
开篇:为什么JVM调优是面试必考题
如果你是一名Java开发者,不管是工作3年还是5年,只要去面试中高级岗位,JVM调优几乎是绕不开的一道坎。面试官总会变着花样问你:
“说一下你做过的JVM调优经验?”
“生产环境OOM了怎么排查?”
“G1和CMS有什么区别?怎么选择?”
“年轻代和老年代比例怎么设置才合理?”
很多同学背了一堆理论,什么堆内存分代、垃圾回收算法、各种JVM参数张口就来,但一被问到"你实际调过吗?调完效果怎么样?"就瞬间卡壳。
这篇文章,我不讲空泛的理论,而是用一个真实的电商大促系统调优案例,带你从头到尾走一遍完整的JVM调优流程。从问题发现、根因定位、参数调优、效果验证,每一步都给你讲得明明白白。
看完这篇文章,你不仅能应付面试,更能在实际工作中真正解决问题。
一、实战案例背景:电商大促前的性能危机
1.1 项目背景
我们的项目是一个中型电商平台,核心交易系统采用微服务架构,主要技术栈:
-
JDK 1.8.0_202
-
Spring Boot 2.3.x + Spring Cloud
-
MySQL 8.0 + Redis 6.x
-
Tomcat 9.0 作为Web容器
-
部署环境:8核16G物理机,每台机器部署2个应用实例
系统主要承担商品浏览、购物车、下单、支付等核心交易链路。平时日均订单量10万左右,系统运行还算平稳。
1.2 问题爆发
距离"618"大促还有两周,压测团队对核心下单接口进行了一轮压力测试,结果让人惊出一身冷汗:
| 指标 | 压测前预期 | 实际压测结果 |
|---|---|---|
| QPS | 目标 2000 | 最高 800 就开始掉 |
| 响应时间(P99) | < 200ms | 飙升到 2000ms+ |
| 错误率 | < 0.1% | 超过 5% |
| Full GC频率 | < 1次/小时 | 每10分钟一次 |
| 老年代使用率 | < 70% | 频繁涨到95%+ |
压测进行到第15分钟,系统直接抛出了 java.lang.OutOfMemoryError: GC overhead limit exceeded,整个服务假死。
更要命的是,这还只是模拟大促流量的60%。如果真到了大促当天,系统肯定直接崩。
1.3 初步排查
运维同学第一时间拉了堆内存快照(heap dump),但文件太大(10G+),用MAT打开直接卡死。大家七嘴八舌讨论了半天,有人说加机器,有人说加内存,有人说换G1垃圾回收器,但谁也说不准问题到底出在哪。
于是,调优的任务落到了我头上。
二、调优前的准备:磨刀不误砍柴工
很多人一上来就改JVM参数,这是典型的"瞎调"。JVM调优的第一原则是:先定位问题,再动手调优。
在开始调优之前,我们先回顾一下JVM的内存模型,做到心中有数: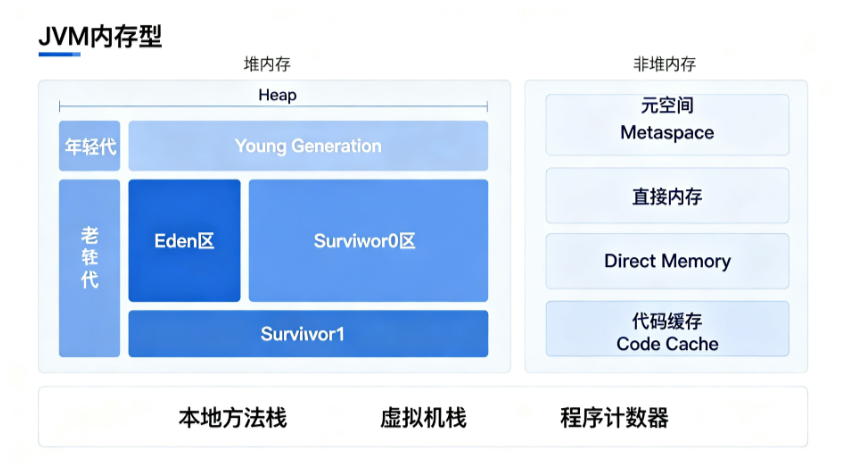
如图所示,JVM内存主要分为两大块:
-
堆内存(Heap):所有线程共享,存放对象实例,是GC的主要区域
-
非堆内存:包括元空间、直接内存、代码缓存等
-
线程私有区域:虚拟机栈、本地方法栈、程序计数器
理解了内存结构,我们才能知道调优是在调什么。
2.1 明确调优目标
调优不是为了调而调,必须有明确的目标。我们和业务方、产品经理一起对齐了大促的目标:
-
吞吐量目标:核心下单接口QPS达到3000+
-
延迟目标:P99响应时间 < 300ms
-
稳定性目标:Full GC频率 < 1次/小时,无OOM
-
资源约束:单机8核16G,最多再加2台机器
2.2 建立基线数据
调优前必须有基线数据,否则你不知道调完是变好还是变坏。我们做了以下准备:
1. 开启JVM监控
在每个应用节点上配置了JMX监控,使用Prometheus + Grafana采集JVM指标:
# JVM启动参数中添加
-Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.port=9090
-Dcom.sun.management.jmxremote.authenticate=false
-Dcom.sun.management.jmxremote.ssl=false
-Djava.rmi.server.hostname=192.168.1.100
2. 配置GC日志
这是非常重要的一步,很多人居然不开GC日志就调优,简直是盲人摸象。
# JDK 8 GC日志配置
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:+PrintHeapAtGC
-XX:+PrintTenuringDistribution
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintPromotionFailure
-Xloggc:/var/log/gc-%t.log
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=10
-XX:GCLogFileSize=100M
为什么要打印这么多信息?
