数据。
要启用统计信息,请使用 注释您的应用程序类@EnableStatistics,如下所示:
ClientCache启用统计的Spring应用程序
@SpringBootApplication@ClientCacheApplication@EnableStatisticspublic class ClientApplication { .. }在评估性能时,在服务器上启用统计信息特别有价值。要做到这一点,你的注释@PeerCacheApplication或@CacheServerApplication类@EnableStatistics。
您可以使用@EnableStatistics注释属性或关联属性来自定义统计信息收集和收集过程。
有关 更多详细信息,请参阅@EnableStatistics注释 Javadoc。
可以在此处找到有关 Apache Geode 统计数据的更多详细信息 。
6.10.配置PDX
Apache Geode 更强大的功能之一是 PDX 序列化。虽然对 PDX 的完整讨论超出了本文档的范围,但使用 PDX 进行序列化是 Java 序列化的更好替代方法,具有以下优点:
PDX 使用集中式类型注册表来保持对象的序列化字节更紧凑。
PDX 是一种中性的序列化格式,允许 Java 和 Native 客户端对同一数据集进行操作。
PDX 支持版本控制并允许添加或删除对象字段,而不会影响使用已更改的旧版或新版 PDX 序列化对象的现有应用程序,而不会丢失数据。
PDX 允许在 OQL 查询投影和谓词中单独访问对象字段,而无需先对对象进行反序列化。
通常,在正常分发和复制过程中,以及在数据溢出或持久化到磁盘时,任何时候都需要在 Apache Geode 中进行序列化。
启用 PDX 序列化比修改要实现的所有应用程序域对象类型要简单得多 java.io.Serializable,尤其是在对应用程序域模型施加此类限制可能不合需要时,或者您对正在序列化的对象没有任何控制权时,尤其如此使用 3rd 方库时为 true(例如,考虑带有Coordinate类型的地理空间 API )。
要启用 PDX,请使用 注释您的应用程序类@EnablePdx,如下所示:
ClientCache启用 PDX 的Spring应用程序
@SpringBootApplication@ClientCacheApplication@EnablePdxpublic class ClientApplication { .. }通常,应用程序的域对象类型要么实现该
org.apache.geode.pdx.PdxSerializable 接口,要么您可以实现并注册该 接口的非侵入式实现, org.apache.geode.pdx.PdxSerializer 以处理所有需要序列化的应用程序域对象类型。
不幸的是,Apache Geode 只允许PdxSerializer注册一个,这表明所有应用程序域对象类型都需要由单个PdxSerializer实例处理。然而,这是一种严重的反模式和不可维护的做法。
尽管只能PdxSerializer向 Apache Geode 注册一个实例,但为PdxSerializer每个应用程序域对象类型创建一个实现是有意义的。
通过使用复合软件设计模式,您可以提供PdxSerializer接口的实现,该接口聚合所有应用程序域对象类型特定的 PdxSerializer实例,但充当单个PdxSerializer实例并注册它。
您可以PdxSerializer在 Spring 容器中将此组合声明为托管 bean,并使用属性PdxSerializer在@EnablePdx注释中通过其 bean 名称引用此组合 serializerBeanName。Spring Data for Apache Geode 负责代表您将其注册到 Apache Geode。
以下示例显示了如何创建自定义组合PdxSerializer:
ClientCache启用 PDX 的Spring应用程序,使用自定义组合PdxSerializer
@SpringBootApplication@ClientCacheApplication@EnablePdx(serializerBeanName = "compositePdxSerializer")
public class ClientApplication { @Bean
PdxSerializer compositePdxSerializer() { return new CompositePdxSerializerBuilder()...
