
一般来说爬虫类框架抓取Ajax动态页面都是通过一些第三方的webkit库去手动执行html页面中的js代码, 最后将生产的html代码交给spider分析。本篇文章则是通过浏览器提供的Debug工具分析Ajax页面的具体请求内容,找到获取数据的接口url,直接调用该接口获取数据,省去了引入python-webkit库的麻烦,而且由于一般ajax请求的数据都是结构化数据,这样更省去了我们利用xpath解析html的痛苦。
这次我们要抓取的网站是淘女郎的页面,全站都是通过Ajax获取数据然后重新渲染生产的。
这篇文章的代码已上传至我的Github,由于后面有部分内容并没有提供完整代码,所以贴上地址供各位参考。
分析工作
用Chrome打开淘女郎的首页中的美人库,这个页面毫无疑问是会展示所有的模特的信息,同时打开Debug工具,在network选项中查看浏览器发送了哪些请求?
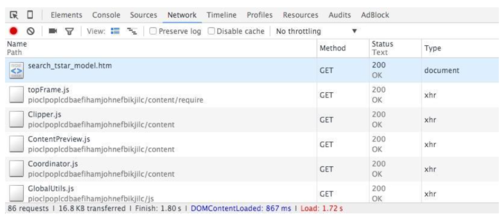
2016-07-04_16:11:01.jpg
在截图的左下角可以看到总共产生了86个请求,那么有什么办法可以快速定位到Ajax请求的链接了,利用Network当中提供的Filter功能,选中Filter,最后选择右边的XHR过滤(XHR时XMLHttpRequest对象,一般Ajax请求的数据都是结构化数据),这样就剩下了为数不多的几个请求,剩下的就靠我们自己一个一个的检查吧
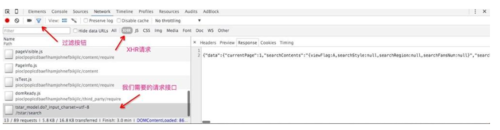
2016-07-04_16:22:18.jpg
很幸运,通过分析每个接口返回的request和response信息,发现最后一个请求就是我们需要的接口url
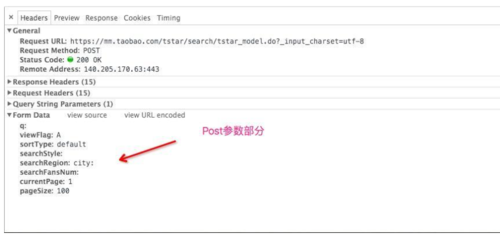
2016-07-04_16:25:56.jpg
Request中得参数很简单,根据英文意思就可以猜出意义,由于我们要抓取所有模特的信息,所以不需要定制这些参数,后面直接将这些参数post给接口就行了
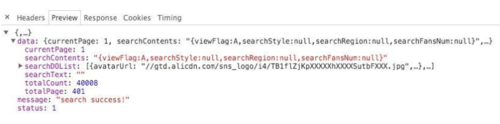
2016-07-04_16:29:06.jpg
在Response中可以获得到的有用数据有两个:所有模特信息的列表searchDOList、以及总页数totolPage
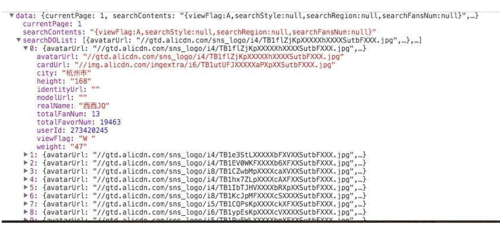
2016-07-04_16:35:05.jpg
searchDOList列表中得对象都有如上图所示的json格式,它也正是我们需要的模特信息的数据
Scrapy编码
定义Item
class tbModelItem(scrapy.Item): avatarUrl = scrapy.Field() cardUrl = scrapy.Field() city = scrapy.Field() height = scrapy.Field() identityUrl = scrapy.Field() modelUrl = scrapy.Field() realName = scrapy.Field() totalFanNum = scrapy.Field() totalFavorNum = scrapy.Field() userId = scrapy.Field() viewFlag = scrapy.Field() weight = scrapy.Field()
根据上面的分析得到的json格式,我们可以很轻松的定义出item
Spider编写
import urllib2 import os import re import codecs import json import sys from scrapy import Spider from scrapy.selector import Selector from MySpider.items import tbModelItem,tbThumbItem from scrapy.http import Request from scrapy.http import FormRequest from scrapy.utils.response import open_in_browser
reload(sys)
sys.setdefaultencoding('utf8')
class tbmmSpider(Spider):
name = "tbmm"
allow_domians = ["mm.taobao.com"]
custom_settings = { "DEFAULT_REQUEST_HEADERS":{ 'authority':'mm.taobao.com', 'accept':'application/json, text/javascript, */*; q=0.01', 'accept-encoding':'gzip, deflate', 'accept-language':'zh-CN,zh;q=0.8,en;q=0.6,zh-TW;q=0.4', 'origin':'https://mm.taobao.com', 'referer':'https://mm.taobao.com/search_tstar_model.htm?spm=719.1001036.1998606017.2.KDdsmP', 'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.97 Safari/537.36', 'x-requested-with':'XMLHttpRequest', 