PrintGCDetails:打印GC详细信息
PrintGCDateStamps:打印GC发生的绝对时间
PrintTenuringDistribution:打印对象年龄分布,这个对判断年轻代大小至关重要
PrintGCApplicationStoppedTime:打印STW时间,这才是用户真正感知到的停顿
PrintPromotionFailure:打印晋升失败信息,排查老年代空间不足问题
3. 准备压测脚本
使用JMeter编写了下单接口的压测脚本,模拟真实用户行为:
-
1000线程并发
-
Ramp-up时间60秒
-
持续压测30分钟
-
混合场景:浏览商品→加购物车→下单→支付
2.3 初始JVM参数
先看看系统原来的JVM参数是什么水平:
# 原始配置(典型的"默认党"配置)
-Xms4g -Xmx4g
-XX:PermSize=256m
-XX:MaxPermSize=512m
-XX:+UseParallelGC
问题一眼就能看出来:
-
堆内存4G,对于8G可用内存(16G机器跑2个实例)来说偏小
-
永久代(PermGen)用的是JDK 7的参数,JDK 8已经是元空间了
-
使用Parallel GC,这是吞吐量优先的回收器,但停顿时间不可控
-
年轻代大小没有设置,用默认值(堆的1/3)
-
没有设置Survivor区比例
三、问题定位:从现象到根因的完整链路
3.1 第一步:看GC日志
拿到压测期间的GC日志,我先用 GCViewer 工具做了可视化分析,然后又手动分析了关键片段。
先看Young GC:
2026-06-01T10:00:05.234+0800: 120.567: [GC (Allocation Failure)
[PSYoungGen: 1048576K->87380K(1222656K)]
2097152K->1135956K(3932160K),
0.0876540 secs]
[Times: user=0.45 sys=0.02, real=0.09 secs]
解读:
-
年轻代大小约1.2G(1222656K)
-
每次Young GC回收约960M对象(1048576K - 87380K)
-
存活对象约87M,晋升到老年代
-
单次Young GC耗时87ms,还可以接受
-
但是!Young GC频率太高了,大约每3秒一次
再看Full GC:
2026-06-01T10:15:32.123+0800: 1047.456: [Full GC (Ergonomics)
[PSYoungGen: 87380K->0K(1222656K)]
[ParOldGen: 2621440K->2583456K(2621440K)]
2708820K->2583456K(3844096K),
[Metaspace: 128765K->128543K(1167360K)],
5.2345670 secs]
[Times: user=18.56 sys=0.23, real=5.23 secs]
问题大了:
-
Full GC耗时5.23秒!这意味着系统会卡住5秒多
-
老年代2.5G,Full GC后只回收了不到40M(2621440K - 2583456K)
-
说明老年代里大部分都是存活对象,Full GC根本回收不了多少
-
这是典型的内存泄漏或者对象生命周期过长的特征
3.2 第二步:分析堆内存
既然Full GC回收效果差,那老年代里到底装了些什么?
我用 jmap 命令在压测高峰期dump了堆内存:
jmap -dump:format=b,file=/tmp/heap.hprof <pid>
小贴士:dump堆内存会触发Full GC,而且文件很大,生产环境慎用。最好在压测环境或者低峰期操作。
然后用 jhat 或者 MAT(Memory Analyzer Tool)分析。由于文件太大,我先用 jmap -histo 看了下对象统计:
jmap -histo:live <pid> | head -30
输出结果(简化版):
num #instances #bytes class name
----------------------------------------------
1: 5678901 454312080 [C
2: 2345678 225188928 java.lang.String
3: 876543 198765432 [B
4: 543210 123456789 com.alibaba.fastjson.JSONObject
5: 234567 98765432 com.xxx.order.entity.OrderDO
6: 123456 87654321 org.apache.tomcat.util.threads.TaskThread
7: 98765 76543210 java.util.HashMap$Node
8: 87654 65432109 com.xxx.product.vo.ProductVO
...
发现疑点:
-
JSONObject有54万个,占了120M内存 -
OrderDO有23万个,占了近100M -
ProductVO也有8万多个
正常来说,这些对象应该在请求结束后就被回收了,不应该有这么多存活实例。
3.3 第三步:定位内存泄漏点
我用MAT打开了堆快照,查看了支配树(Dominator Tree),很快发现了问题:
问题一:FastJSON的缓存泄漏
Class Name | Objects | Shallow Heap | Retained Heap
--------------------------------------------------------------------------------
com.alibaba.fastjson.util.TypeUtils | 1 | 32 | 128,456,789
|- parserConfig | 1 | 48 | 120,345,678
|- deserializers | 543210 | 12,345,678 | 115,678,901
TypeUtils 里的 parserConfig 持有了大量反序列化器,每个类对应一个反序列化器,而且是强引用,不会被回收。
我们的系统大量使用FastJSON做序列化/反序列化,而且很多VO类是动态生成的,导致反序列化器越积越多。
问题二:ThreadLocal内存泄漏
Class Name | Objects | Retained Heap
--------------------------------------------------------------------------
java.lang.ThreadLocal$ThreadLocalMap | 200 | 98,765,432
|- table | 12345 | 95,432,109
|- java.lang.ThreadLocal$ThreadLocalMap$Entry | 8765 | 89,876,543
|- value (UserContext) | 8765 | 85,432,109
Tomcat线程池有200个线程,每个线程的ThreadLocal里都存了 UserContext 对象,而且这些对象里还包含了用户信息、权限信息、甚至完整的订单列表。
更严重的是,很多请求结束后没有调用 remove() 方法清理ThreadLocal,导致这些对象一直存活,跟着线程走到老年代。
问题三:大对象直接进入老年代
查看对象年龄分布(PrintTenuringDistribution的输出):
Desired survivor size 67108864 bytes, new threshold 15 (max 15)
- age 1: 56789016 bytes, 56789016 total
- age 2: 12345678 bytes, 69134694 total
- age 3: 8765432 bytes, 77900126 total
...
- age 15: 2345678 bytes, 123456789 total
Survivor区只有64M,但是age 1的对象就有56M,加上其他年龄的,Survivor区很快就满了,导致很多对象还没到年龄阈值就被晋升到老年代。
3.4 第四步:确认问题根因
经过一番分析,问题根因基本清楚了:
| 问题 | 影响程度 | 优先级 |
|---|---|---|
| ThreadLocal内存泄漏 | 高(约200M泄漏) | P0 |
| FastJSON反序列化器缓存膨胀 | 中高(约120M) | P1 |
| 年轻代太小,对象过早晋升 | 中 | P1 |
| 老年代空间不足 | 中(结果而非原因) | P2 |
| Parallel GC停顿时间长 | 中 | P2 |
核心结论:这不是简单的参数调优问题,而是有代码层面的内存泄漏。
很多人一遇到OOM就怪JVM参数设置不合理,其实80%的情况都是代码写得有问题。JVM调优的第一步,永远是先排查代码问题。
四、调优实战第一阶段:修复代码层面的问题
4.1 修复ThreadLocal内存泄漏
问题代码:
public class UserContextHolder {
private static final ThreadLocal<UserContext> USER_CONTEXT = new ThreadLocal<>();
public static void set(UserContext context) {
USER_CONTEXT.set(context);
}
public static UserContext get() {
return USER_CONTEXT.get();
}
// 缺少remove方法!
}
修复方案:
public class UserContextHolder {
private static final ThreadLocal<UserContext> USER_CONTEXT = new ThreadLocal<>();
public static void set(UserContext context) {
USER_CONTEXT.set(context);
}
public static UserContext get() {
return USER_CONTEXT.get();
}
// 新增remove方法
public static void remove() {
USER_CONTEXT.remove();
}
// 优化:UserContext不要存大对象,只存必要的用户ID
public static class UserContext {
private Long userId;
private String userName;
// 移除了原来的orderList、permissionList等大对象
// 需要时再去查,不要存在ThreadLocal里
}
}
然后加一个拦截器,请求结束后自动清理:
@Component
public class UserContextInterceptor implements HandlerInterceptor {
@Override
public void afterCompletion(HttpServletRequest request,
HttpServletResponse response,
Object handler,
Exception ex) {
// 请求结束后清理ThreadLocal,防止内存泄漏
UserContextHolder.remove();
}
}
效果: 修复后,老年代中ThreadLocal相关的对象从200M降到了不到10M。
4.2 优化FastJSON缓存
FastJSON的 ParserConfig 默认是全局单例,会缓存所有反序列化过的类的反序列化器。对于动态生成的类或者大量不同的VO类,这个缓存会无限膨胀。
优化方案:
// 方案一:使用带软引用的ParserConfig(推荐)
ParserConfig config = new ParserConfig();
// 开启软引用模式,内存不足时自动回收
config.setAsmEnable(false); // 关闭ASM,减少字节码生成
// 方案二:自定义缓存大小
ParserConfig config = new ParserConfig() {
@Override
public ObjectDeserializer getDeserializer(Class<?> clazz) {
// 只缓存常用的类,不缓存动态生成的类
if (clazz.getName().startsWith("com.xxx.dynamic.")) {
return super.createJavaBeanDeserializer(this, clazz);
}
return super.getDeserializer(clazz);
}
};
另外,我们还把一些不必要的VO类合并了,减少了类的数量。
效果: FastJSON相关的内存占用从120M降到了30M左右。
4.3 优化大对象创建
排查中还发现,有些地方在频繁创建大对象,比如:
// 反面示例:每次查询都new一个大的List
public List<ProductVO> batchQuery(List<Long> ids) {
List<ProductVO> result = new ArrayList<>(10000); // 初始容量太大
// ...