}
}也可以
org.apache.geode.pdx.ReflectionBasedAutoSerializer 在 Spring 上下文中将Apache Geode 声明 为 bean 定义。
或者,您应该将 Spring Data 用于 Apache Geode 的更强大的
org.springframework.data.gemfire.mapping.MappingPdxSerializer,它使用 Spring Data 映射元数据和应用于序列化过程的基础设施,以便比单独的反射更有效地处理。
PDX 的许多其他方面和特性可以通过@EnablePdx注释属性或相关的配置属性进行调整。
有关 更多详细信息,请参阅@EnablePdx注释 Javadoc。
6.11.配置 Apache Geode 属性
虽然许多gemfire.properties 被方便地封装在基于 SDG 注释的配置模型中的注释中并抽象出来,但仍然可以从@EnableGemFireProperties注释中访问不太常用的 Apache Geode 属性。
在启动应用程序时,使用 注释应用程序类@EnableGemFireProperties很方便,并且是gemfire.properties在命令行上创建文件或将 Apache Geode 属性设置为 Java 系统属性的一种很好的替代方法。
我们建议gemfire.properties在将应用程序部署到生产环境时在文件中设置这些 Apache Geode 属性。但是,在开发时,为了原型设计、调试和测试目的,根据需要单独设置这些属性会很方便。
一些不常见的Apache的Geode性能的几个例子,你通常不必担心包括但不限于:ack-wait-threshold,disable-tcp,socket-buffer-size,和其他人。
要单独设置任何 Apache Geode 属性,请使用相应的属性注释您的应用程序类,@EnableGemFireProperties 并设置要更改的 Apache Geode 属性,从 Apache Geode 设置的默认值开始,如下所示:
ClientCache具有特定 Apache Geode 属性集的Spring应用程序
@SpringBootApplication@ClientCacheApplication@EnableGemFireProperties(conflateEvents = true, socketBufferSize = 16384)
public class ClientApplication { .. }请记住,一些在Apache的Geode属性是客户特定的(例如,conflateEvents),而另一些服务器特定的(例如distributedSystemId,
enableNetworkPartitionDetection, enforceUniqueHost,memberTimeout,redundancyZone,等)。
可以在此处找到有关 Apache Geode 属性的更多详细信息 。
6.12.配置区域
到目前为止,在 PDX 之外,我们的讨论集中在配置 Apache Geode 的更多管理功能:创建缓存实例、启动嵌入式服务、启用日志记录和统计、配置 PDX 以及 gemfire.properties用于影响低级配置和行为。尽管所有这些配置选项都很重要,但它们都与您的应用程序没有直接关系。换句话说,我们仍然需要一些地方来存储我们的应用程序数据并使其普遍可用和可访问。
Apache Geode 将缓存中的数据组织到Regions 中。您可以将区域视为关系数据库中的表。一般来说,一个Region应该只存储一种类型的对象,这样更有利于构建有效的索引和编写查询。我们稍后会介绍索引 。
以前,Spring Data for Apache Geode 用户需要通过编写非常详细的 Spring 配置元数据来明确定义和声明其应用程序使用的区域来存储数据,无论是使用FactoryBeans来自 API 的SDG和 Spring 的基于 Java 的容器配置 还是使用XML。
以下示例演示了如何在 Java 中配置 Region bean:
使用 Spring 的基于 Java 的容器配置的示例 Region bean 定义
@Configurationclass GemFireConfiguration { @Bean("Example")
PartitionedRegionFactoryBean exampleRegion(GemFireCache gemfireCache) {
PartitionedRegionFactoryBean<Long, Example> exampleRegion =
new PartitionedRegionFactoryBean<>();
exampleRegion.setCache(gemfireCache);
exampleRegion.setClose(false);
exampleRegion.setPersistent(true); return exampleRegion;
}
...