'cookie':'cna=/oN/DGwUYmYCATFN+mKOnP/h; tracknick=adimtxg; _cc_=Vq8l%2BKCLiw%3D%3D; tg=0; thw=cn; v=0; cookie2=1b2b42f305311a91800c25231d60f65b; t=1d8c593caba8306c5833e5c8c2815f29; _tb_token_=7e6377338dee7; CNZZDATA30064598=cnzz_eid%3D1220334357-1464871305-https%253A%252F%252Fmm.taobao.com%252F%26ntime%3D1464871305; CNZZDATA30063600=cnzz_eid%3D1139262023-1464874171-https%253A%252F%252Fmm.taobao.com%252F%26ntime%3D1464874171; JSESSIONID=8D5A3266F7A73C643C652F9F2DE1CED8; uc1=cookie14=UoWxNejwFlzlcw%3D%3D; l=Ahoatr-5ycJM6M9x2/4hzZdp6so-pZzm; mt=ci%3D-1_0'
}, "ITEM_PIPELINES":{ 'MySpider.pipelines.tbModelPipeline': 300
}
}
def start_requests(self):
url = "https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8"
requests = [] for i in range(1,60):
formdata = {"q":"", "viewFlag":"A", "sortType":"default", "searchStyle":"", "searchRegion":"city:", "searchFansNum":"", "currentPage":str(i), "pageSize":"100"}
request = FormRequest(url,callback=self.parse_model,formdata=formdata)
requests.append(request) return requests
def parse_model(self,response):
jsonBody = json.loads(response.body.decode('gbk').encode('utf-8'))
models = jsonBody['data']['searchDOList']
modelItems = [] for dict in models:
modelItem = tbModelItem()
modelItem['avatarUrl'] = dict['avatarUrl']
modelItem['cardUrl'] = dict['cardUrl']
modelItem['city'] = dict['city']
modelItem['height'] = dict['height']
modelItem['identityUrl'] = dict['identityUrl']
modelItem['modelUrl'] = dict['modelUrl']
modelItem['realName'] = dict['realName']
modelItem['totalFanNum'] = dict['totalFanNum']
modelItem['totalFavorNum'] = dict['totalFavorNum']
modelItem['userId'] = dict['userId']
modelItem['viewFlag'] = dict['viewFlag']
modelItem['weight'] = dict['weight']
modelItems.append(modelItem) return modelItems代码不长,一点一点来分析:
1. 由于分析这个页面并不需要递归遍历网页,所以就不要crawlSpider了,只继承最简单的spider
2. custome_setting可用于自定义每个spider的设置,而setting.py中的都是全局属性的,当你的scrapy工程里有多个spider的时候这个custom_setting就显得很有用了
3. ITEM_PIPELINES,自定义管道模块,当item获取到数据后会调用你指定的管道处理命令,这个后面会贴上代码,因为这个不影响本文的内容,数据的处理可以因人而异。
4. 依然重写start_request,带上必要的参数请求我们分析得到的借口url,这里我省了一个懒,只遍历了前60页的数据,各位当然可以先调用1次借口确定总的页数(totalPage)之后再写这个for循环。
5. parse函数里利用json库解析了返回来得数据,赋值给item的相应字段
3.数据后续处理
数据处理也就是我上面配置ITEM_PIPELINES的目的,这里,我将获取到的item数据存储到了本地的mysql数据中,各位也可以通过FEED_URL参数直接输出json格式文本文件
import MySQLdbclass tbModelPipeline(object):
def process_item(self,item,spider):
db = MySQLdb.connect("localhost","用户名","密码","spider")
cursor = db.cursor()
db.set_character_set('utf8')
cursor.execute('SET NAMES utf8;')
cursor.execute('SET CHARACTER SET utf8;')