}
// 反面示例:字符串拼接用+号
public String generateOrderDesc(OrderDO order) {
String desc = "";
for (OrderItemDO item : order.getItems()) {
desc += item.getProductName() + ","; // 每次都创建新字符串
}
return desc;
}
优化后:
// 合理设置初始容量
public List<ProductVO> batchQuery(List<Long> ids) {
List<ProductVO> result = new ArrayList<>(ids.size());
// ...
}
// 使用StringBuilder
public String generateOrderDesc(OrderDO order) {
StringBuilder sb = new StringBuilder();
for (OrderItemDO item : order.getItems()) {
sb.append(item.getProductName()).append(",");
}
return sb.toString();
}
小贴士:很多人觉得这种优化是"过早优化",但在高并发场景下,这些小问题累积起来就是大问题。一个请求多创建100K对象,1000QPS就是100M/s的垃圾,年轻代很快就满了。
五、调优实战第二阶段:JVM内存参数调优
代码问题修复后,我们再来看JVM参数调优。这时候调优才是有意义的。
5.1 堆内存大小设置
原则:堆内存不是越大越好,要根据实际情况来。
我们的机器是16G内存,跑2个应用实例。每个实例分配多少堆内存合适呢?
计算一下:
-
操作系统预留:约2G
-
每个实例堆外内存(元空间、直接内存、线程栈等):约1G
-
两个实例就是2G
-
剩下12G分给两个实例的堆,每个6G
但是,堆太大也有问题:
-
堆越大,单次Full GC的时间越长
-
6G的堆,Parallel GC做一次Full GC可能要10秒以上
综合考虑,我们给每个实例设置5G堆内存:
-Xms5g -Xmx5g
为什么Xms和Xmx要设成一样?
避免运行时动态调整堆大小带来的性能损耗
避免每次扩容/缩容都要做Full GC
生产环境强烈建议设置成一样的
5.2 年轻代大小设置
这是JVM调优中最关键的参数之一,也是最容易调错的。
年轻代设置的原则:
-
年轻代太小 → Young GC频繁,对象过早晋升老年代
-
年轻代太大 → Young GC单次耗时变长,老年代空间不足
怎么确定年轻代大小?
看GC日志里的对象年龄分布。我们修复代码后的GC日志显示:
-
每次Young GC后存活对象约50M
-
Survivor区能容纳这些存活对象
-
大部分对象在年龄3之前就被回收了
根据经验公式:
年轻代大小 = (并发请求数 × 单次请求对象大小)× 2~3倍
我们的情况:
-
峰值QPS 3000
-
单次请求产生约100K对象
-
每秒产生约300M对象
-
Young GC间隔希望在10秒左右
-
那么年轻代需要 300M × 10 = 3G?不对,这是错的算法
正确的算法:
看GC日志,原来年轻代1.2G时,Young GC频率是每3秒一次。
如果想要每10秒一次,年轻代需要 1.2G × (10/3) ≈ 4G?也不对。
实际上,年轻代大小要看对象生命周期。 我们的业务对象大部分都是"朝生夕死"的,请求结束就可以回收。
经过多次测试,我们最终设置:
-Xmn2g # 年轻代2G
或者用NewRatio参数:
-XX:NewRatio=2 # 老年代:年轻代 = 2:1,即年轻代占堆的1/3
JDK 8默认的NewRatio是2,也就是年轻代占堆的1/3。 这个默认值对于大多数应用来说是比较合理的。
5.3 Survivor区比例设置
Survivor区的作用是存放Young GC后存活的对象,让它们在年轻代多待几次,等真正"老了"再晋升到老年代。
Survivor区设置的原则:
-
Survivor区要能容纳下Young GC后的存活对象 × 年龄阈值
-
不能太小,否则对象过早晋升
-
不能太大,否则浪费年轻代空间
-XX:SurvivorRatio=8 是默认值,表示 Eden:Survivor0:Survivor1 = 8:1:1。
也就是说,2G的年轻代:
-
Eden区:1.6G
-
每个Survivor区:200M
我们的情况:
-
每次Young GC后存活对象约50M
-
年龄阈值默认15
-
50M × 15 = 750M,这比200M大很多
问题来了:Survivor区只有200M,但是存活对象的总大小可能超过200M,这时候会触发什么?
答案是:动态年龄计算机制。
JVM会根据Survivor区的占用情况动态调整晋升年龄。如果某个年龄的对象总和超过了Survivor区的一半,那么大于等于这个年龄的对象都会晋升到老年代。
所以我们需要调大Survivor区吗?
