

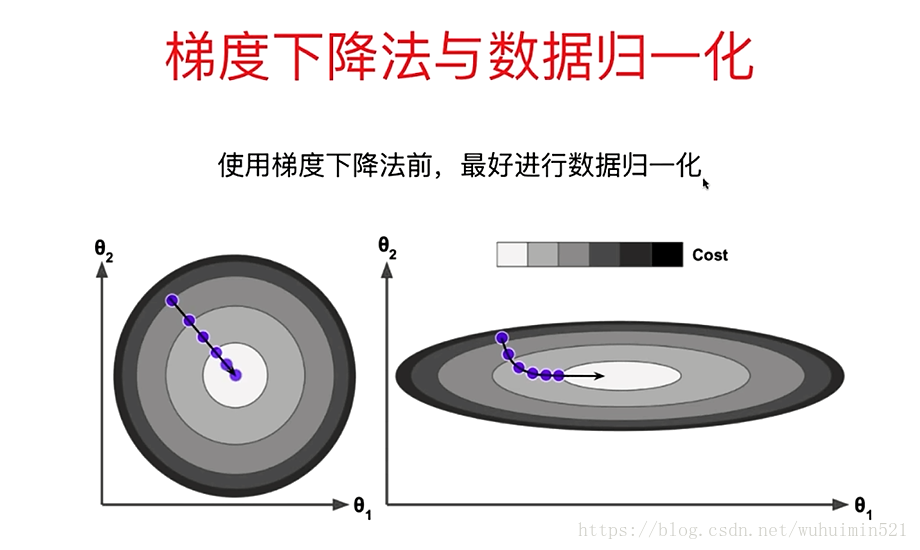

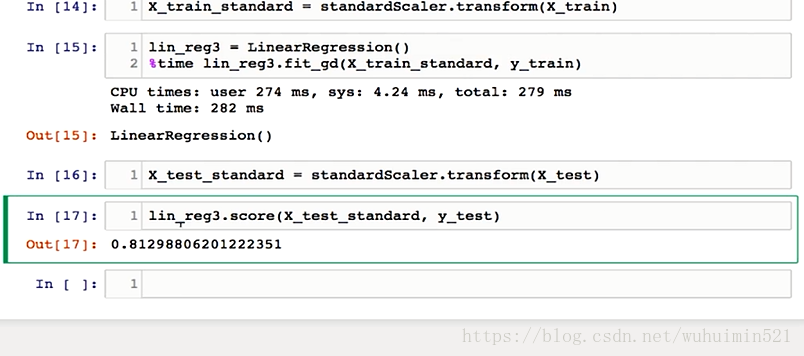


(1)批量梯度下降—最小化所有训练样本的损失函数(对全部训练数据求得误差后再对参数进行更新),使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小。批梯度下降类似于在山的某一点环顾四周,计算出下降最快的方向(多维),然后踏出一步,这属于一次迭代。批梯度下降一次迭代会更新所有theta,每次更新都是向着最陡的方向前进。
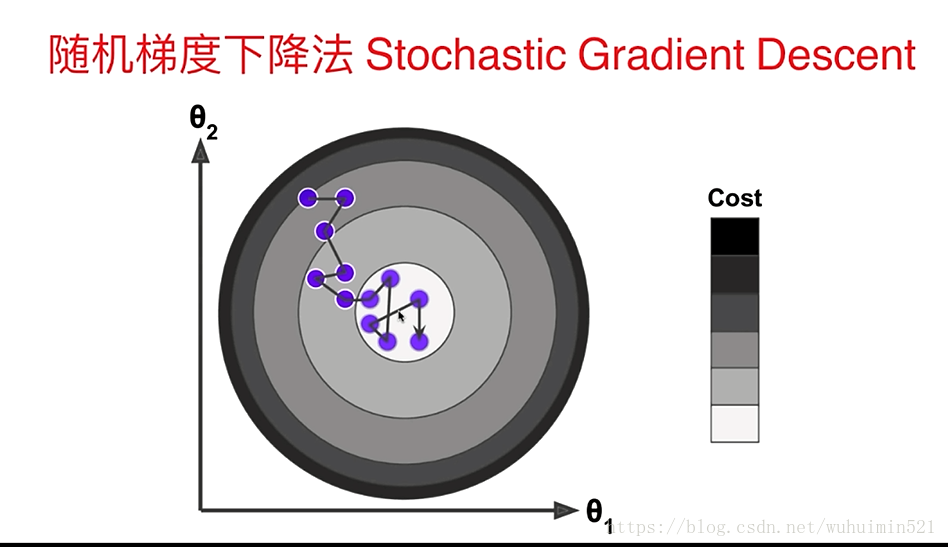
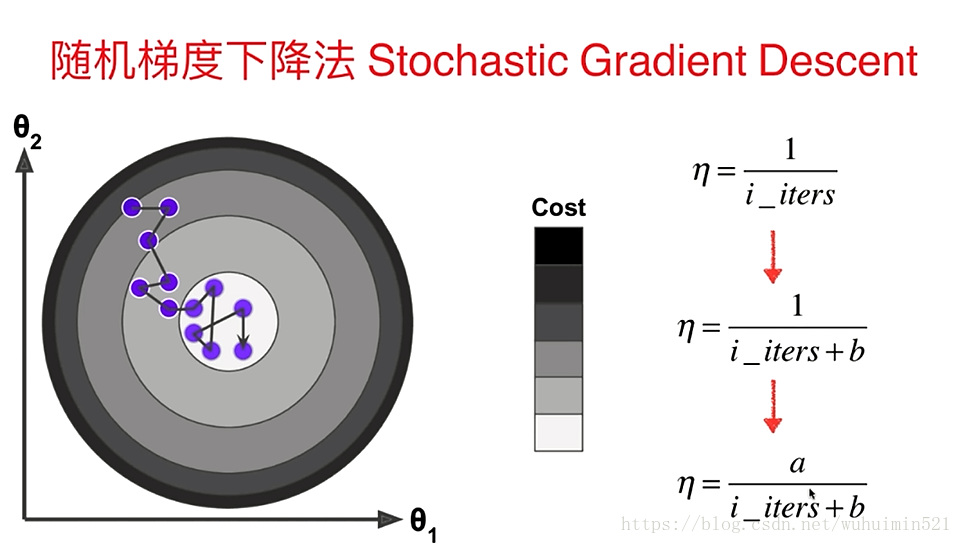
(2)随机梯度下降—最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。随机也就是说我用样本中的一个例子来近似我所有的样本,来调整theta,其不会计算斜率最大的方向,而是每次只选择一个维度踏出一步;下降一次迭代只更新某个theta,报着并不严谨的走走看的态度前进。
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