cursor.execute('SET character_set_connection=utf8;')
sql ="INSERT INTO tb_model(user_id,avatar_url,card_url,city,height,identity_url,model_url,real_name,total_fan_num,total_favor_num,view_flag,weight)\
VALUES('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')"%(item['userId'],item['avatarUrl'],item['cardUrl'],item['city'],item['height'],item['identityUrl'],\
item['modelUrl'],item['realName'],item['totalFanNum'],item['totalFavorNum'],item['viewFlag'],item['weight']) try: print sql
cursor.execute(sql)
db.commit() except MySQLdb.Error,e: print "Mysql Error %d: %s" % (e.args[0], e.args[1])
db.close() return item更重要的内容
获取所有的淘女郎的基本信息并不是淘女郎这个网站的全部内容,还有一些更有意思的数据,比如:
点击进入模特的页面之后发现左侧会有有个相册选项卡,点击后右边出现了各种相册,而每个相册里面都是各种各样的模特照片
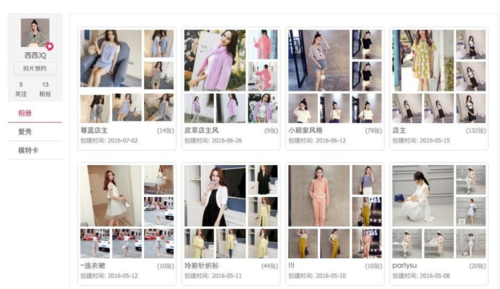
2016-07-04_17:04:22.jpg
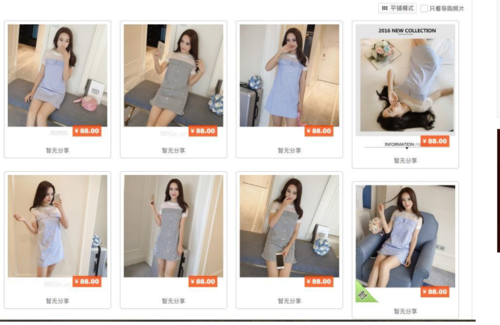
2016-07-04_17:04:49.jpg
通过network的分析,这些页面的数据通通都是Ajax请求获得的,具体的接口如下:
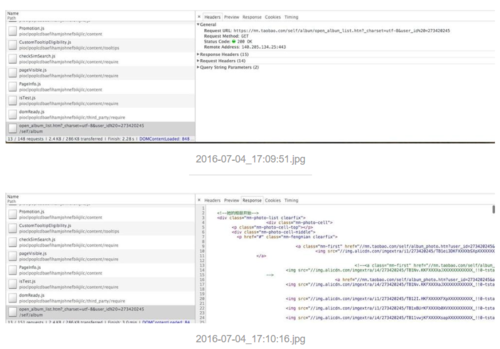
获取相册列表的接口是一个GET请求,其中只有一个很重要的user_id,而这个user_id在上面拿去模特的基本信息已经拿到了,还有个page参数用于标识获取的是第几页数据(由于这个是第一页,并没有在url中显现出来,可以通过返回的html中包含的totalPage元素获得)不过这个接口的返回就不是标准的json格式了,而是一段html,这时候又到了利用scrapy中提供的强大的xpath功能了
def parse_album(self,response):
sel = Selector(response)
tbThumbItems = []
thumb_url_list = sel.xpath("//div[@class='mm-photo-cell-middle']//h4//a/@href").extract()
thumb_name_list = sel.xpath("//div[@class='mm-photo-cell-middle']//h4//a/text()").extract()
user_id = response.meta['user_id'] for i in range(0,len(thumb_url_list)-1):
thumbItem = tbThumbItem()
thumbItem['thumb_name'] = thumb_name_list[i].replace('\r\n','').replace(' ','')
thumbItem['thumb_url'] = thumb_url_list[i]
thumbItem['thumb_userId'] = str(user_id)
temp = self.urldecode(thumbItem['thumb_url'])
thumbItem['thumb_id'] = temp['album_id'][0]
tbThumbItems.append(thumbItem) return tbThumbItems获取相册里照片的接口就是一个完全的json格式的接口了,其中参数包括我们已经拿到的user_id以及album_id,page的最大范围totalPage依然可以通过第一次返回的response中的totalPage字段获得
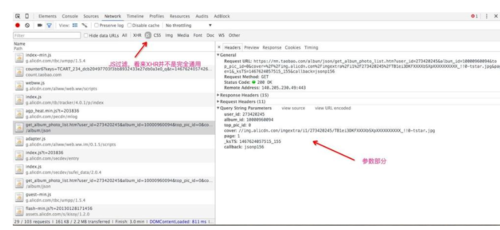
2016-07-04_17:25:23.jpg
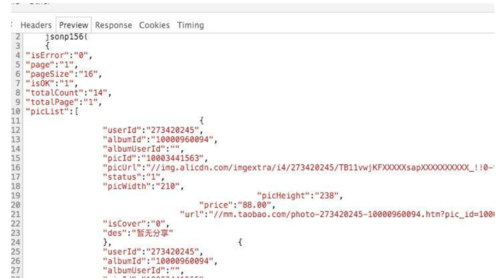
2016-07-04_17:25:46.jpg
总结
这种通过分析Ajax接口直接调用获取原始数据应该是效率最高的抓取数据方式,但并不是所有的Ajax页面都适用,还是要具体对待,比如我们上面获取相册列表当中就要去分析html来获得相册的基本信息。
获取相册和相册里的照片列表写的比较简略,基本没展示什么代码,这样写是有原因的:一个是因为我已经挂了代码的链接,而且后面这两部分的原理和我主要讲的第一部分获取模特信息的原理基本类似,不想花太多的篇幅花在这种重复的内容上,另外一个我希望想掌握Scrapy的同学能在明白我第一部分的讲解下自己能顺利完成后面的工作,遇到不明白的时候可以看看我Github上的源码,看看有什么不对的地方,只有自己写一遍才能掌握,这是编程界的硬道理。
作者:mylonly
链接:https://www.jianshu.com/p/1e35bcb1cf21
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