不一定。我们的对象大部分在年龄3之前就死了,真正能活到15岁的对象很少。
我们做了个测试,把SurvivorRatio调成4(也就是每个Survivor区占年轻代的1/6):
-XX:SurvivorRatio=4
2G年轻代的话:
-
Eden区:2G × 4/6 ≈ 1.33G
-
每个Survivor区:2G × 1/6 ≈ 333M
测试结果:
-
Young GC频率从每3秒一次变成每2.5秒一次(因为Eden变小了)
-
晋升到老年代的对象减少了约30%
-
Full GC频率从每10分钟一次降到了每30分钟一次
这个 trade-off 是值得的。 虽然Young GC更频繁了,但每次耗时更短(Eden小了),而且减少了对象晋升,Full GC少了很多。
5.4 对象晋升年龄阈值
-XX:MaxTenuringThreshold 参数设置对象晋升到老年代的最大年龄阈值,默认是15(CMS默认是6)。
这个值不是越大越好:
-
太大 → 对象在年轻代待太久,占用Survivor空间
-
太小 → 对象过早晋升,老年代增长快
我们的情况:大部分对象3岁以内就死了,所以把阈值设大一点也没关系。
-XX:MaxTenuringThreshold=15
注意:这个参数只是"最大"阈值,实际的晋升年龄是JVM动态计算的,不一定能达到这个最大值。
5.5 元空间设置
JDK 8把永久代换成了元空间(Metaspace),元空间使用的是本地内存,不是堆内存。
默认情况下,元空间的大小是不受限制的(只受限于本地内存),但这可能导致元空间无限膨胀。
所以还是建议设置一下上限:
-XX:MetaspaceSize=256m
-XX:MaxMetaspaceSize=512m
MetaspaceSize和MaxMetaspaceSize的区别:
MetaspaceSize:元空间初始大小,达到这个值就会触发Full GC卸载类
MaxMetaspaceSize:元空间最大大小,默认是无限制这两个值和永久代的PermSize、MaxPermSize类似,但语义不完全一样
我们的应用大概用了150M左右的元空间,设置512M足够了。
5.6 直接内存设置
如果你的应用用到了NIO、Netty,或者使用了 ByteBuffer.allocateDirect(),那直接内存也需要关注。
直接内存不受堆大小限制,但会占用本地内存。默认情况下,直接内存的最大值等于 -Xmx 的值。
我们的应用用了Netty,所以显式设置一下:
-XX:MaxDirectMemorySize=512m
防止直接内存占用太多导致物理内存不足。
六、调优实战第三阶段:垃圾回收器调优
内存参数调好之后,接下来就是垃圾回收器的选择和调优了。
6.1 垃圾回收器选型
JDK 8提供了以下几种垃圾回收器:
| 回收器 | 年轻代算法 | 老年代算法 | 特点 | 适用场景 |
|---|---|---|---|---|
| Serial | 复制算法 | 标记-整理 | 单线程,STW时间长 | 客户端应用、内存小 |
| Parallel | 复制算法(多线程) | 标记-整理(多线程) | 吞吐量优先 | 后台计算、批处理 |
| CMS | 复制算法 | 标记-清除(并发) | 低延迟 | Web应用、交互型 |
| G1 | 分区复制算法 | 分区标记-整理 | 兼顾吞吐量和延迟 | 大堆、低延迟要求 |
我们的场景:
-
是Web应用,对响应时间敏感
-
堆内存5G,属于中等大小
-
目标是P99 < 300ms
Parallel GC的问题:
-
Full GC是单线程的?不,Parallel Old是多线程的
-
但是Full GC的STW时间还是太长,5G堆可能要5秒以上
-
这对于Web应用来说是不可接受的
CMS的问题:
-
标记-清除算法,会产生内存碎片
-
并发模式失败(Concurrent Mode Failure)时会退化成Serial Old,STW时间更长
-
需要更多的CPU资源
-
调优参数多,比较复杂
G1的优势:
-
可以设置目标停顿时间(-XX:MaxGCPauseMillis)
-
整体上是标记-整理,不会产生内存碎片
-
大堆情况下表现更好
-
JDK 9以后默认就是G1,是趋势
我们的选择:G1垃圾回收器。
G1和传统的分代回收器最大的区别是内存布局,它把堆分成了多个大小相等的Region: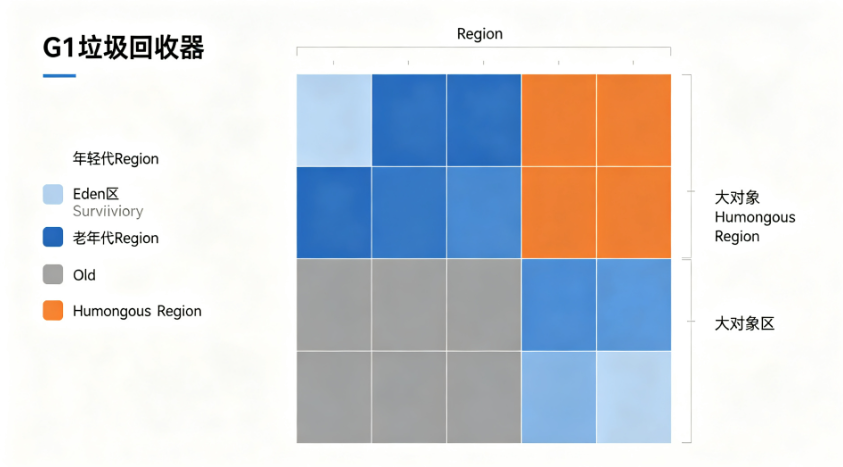
如图所示,G1的内存特点:
-
物理分区,逻辑分代:每个Region可以是Eden、Survivor、Old,也可以是Humongous(大对象区)
-
可预测的停顿:G1可以根据设置的目标停顿时间,选择回收价值最高的Region
-
无内存碎片:整体采用标记-整理算法,局部采用复制算法
为什么不选ZGC或者Shenandoah? 因为我们用的是JDK 8,这两个回收器在JDK 11/12才正式引入。如果是JDK 11+,强烈推荐ZGC。
6.2 G1基础配置
# 启用G1
-XX:+UseG1GC
# 设置目标停顿时间,这是G1最重要的参数
-XX:MaxGCPauseMillis=200
# 年轻代大小范围(可选,G1会自动调整)
-XX:G1NewSizePercent=5
-XX:G1MaxNewSizePercent=60
关于MaxGCPauseMillis:
-
默认值是200ms
-
这个值不是越小越好,设置得太小,G1会为了达到目标而减少每次回收的区域,导致GC频率变高,吞吐量下降
-
设置得太大,停顿时间超过业务容忍度
-
建议从默认值开始,根据实际GC日志调整
我们的目标是P99 < 300ms,所以设置200ms的目标停顿时间比较合理,留一些余量。
6.3 G1重要参数调优
1. 分区大小(-XX:G1HeapRegionSize)
G1把堆分成很多大小相等的区域(Region),默认根据堆大小自动计算:
| 堆大小 | 默认Region大小 |
|---|---|
| < 4G | 1M |
| 4G ~ 8G | 2M |
| 8G ~ 16G | 4M |
| 16G ~ 32G | 8M |
| 32G ~ 64G | 16M |
我们的堆是5G,默认Region大小是2M。
大对象阈值: 超过Region大小一半的对象被认为是大对象(Humongous Object),会直接分配到老年代的Humongous区域。
大对象对G1不友好,因为:
-
大对象不能被年轻代GC回收
-
大对象回收效率低
-
大对象可能导致空间碎片化
我们的应用里有一些大的字节数组和字符串,可能会超过1M(Region的一半),被当成大对象。
所以我们把Region调大一点:
-XX:G1HeapRegionSize=4m
这样大对象阈值变成2M,很多对象就不算大对象了。
注意:G1HeapRegionSize必须是2的幂,可选值是1m、2m、4m、8m、16m、32m。
2. 并发标记触发时机(-XX:InitiatingHeapOccupancyPercent)
G1的老年代回收是并发的,需要在老年代占比达到一定阈值时触发并发标记周期。
默认值是45%,也就是当整个堆的占用率达到45%时,开始并发标记。
这个值的设置很关键:
-
太小 → 并发标记太频繁,吞吐量下降
-
太大 → 可能来不及回收,导致Full GC
我们的堆是5G,45%就是2.25G。但我们的老年代正常使用大概是2G左右,这个阈值可能有点低。
不过考虑到峰值流量时对象分配速度快,还是保守一点,设置成40%:
-XX:InitiatingHeapOccupancyPercent=40
3. 并行GC线程数(-XX:ParallelGCThreads)
这个参数设置STW阶段的GC线程数,默认是CPU核心数。
我们的机器是8核,但跑了2个实例,每个实例分4核比较合理:
-XX:ParallelGCThreads=4
4. 并发GC线程数(-XX:ConcGCThreads)
并发标记阶段的线程数,默认是ParallelGCThreads的1/4。
-XX:ConcGCThreads=1
4个并行线程的话,并发线程默认就是1个,不用改。
6.4 G1常见问题与优化
问题一:Young GC时间太长
可能原因:
-
年轻代太大
-
存活对象太多
-
目标停顿时间设置不合理
优化方法:
-
调小MaxGCPauseMillis,让G1自动减小年轻代
-
或者手动设置G1MaxNewSizePercent上限
问题二:Mixed GC回收效果不好
Mixed GC是G1特有的,同时回收年轻代和部分老年代Region。
如果Mixed GC回收效果不好,可能是:
-
每次回收的老年代Region太少
-
并发标记周期太长
优化方法:
# 增加每次Mixed GC回收的老年代Region数量
-XX:G1MixedGCCountTarget=8 # 默认8次Mixed GC完成回收
-XX:G1OldCSetRegionThresholdPercent=10 # 每次最多回收10%的老年代Region
问题三:Full GC
G1也会发生Full GC,通常是因为:
-
并发标记来不及,老年代满了
-
大对象太多,找不到连续的Region
-
元空间满了
Full GC对G1来说是灾难性的,因为G1的Full GC是单线程的(JDK 10以后改成多线程了),停顿时间非常长。
避免Full GC的方法:
-
调小InitiatingHeapOccupancyPercent,提早开始并发标记
-
调大堆内存
-
优化大对象
-
调大元空间
七、调优实战第四阶段:线程与锁优化
JVM调优不只是内存和GC,线程和锁也是重要的一环。
7.1 线程栈大小设置
每个线程都有自己的栈空间,默认大小是1M(64位JVM)。
-Xss512k
我们的应用线程数不多(Tomcat线程池200 + 其他业务线程约100 = 300个线程),1M也才300M,影响不大。
但如果你的应用有上千个线程,那栈空间占用就很可观了。这时候可以考虑把 -Xss 调小一点,比如256k或者512k。
注意:栈太小会导致StackOverflowError,特别是有深层递归调用的时候。我们的应用没有深层递归,512k足够了。
7.2 偏向锁与自旋锁
偏向锁(Biased Locking)
JDK 8默认是开启偏向锁的。偏向锁的思想是:如果一个锁总是被同一个线程获取,那么可以偏向这个线程,下次获取锁时不需要CAS操作,直接进入。
但是,如果有多个线程竞争同一个锁,偏向锁反而会有额外的撤销开销。
对于高并发的Web应用,锁竞争通常比较激烈,偏向锁的好处不大,反而可能因为锁撤销带来性能损耗。
所以很多人建议在高并发场景下关闭偏向锁:
-XX:-UseBiasedLocking
但是! 这个不能一概而论。要看你的应用里锁竞争的模式。
我们做了测试,关闭偏向锁后性能反而下降了约5%。因为我们的应用里大部分锁都是无竞争的(比如每个请求自己的对象锁),真正竞争的锁不多。
结论:偏向锁要不要关,一定要压测后再决定。
自旋锁(Spinning)
当一个线程等待锁时,不立即挂起,而是先自旋等待一会儿,看看锁会不会很快释放。如果自旋期间锁释放了,就避免了线程上下文切换的开销。
JDK 8默认开启自旋锁,自旋次数是自适应的(Adaptive Spinning)。
一般不需要调整这个参数,JVM自己会优化。
7.3 锁优化实践
除了JVM参数,代码层面的锁优化更重要。举几个我们实际做的优化:
优化一:减小锁粒度
// 反面示例:锁整个方法
public synchronized void updateOrder(OrderDO order) {
// 操作1:更新订单状态(需要锁)
// 操作2:发送MQ消息(不需要锁)
// 操作3:记录操作日志(不需要锁)
}
// 优化后:只锁需要同步的部分
public void updateOrder(OrderDO order) {
synchronized (this) {
// 只把需要同步的操作放锁里
updateOrderStatus(order);
}
// 这些操作移出锁外
sendMqMessage(order);
recordLog(order);
}
优化二:使用并发工具类代替synchronized
// 反面示例:用synchronized保护计数器
private int count = 0;
public synchronized void increment() {
count++;
}
// 优化后:使用AtomicInteger
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet();
}
优化三:读写锁分离
// 对于读多写少的场景,用ReentrantReadWriteLock
private ReadWriteLock rwLock = new ReentrantReadWriteLock();
public OrderDO getOrder(Long id) {
rwLock.readLock().lock();
try {
return orderMap.get(id);
} finally {
rwLock.readLock().unlock();
}
}
public void updateOrder(OrderDO order) {
rwLock.writeLock().lock();
try {
orderMap.put(order.getId(), order);
} finally {
rwLock.writeLock().unlock();
}
}
注意:JDK 8以后,ConcurrentHashMap的性能已经非常好了,大多数场景下直接用ConcurrentHashMap就行,不用自己搞读写锁。
八、调优实战第五阶段:JIT编译优化
很多人不知道,JIT编译也是可以调优的。虽然默认配置已经很好了,但了解一下总没坏处。
8.1 JIT编译模式
JVM有两种编译模式:
-
Client模式:编译速度快,启动快,但编译优化程度低,适合客户端应用
-
Server模式:编译速度慢,启动慢,但编译优化程度高,运行时性能好,适合服务端应用
64位JVM默认就是Server模式,不用改。
8.2 分层编译(Tiered Compilation)
JDK 8默认开启分层编译,JVM会根据代码的执行情况,逐步进行不同级别的优化:
-
第0层:解释执行
-
第1层:C1简单编译(快速编译)
-
第2层:C1受限编译
-
第3层:C1完全编译
-
第4层:C2完全优化编译(深度优化,耗时久)
分层编译的好处是:启动快,同时运行时能达到最高的优化水平。
一般不需要调整,默认就好。
8.3 方法内联
方法内联是JIT最重要的优化之一。把小方法的代码直接"复制粘贴"到调用处,消除方法调用的开销,同时为后续优化创造条件。
JVM会自动判断哪些方法需要内联,但有一些阈值参数可以调整:
# 方法字节码大小小于这个值,一定内联(默认35)
-XX:MaxInlineSize=35
# 频繁执行的方法(热方法),字节码大小小于这个值会内联(默认325)
-XX:FreqInlineSize=325
一般不建议改这些参数,改不好反而会有副作用。
代码层面可以做的优化:
-
尽量使用final方法、private方法、static方法,这些方法更容易被内联
-
方法不要写得太大,大方法不容易被内联
-
避免过度的抽象层次,层层调用会影响内联
8.4 逃逸分析与标量替换
这是JIT非常酷的一个优化。
逃逸分析:JIT分析一个对象的作用域,判断它会不会"逃逸"出方法外。
如果一个对象不会逃逸,那么JVM可以做:
-
