
激活函数
激活函数又称“非线性映射函数”,是深度卷积神经网络中不可或缺的模块。可以说,深度网络模型强大的表示能力大部分便是由激活函数的非线性单元带来的。这部分共介绍7个激活函数:Sigmoid函数,tanh函数,Relu函数,Leaky Relu函数,参数化Relu,随机化Relu和指数化线性单元(ELU)。
Sigmoid型函数
sigmoid函数也称Logistic函数:
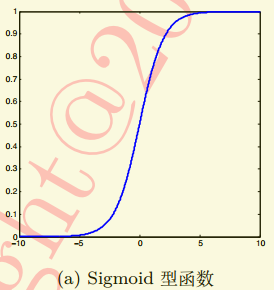
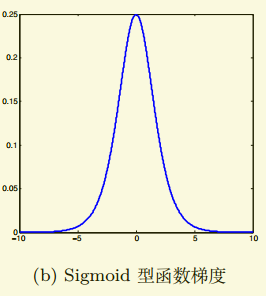
可以看出,经过sigmoid型函数作用后,输出响应的值被压缩到[0, 1]之间。0 对应生物神经元的“抑制状态”,1则恰好对应了“兴奋状态”。但对于sigmoid函数两端大于5(或小于-5)的区域,这部分输出会被压缩到1或0。这样的处理会带来梯度的饱和效应。不妨看一下simoid型函数梯度图,大于5或者小于-5部分梯度接近0。这会导致在误差反向传播过程中导数处于该区域的误差很难甚至无法传递至前层。进而导致整个网络无法训练。并且我们会发现,从图a中可以看出sigmoid型激活函数值域的均值并非为0, 而是全部为正,这样的结果实际上不符合我们对神经网络内数值的期望应为0的设想。
tanh(x)型函数
tanh(x)型函数是在sigmoid型函数基础上为解决均值问题提出的激活函数:
公式为:
tanh又称双曲正切函数,其函数范围是(-1, 1),输出相应的均值为0。但是tanh型函数仍为sigmoid型函数,使用tanh依然会发生梯度饱和现象。
Relu
Relu实际上是一个分段函数
Relu实际上是一个分段函数
if x>=0 relu(x) = x
else relu(x) = 0
总结一下就是Relu(x) = max(0, x)
对于Relu来说梯度在 x >= 0 为 1, 反之为 0。对 x >= 0 完全消除了sigmoid函数的饱和效应。计算复杂度上Relu也相对sigmoid和tanh更为简单。并且,实验中还发现Relu函数有助于随机梯度下降方法收敛,收敛速度快6倍左右。但是仍然有缺陷,在x<0时,梯度为0,换句话说对于小于0的这部分卷积结果响应,它们一旦变为负值将无法影响网络训练,这种现象叫死区。 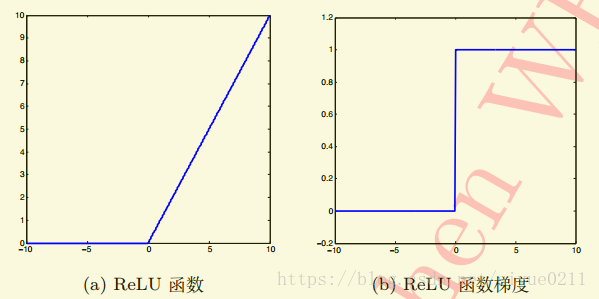
Leaky Relu
为了缓解死区,研究者将Relu函数中x<0那部分进行调整. 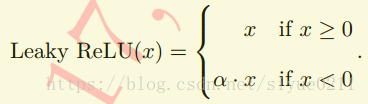
其中α为0.01 或者 0.001数量级的较小正数。可以发现relu实际上是leaky relu的一种特例。leaky relu存在的问题就是α是一个超参数,合适的值难设定并且较为敏感。因此实际leaky relu函数在实际使用上性能不是特别稳定。
参数化Relu
参数化Relu解决了leaky relu超参数α难设定的问题,参数化Relu直接将α也作为一个网络可以学习的变量融入模型的整体训练过程。在求解参数化Relu的过程中,文献仍然采用传统的误差反向传播和随机梯度下降,对于α的更此遵循链式法则。
实验证明,使用参数化relu作为激活函数的网络要优于原始relu的网络。同时自由度较大的各通道独享参数的参数化relu性能更优。
指数化线性单元(ELU)
优点:ELU具备Relu的优点,同时ELU也解决了Relu函数自身“死区”问题。不过ELU函数指数操作稍稍加大了工作量,实际计算中ELU中超参数λ一般设置为1。 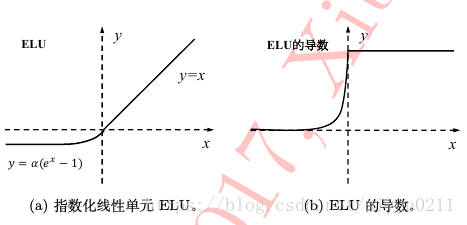
参考
解析卷积神经网络——深度学习实践手册
共同学习,写下你的评论
评论加载中...
作者其他优质文章



