
课程名称:Scrapy打造搜索引擎(分布式爬虫)
课程章节:MySql表结构设计、pipeline数据库保存
主讲老师:bobby
课程内容:
今天学习的内容包括:
MySql表结构设计、pipeline数据库保存
课程收获:
1.数据库设计
1.创建数据库
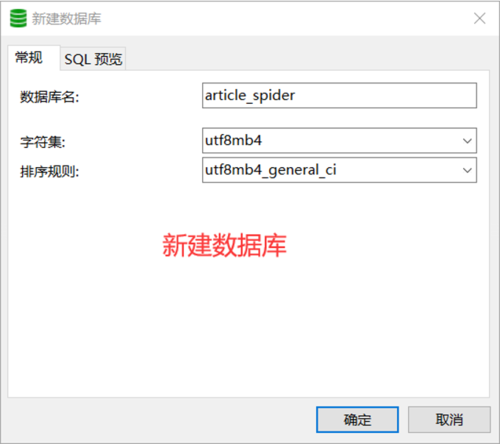
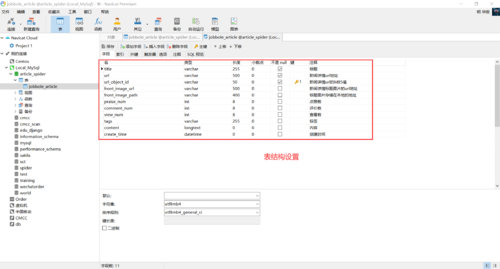
2.创建数据表——jobbole_article
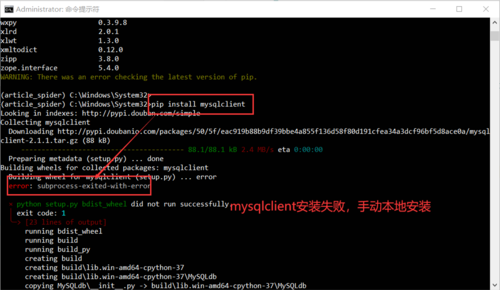
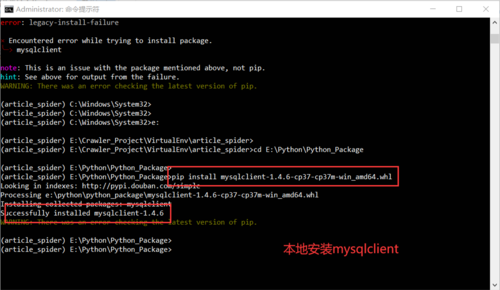
1.安装mysql数据库驱动mysqlclient
1.pip install mysqlclient安装
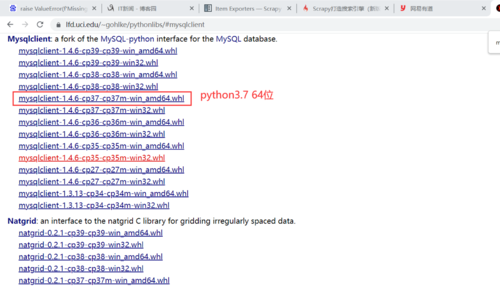
2.本地安装—— https://www.lfd.uci.edu/~gohlke/pythonlibs/
2.Pipeline插入数据至Mysql
1.核心代码
class MySqlPipeline:
def __init__(self):
# 数据库连接
self.conn = MySQLdb.connect("127.0.0.1", "root", "qq276713", "article_spider", charset="utf8", use_unicode=True)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
insert_sql = """
INSERT INTO jobbole_article(title, url, url_object_id, front_image_url, front_image_path, praise_num,
comment_num, view_num, tags, content, create_time)
VALUES(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE praise_num=VALUES(praise_num)
"""
params = list()
params.append(item.get("title", ""))
params.append(item.get("url", ""))
params.append(item.get("url_object_id", ""))
front_image = ",".join(item.get("front_image_url", []))
params.append(front_image)
params.append(item.get("front_image_path", ""))
params.append(item.get("praise_nums", 0))
params.append(item.get("comment_nums", 0))
params.append(item.get("view_nums", 0))
params.append(item.get("tags", ""))
params.append(item.get("content", ""))
params.append(item.get("create_date", "1970-07-01"))
self.cursor.execute(insert_sql, tuple(params)) # 将list列表转化为tuple元组
self.conn.commit() # 提交至数据库
return item
2.运行截图
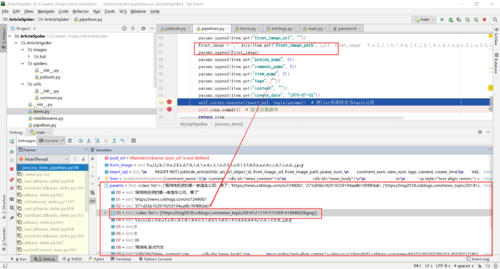
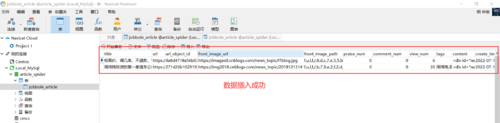
问题:
1.同步问题:MySQLdb也是一个同步库,因此在scrapy中尽量不要去写同步的代码,因此需要一个异步入库的方法解决同步的问题
原因:解析速度远远大于入库的速度,解析很多时候是CPU的操作,所以如果数据库很慢,数据库负耗很大,容易造成阻塞整个爬虫
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