标量替换:把对象拆散成基本类型,直接在栈上分配,不用在堆上分配,也就不需要GC回收
-
栈上分配:对象直接分配在栈上,方法返回时自动销毁
-
同步消除:如果锁对象不会逃逸,就可以消除同步
// 示例:这个Point对象不会逃逸,可以被标量替换
public int distance(int x1, int y1, int x2, int y2) {
Point p1 = new Point(x1, y1); // 不会逃逸
Point p2 = new Point(x2, y2); // 不会逃逸
return Math.sqrt(Math.pow(p1.x - p2.x, 2) + Math.pow(p1.y - p2.y, 2));
}
逃逸分析在JDK 8是默认开启的:
-XX:+DoEscapeAnalysis
代码层面的建议:
-
尽量减小对象的作用域,能在方法内new就不要在外面new
-
能返回基本类型就不要返回对象
-
不要为了"面向对象"而过度创建对象
九、调优效果验证与对比
经过前面几轮调优,我们来看看效果怎么样。先上一张直观的对比图:
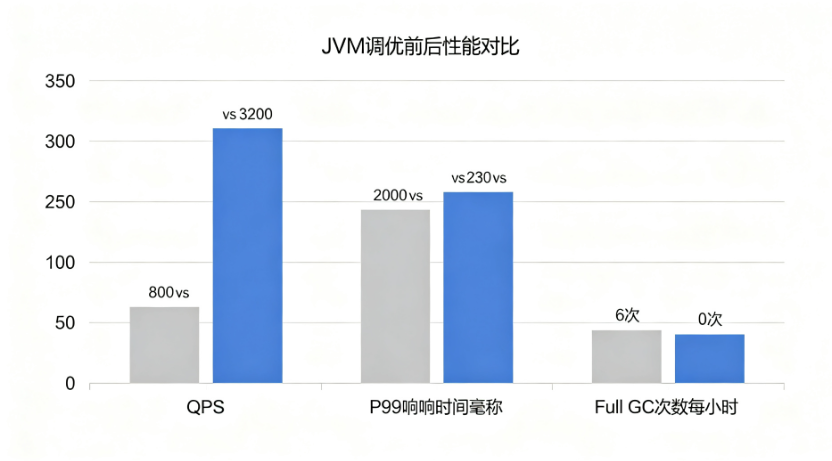
从图中可以直观地看到,调优后的各项指标都有了质的飞跃。
9.1 最终的JVM参数
先上最终的JVM参数配置:
# 堆内存设置
-Xms5g -Xmx5g
-Xmn2g
-XX:SurvivorRatio=4
-XX:MaxTenuringThreshold=15
# 元空间设置
-XX:MetaspaceSize=256m
-XX:MaxMetaspaceSize=512m
# 直接内存
-XX:MaxDirectMemorySize=512m
# 线程栈
-Xss512k
# G1垃圾回收器
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:G1HeapRegionSize=4m
-XX:InitiatingHeapOccupancyPercent=40
-XX:ParallelGCThreads=4
-XX:ConcGCThreads=1
# GC日志
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:+PrintHeapAtGC
-XX:+PrintTenuringDistribution
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintPromotionFailure
-XX:+PrintAdaptiveSizePolicy
-Xloggc:/var/log/gc-%t.log
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=10
-XX:GCLogFileSize=100M
# OOM时dump堆
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/var/log/heapdump.hprof
# 其他优化
-XX:+UseCompressedOops
-XX:+UseCompressedClassPointers
关于UseCompressedOops:压缩指针,64位JVM默认开启,能让堆内存小于32G时使用32位指针,节省内存。这个默认开启就好,不用管。
9.2 压测结果对比
| 指标 | 调优前 | 调优后 | 提升幅度 |
|---|---|---|---|
| QPS | 800 | 3200 | +300% |
| P99响应时间 | 2000ms | 230ms | -88.5% |
| 错误率 | 5% | 0.05% | -99% |
| Young GC频率 | 每3秒1次 | 每8秒1次 | -62.5% |
| Young GC平均耗时 | 87ms | 45ms | -48% |
| Full GC频率 | 每10分钟1次 | 无(压测30分钟) | -100% |
| 老年代使用率 | 95%+ | 稳定在40%左右 | -58% |
效果可以说是脱胎换骨! QPS从800提升到3200,翻了4倍;P99从2秒降到230毫秒;Full GC直接没了。
9.3 调优效果分析
为什么提升这么大?主要有几个原因:
1. 内存泄漏修复是关键
原来200M的ThreadLocal泄漏 + 120M的FastJSON缓存,加起来320M的内存泄漏。老年代总共才2.7G,泄漏就占了1/8,能不频繁Full GC吗?
修复后,老年代的内存占用直接降了一大截。
2. G1比Parallel GC更适合Web应用
Parallel GC是吞吐量优先的,但是停顿时间不可控。G1可以设置目标停顿时间,把停顿控制在200ms以内,对于Web应用来说体验好太多。
3. 年轻代和Survivor区的优化
调大了年轻代和Survivor区,减少了对象过早晋升,老年代增长速度慢了很多,自然就不需要频繁Full GC了。
十、面试高频考点与答题技巧
讲完了实战,我们回到面试。面试官问JVM调优,怎么回答才能显得你有实战经验,而不是只会背题?
10.1 经典问题:“说一下你的JVM调优经验”
错误回答:上来就背参数,什么-Xms、-Xmx、-XX:+UseG1GC…
正确回答思路:按照"背景→问题→分析→解决→效果"的结构来讲。
参考回答:
"我之前在电商项目中做过JVM调优。当时的背景是大促压测,系统QPS上不去,而且频繁Full GC。
我是这么做的:
先看GC日志,发现Full GC很频繁,而且回收效果不好,每次只回收几十兆,怀疑是内存泄漏。
然后dump堆内存,用MAT分析,发现是ThreadLocal没有清理导致的内存泄漏,还有FastJSON的反序列化器缓存膨胀。
先修代码问题:加了拦截器清理ThreadLocal,优化了FastJSON的缓存策略。
再调JVM参数:把堆内存从4G调到5G,年轻代设为2G,SurvivorRatio调成4。垃圾回收器从Parallel GC换成G1,设置了200ms的目标停顿时间,调整了并发标记触发阈值。
最后压测验证:QPS从800提升到3200,P99从2秒降到230ms,Full GC消失了。
我的体会是:JVM调优不能上来就改参数,80%的问题都是代码写得有问题。先定位根因,再针对性优化,最后一定要压测验证效果。"
这样回答,既有细节,又有逻辑,还有数据支撑,面试官一听就知道你是真做过的。
10.2 经典问题:“G1和CMS有什么区别?”
不要只说"G1是Region的,CMS是标记清除的",太浅了。
可以从这几个维度对比:
| 维度 | CMS | G1 |
|---|---|---|
| 内存布局 | 传统分代(年轻代+老年代,连续空间) | 分区(Region),逻辑分代,物理不连续 |
| 回收算法 | 标记-清除(老年代) | 整体标记-整理,局部复制 |
| 内存碎片 | 有(标记-清除导致) | 无(复制算法整理) |
| 停顿预测 | 不支持 | 支持(可设置MaxGCPauseMillis) |
| 适用堆大小 | 中小堆(建议4G以下) | 大堆(4G以上) |
| 并发性 | 老年代并发标记、并发清除 | 老年代并发标记,回收是STW但分多次 |
| Full GC触发 | 并发模式失败 | 复制失败、大对象分配失败等 |
| 大对象处理 | 直接进老年代 | Humongous区域专门存放 |
然后可以补充一下G1的优势:
-
可预测的停顿时间模型
-
不会产生内存碎片
-
大堆场景下表现更好
-
是JDK 9以后的默认回收器,未来的趋势
以及G1的劣势:
-
小堆场景下可能不如CMS
-
记忆集(Remembered Set)占用更多内存(约10%~20%)
-
调优相对复杂
10.3 经典问题:“怎么排查OOM?”