}以下示例演示了如何在 XML 中配置相同的 Region bean:
使用 SDG 的 XML 命名空间的区域 bean 定义示例
<gfe:partitioned-region id="exampleRegion" name="Example" persistent="true"> ...</gfe:partitioned-region>
虽然 Java 和 XML 配置都没有那么难指定,但任何一个都可能很麻烦,尤其是在应用程序需要大量区域的情况下。许多基于关系数据库的应用程序可能有数百甚至数千个表。
手动定义和声明所有这些区域会很麻烦且容易出错。好吧,现在有一个更好的方法。
现在您可以根据它们的应用程序域对象(实体)本身定义和配置区域。您不再需要Region在 Spring 配置元数据中显式定义bean 定义,除非您需要更细粒度的控制。
为了简化区域创建,Apache Geode 的 Spring Data 将 Spring Data Repositories 的使用与使用新@
EnableEntityDefinedRegions注解的基于注解的配置的表达能力相结合。
大多数 Spring Data 应用程序开发人员应该已经熟悉 Spring Data Repository 抽象 和 Spring Data for Apache Geode 的implementation/extension,它们已专门定制以优化 Apache Geode 的数据访问操作。
首先,应用程序开发人员首先定义应用程序的域对象(实体),如下所示:
应用领域对象类型建模一本书
@Region("Books")class Book { @Id
private ISBN isbn; private Author author; private Category category; private LocalDate releaseDate; private Publisher publisher; private String title;
}接下来,您Books通过扩展 Spring Data Commons
org.springframework.data.repository.CrudRepository接口为其定义一个基本存储库,如下所示:
书籍存储库
interface BookRepository extends CrudRepository<Book, ISBN> { .. }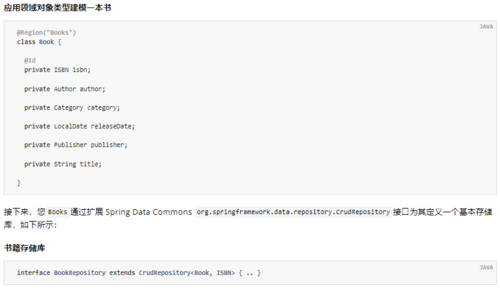
这
org.springframe.data.repository.CrudRepository是一个数据访问对象 (DAO),提供基本数据访问操作 (CRUD) 以及对简单查询(例如findById(..))的支持。您可以通过在存储库接口(例如,List<BooK> findByAuthor(Author author);)上声明查询方法来定义其他更复杂的查询。
在底层,当 Spring 容器被引导时,Spring Data for Apache Geode 提供了应用程序存储库接口的实现。只要您遵循约定, SDG 甚至可以实现您定义的查询方法。
现在,当您定义Book类时,您还Book通过@Region在实体类型上声明 Spring Data for Apache Geode 映射注释来指定映射(存储)实例的区域。当然,如果实体类型(Book在储存库接口的类型(参数引用,在这种情况下)BookRepository,在这种情况下)不与注释@Region,名称被从实体类型(简单类名派生也Book,在这个案例)。
Spring Data for Apache Geode 使用映射上下文(其中包含应用程序中定义的所有实体的映射元数据)来确定运行时所需的所有区域。
要启用和使用此功能,请使用 注释应用程序类@
EnableEntityDefinedRegions,如下所示:
实体定义区域配置
@SpringBootApplication@ClientCacheApplication@EnableEntityDefinedRegions(basePackages = "example.app.domain")@EnableGemfireRepositories(basePackages = "example.app.repo")
class ClientApplication { .. }在应用程序中使用 Spring Data Repositories 时,从实体类创建区域最有用。Spring Data for Apache Geode 的 Repository 支持通过@EnableGemfireRepositories注解启用,如前面的示例所示。
目前,@Region扫描仅选取显式注释的实体类,并将创建区域。如果实体类未显式映射,@Region则不会创建区域。
默认情况下,@
EnableEntityDefinedRegions注释以递归方式扫描实体类,从@EnableEntityDefinedRegions声明注释的配置类的包开始。
但是,通常通过basePackages使用包含应用程序实体类的包名称设置属性来限制扫描期间的搜索。
或者,您可以使用类型更安全的basePackageClasses属性来指定要扫描的包,方法是将属性设置为包含实体类的包中的实体类型,或者使用专门为识别包而创建的非实体占位符类扫描。
以下示例显示了如何指定要扫描的实体类型:
使用实体类类型的实体定义区域配置
@SpringBootApplication@ClientCacheApplication@EnableGemfireRepositories@EnableEntityDefinedRegions(basePackageClasses = {
example.app.books.domain.Book.class,
example.app.customers.domain.Customer.class
})
class ClientApplication { .. }除了像 Spring 的@ComponentScan注解一样指定从哪里开始扫描之外,您还可以使用注解的所有相同语义来指定include 和exclude过滤
org.springframework.context.annotation.ComponentScan.Filter 。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