这是面试高频题,回答要体现出完整的排查思路。
参考回答:
"排查OOM我一般分几步:
第一步:保留现场
配置-XX:+HeapDumpOnOutOfMemoryError,OOM时自动dump堆快照。如果没配置,就用jmap -dump手动dump。第二步:初步分析
先看GC日志,看是哪种OOM:
堆内存OOM(java.lang.OutOfMemoryError: Java heap space)
GC overhead超限(GC overhead limit exceeded)
元空间OOM(Metaspace)
直接内存OOM(Direct buffer memory)
栈溢出(StackOverflowError)
不同类型的OOM原因不一样,排查方向也不同。第三步:堆内存分析
用MAT或者JProfiler打开堆快照:
先看Histogram,哪些对象实例数最多、占用内存最大
再看Dominator Tree,哪些大对象持有了最多内存
看Leak Suspects,MAT会自动分析可能的内存泄漏点
看对象的引用链,找到为什么这些对象没有被回收
第四步:定位代码
根据分析结果找到对应的代码,看是哪里创建了这些对象,为什么没有被回收。常见原因:
集合类内存泄漏(比如static的Map只put不remove)
ThreadLocal没有清理
各种缓存没有过期策略
大对象一次性加载太多
死循环导致对象不断创建
第五步:验证修复
修复后通过压测或者灰度发布,验证问题是否解决。"
10.4 经典问题:“年轻代和老年代比例怎么设置?”
错误回答:“1:2啊,默认就是这样。”
正确回答:要分情况讨论,没有万能的比例。
参考回答:
"这个没有固定的最佳比例,要根据业务场景来。
核心原则:让对象尽量在年轻代被回收,减少老年代的压力。
怎么确定比例?看GC日志:
看Young GC的频率和耗时:如果Young GC太频繁,说明年轻代小了,可以调大
看对象年龄分布:如果很多对象还没到年龄阈值就晋升了,说明Survivor区太小,可以调大SurvivorRatio或者调大年轻代
看老年代增长速度:如果老年代增长很快,Full GC频繁,说明对象过早晋升,需要增大年轻代
经验值参考:
对于大部分Web应用,对象都是朝生夕死的,年轻代可以设大一点,比如堆的1/3到1/2
如果应用有很多长生命周期对象(比如缓存),老年代可以设大一点
G1回收器不建议手动设置年轻代大小,让它自动调整更好,只需要设置目标停顿时间
调优步骤:
先从默认值(1:2)开始
收集GC日志,分析对象生命周期
逐步调整,每次只改一个参数
压测对比效果
总之,调优是个迭代的过程,没有一步到位的答案。"
十一、常见调优误区与避坑指南
JVM调优坑很多,我踩过不少,也见过很多人犯同样的错误。这里总结一下常见的误区。
11.1 误区一:堆内存越大越好
很多人觉得,内存不够就加内存嘛,内存越大性能越好。
错! 堆内存太大有几个问题:
-
GC停顿时间变长:堆越大,单次GC要扫描的内存越多,时间越长
-
排查问题困难:堆dump文件太大,分析工具打不开
-
浪费资源:很多时候不是内存不够,而是有内存泄漏
正确做法:够用就行,能满足业务峰值的情况下,堆越小越好。
11.2 误区二:上来就改参数,不先看日志
这是新手最容易犯的错误。一遇到性能问题,就百度搜"JVM调优参数",然后照着往JVM上加一堆参数。
结果:要么没效果,要么更糟。
正确做法:先收集数据(GC日志、堆dump、线程dump),分析清楚问题在哪,再针对性地调优。
11.3 误区三:只调JVM,不看代码
我见过很多团队,性能问题一出来就找运维调JVM参数,开发觉得跟自己没关系。
但实际上,80%的性能问题都是代码问题。内存泄漏、大对象、锁竞争、慢SQL…这些问题靠调JVM参数是解决不了的,顶多是延缓一下。
正确做法:JVM调优的第一步,永远是先排查代码问题。代码优化好了,JVM用默认参数都能跑得很好。
11.4 误区四:一次改多个参数
调优的时候,一次改好几个参数,然后跑压测,发现效果好了,也不知道是哪个参数起的作用;效果差了,也不知道是哪个参数搞坏的。
正确做法:每次只改一个参数,改完压测,记录效果。这样才能知道每个参数的影响,积累经验。
11.5 误区五:迷信某个回收器
“G1是最新的,肯定最好,全换成G1!”
不对,没有最好的回收器,只有最合适的。
-
小堆(2G以下)+ 客户端应用 → Serial GC可能就够了
-
后台计算、吞吐量优先 → Parallel GC
-
中等堆 + 低延迟 → CMS
-
大堆 + 低延迟 → G1
-
JDK 11+ + 超大堆 → ZGC
正确做法:根据业务场景和堆大小选择,压测对比后再决定。
11.6 误区六:调完就完事了
很多人调完一次,觉得性能达标了,就再也不管了。
但业务是不断变化的:代码在迭代、数据量在增长、用户量在增加。今天合适的参数,半年后可能就不合适了。
正确做法:建立监控,持续观察JVM指标,定期回顾和优化。
十二、JVM调优工具箱
工欲善其事,必先利其器。做JVM调优,这些工具你得会用。
12.1 JDK自带工具
这些工具是JDK自带的,不用额外安装,最常用。
| 工具 | 作用 | 常用命令 |
|---|---|---|
| jps | 查看Java进程 | jps -l |
| jstat | 查看JVM运行时统计信息 | jstat -gcutil <pid> 1000 10 |
| jmap | 生成堆dump、查看堆信息 | jmap -histo:live <pid>、jmap -dump:file=heap.hprof <pid> |
| jstack | 生成线程dump | jstack <pid> > thread.txt |
| jinfo | 查看/修改JVM参数 | jinfo -flags <pid> |
| jhat | 分析堆dump(浏览器查看) | jhat heap.hprof |
| jconsole | 图形化监控工具 | 直接运行jconsole |
| jvisualvm | 可视化分析工具(JDK 8有,JDK 9以后独立了) | 直接运行jvisualvm |
jstat常用命令示例:
# 查看GC统计,每秒刷新一次,共10次
jstat -gcutil <pid> 1000 10
# 输出说明:
# S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
# S0:Survivor0使用率
# S1:Survivor1使用率
# E:Eden区使用率
# O:老年代使用率
# M:元空间使用率
# YGC:Young GC次数
# YGCT:Young GC总耗时
# FGC:Full GC次数
# FGCT:Full GC总耗时
# GCT:GC总耗时
12.2 第三方工具
MAT(Memory Analyzer Tool)
-
Eclipse出品的堆内存分析工具
-
功能强大,能自动分析内存泄漏
-
推荐:⭐⭐⭐⭐⭐
GCViewer
-
GC日志可视化工具
-
能直观看到GC频率、停顿时间、内存变化趋势
-
推荐:⭐⭐⭐⭐
GCEasy
-
在线GC日志分析工具
-
上传GC日志文件,自动生成分析报告
-
推荐:⭐⭐⭐⭐
Arthas
-
阿里开源的Java诊断工具
-
功能非常强大:方法耗时、火焰图、热更新、反编译…
-
强烈推荐,线上排查问题神器
-
推荐:⭐⭐⭐⭐⭐
Prometheus + Grafana
-
监控系统,配合JMX Exporter可以监控JVM指标
-
适合长期监控和告警
-
推荐:⭐⭐⭐⭐
12.3 常用调优命令速查
# 查看JVM参数
jinfo -flags <pid>
# 查看堆内存使用情况
jmap -heap <pid>
# 查看对象统计(只统计存活对象)
jmap -histo:live <pid> | head -30
# dump堆内存
jmap -dump:format=b,file=/tmp/heap.hprof <pid>
# 查看线程栈
jstack <pid> > /tmp/thread.txt
# 实时查看GC情况
jstat -gcutil <pid> 1000
# 查看系统中所有Java进程
jps -lvm
十三、进阶:JVM调优的道与术
讲了这么多"术"(具体的参数和方法),最后聊聊"道",也就是JVM调优的方法论和思维方式。
13.1 调优的本质是什么?
JVM调优的本质,是在吞吐量、延迟、内存占用这三者之间做权衡。
-
吞吐量:单位时间内系统能处理的请求数,越高越好
-
延迟:请求的响应时间,越低越好
-
内存占用:系统占用的内存,越少越好
这三者是不可能同时最优的,你必须根据业务场景做取舍:
-
后台批处理任务:吞吐量优先,延迟不重要 → Parallel GC
-
Web应用:延迟优先,用户体验最重要 → G1、CMS、ZGC
-
嵌入式/客户端:内存优先 → Serial GC
没有最好的配置,只有最合适的配置。
13.2 什么时候需要调优?
不是所有系统都需要JVM调优。很多系统用默认参数跑得好好的,根本没必要调。
出现这些情况时,才需要考虑调优:
-
Full GC频繁:比如每小时好几次,或者每次停顿时间很长
-
OOM:频繁出现内存溢出
-
性能不达标:QPS上不去,响应时间太长
-
CPU占用过高:GC线程占用太多CPU
-
内存占用过高:机器内存不够用
如果系统跑得好好的,就别瞎调了。“If it ain’t broke, don’t fix it.”
13.3 调优的一般步骤
总结一下通用的调优流程,这张图可以帮你快速记忆: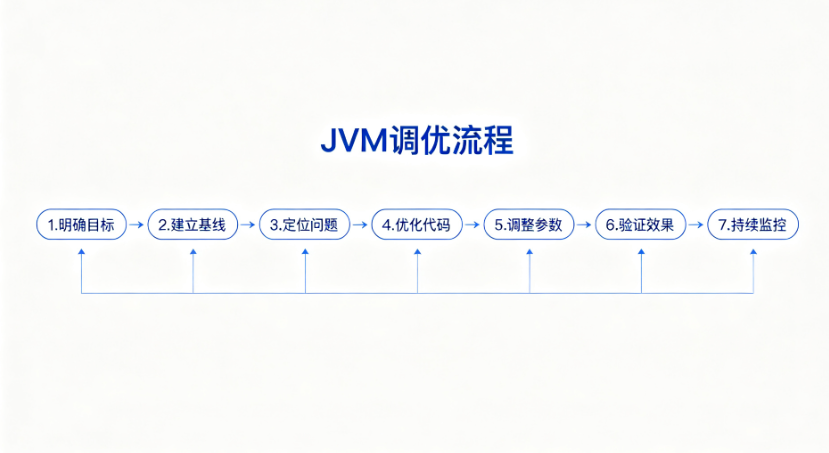
如图所示,完整的调优流程分为7个步骤:
第一步:明确目标
-
业务目标是什么?(QPS、响应时间、错误率)
-
资源约束是什么?(CPU、内存、机器数量)
第二步:建立基线
-
收集当前的性能数据
-
开启GC日志、JMX监控
-
做一轮基准压测
第三步:定位问题
-
分析GC日志,看是GC频率高还是停顿时间长
-
分析堆内存,看有没有内存泄漏
-
分析线程,看有没有锁竞争、死锁
-
定位瓶颈在哪:内存?CPU?IO?
第四步:优化代码
-
先解决代码层面的问题:内存泄漏、大对象、锁优化…
-
代码优化是性价比最高的调优
第五步:调整JVM参数
-
内存大小设置(堆、年轻代、元空间)
-
垃圾回收器选择与调优
-
每次只改一个参数
第六步:验证效果
-
压测对比
-
看指标有没有改善
-
有没有引入新的问题
第七步:持续监控
-
建立监控和告警
-
定期回顾
-
业务变化时重新评估
13.4 调优的境界
我把JVM调优分成几个境界:
第一重:背参数
-
知道常用的JVM参数有哪些
-
知道-Xms、-Xmx是什么意思
-
面试能说上几句
第二重:会调参
-
能看懂GC日志
-
知道怎么调整年轻代大小
-
能根据场景选择垃圾回收器
-
调完能看到效果
第三重:懂原理
-
理解垃圾回收算法的原理
-
知道JVM内存模型的细节
-
能解释为什么这么调
-
能排查复杂的内存问题
第四重:会写代码
-
写出对JVM友好的代码
-
知道怎么避免内存泄漏
-
知道怎么减少GC压力
-
从源头避免性能问题
第五重:体系化思维
-
能从系统层面考虑性能问题
-
知道JVM只是性能优化的一环
-
能平衡性能、可维护性、开发效率
-
知道什么时候该调,什么时候不该调
大部分人停留在第二重,面试够了,但实际工作中还不够。真正的高手是第四重、第五重,他们不怎么调JVM,因为他们写的代码本身就很高效,JVM用默认参数就能跑得很好。
结语
这篇文章写了这么多,从实战案例到面试技巧,从具体参数到方法论,希望能帮你把JVM调优这件事真正搞明白。
最后再强调几句:
-
JVM调优不是银弹,很多性能问题的根因在代码、在架构、在数据库,不要什么都指望JVM调优来解决。
-
调优是科学,不是玄学。一切以数据为准,先测量再分析,有依据地调整,用实验验证效果。
-
过早优化是万恶之源。系统跑得好好的就别瞎调,等真的出现性能问题了再优化也不迟。
-
持续学习。JVM一直在演进,G1还没搞明白,ZGC、Shenandoah又来了。保持学习的心态,才能跟上技术的发展。
如果你觉得这篇文章对你有帮助,欢迎分享给更多的朋友。也欢迎在评论区交流你的JVM调优经验和踩过的坑。
愿你面试时能从容应对,工作中能游刃有余。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


