
本文核心价值:一套经过线上实战验证的OOM排查方法论——5步定位法,涵盖从现场保护到根因定位的完整流程,配有大量代码示例和实战案例,帮助Java开发者在10分钟内快速定位OOM根因。全文约15000字,建议收藏后阅读。
前言
凌晨三点,监控系统突然发出刺耳的告警声——线上核心Java服务 内存 使用率飙升至98%,紧接着服务实例开始接连宕机。睡眼惺忪的你被电话叫醒,面对屏幕上满屏的java.lang.OutOfMemoryError,手心瞬间冒出冷汗。
相信每一位Java后端开发者都有过 类 似的噩梦经历。OOM(OutOfMemoryError)作为Java线上最致命的故障之一,往往来得突然、影响范围广、排查难度大。如果没有一套系统化的排查方法论,很容易在慌乱中错失最佳定位时机,甚至因为操作不当破坏了现场,导致事后无法复盘。
本文将分享一套经过线上实战验证的OOM排查方法论——5步定位法。按照这套流程,即使是经验尚浅的开发者,也能在10分钟内快速定位OOM根因,为修复争取宝贵时间。
一、OOM到底是什么?为什么这么可怕?
在正式进入排查步骤之前,我们先花几分钟搞清楚OOM的本质。很多开发者天天把OOM挂在嘴边,但真要问起来OOM有多少种、分别对应JVM内存模型的哪个区域,未必能说得清楚。
1.1 JVM内存模型回顾
根据JVM规范,Java虚拟机在执行Java程序时会把它管理的内存划分为若干个不同的数据区域:
-
堆(Heap):所有线程共享,用于存放对象实例和数组,是GC的主要区域
-
方法区(Method Area):所有线程共享,用于存储已被虚拟机加载的类信息、常量、静态变量等数据。JDK 8之后演变为元空间(Metaspace)
-
虚拟机栈(VM Stack):线程私有,每个方法执行时都会创建一个栈帧,存储局部变量表、操作数栈、动态链接等
-
本地方法栈(Native Method Stack):为Native方法服务
-
程序计数器(Program Counter Register):线程私有,记录当前线程执行的字节码行号
-
直接内存(Direct Memory):不属于JVM运行时数据区,但被频繁使用,NIO的DirectByteBuffer就在这里
不同区域的内存耗尽,会抛出不同类型的OOM异常。理解这一点,是快速定位的第一步。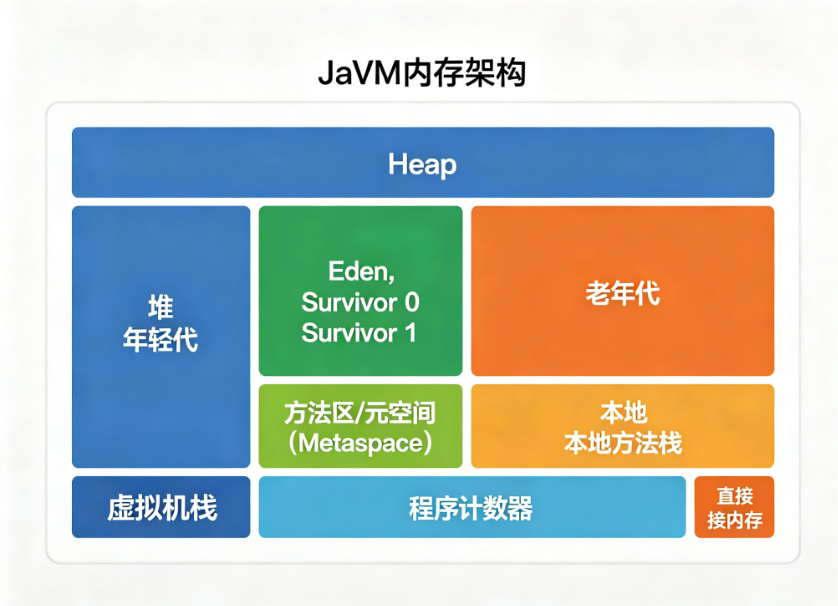
1.2 OOM的危害
为什么线上OOM如此可怕?主要有以下几个原因:
第一,突发性强。 OOM往往没有明显预兆,可能前一秒服务还正常运行,后一秒就突然宕机。不像CPU飙高还能有个缓冲期,OOM常常是"秒崩"。
第二,影响范围广。 一旦服务发生OOM,轻则响应变慢、接口报错,重则整个实例宕机,导致业务中断。如果是核心服务,还可能引发雪崩效应,拖垮上下游。
第三,排查难度大。 OOM的原因千奇百怪,可能是代码bug、流量突增、配置不合理、依赖问题等等。如果没有系统的方法,很容易像无头苍蝇一样乱撞。
第四,现场易丢失。 很多人遇到OOM第一反应就是重启服务,但重启之后内存状态就清空了,堆转储文件也可能被覆盖。没有现场,事后排查就成了无源之水。
正是因为这些特点,掌握一套高效的OOM排查方法论就显得尤为重要。
二、步骤一:快速止损与现场保护
核心原则:先止损,再排查;先保现场,再分析。
当线上发生OOM时,很多人的第一反应是"赶紧重启"。但请记住:重启是最后手段,不是第一选择。 在重启之前,你必须先做好两件事:止损和保现场。
2.1 第一时间止损
OOM发生后,服务已经处于不正常状态,继续承接流量只会让情况更糟。所以第一步是快速止损,把影响范围控制住。
常见的止损手段:
-
流量切走:如果有负载均衡或网关,立即把出问题的实例摘下来,不让流量继续打进去
-
服务降级:如果是核心功能出问题,考虑开启降级开关,暂时关闭非核心功能
-
限流保护:如果流量突增导致OOM,立即开启限流,把QPS控制在安全范围内
-
扩容兜底:如果还有可用资源,紧急扩容几个实例来承接流量,保证业务可用
💡 经验之谈:止损的速度直接决定了故障的影响时长。平时就应该把各种止损预案准备好,比如一键摘流、一键降级、一键扩容,关键时刻才能秒级响应。
2.2 为什么不能立刻重启?
很多人会问:服务都挂了,不重启留着过年吗?
答案是:为了保留现场。
OOM的原因藏在内存里,一旦重启,内存中的所有对象信息都会消失,就像案发现场被破坏了一样。到时候你只能对着日志干瞪眼,却永远无法知道到底是哪个对象占满了内存。
所以正确的做法是:先把出问题的实例隔离(不接流量),然后保留现场,等dump文件生成完、关键信息收集完,再考虑重启。
2.3 生成堆转储文件(Heap Dump)
堆转储文件是OOM排查的"黄金证据"。它是JVM堆内存的一个快照,包含了当时所有对象的信息。有了它,我们就能知道到底是什么对象占了这么多内存。
方法一:自动生成(推荐提前配置)
最好的方式是在JVM启动参数中提前配置,让OOM发生时自动生成dump文件:
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/var/log/java/heapdump.hprof
这两个参数的作用是:当发生OOM时,自动把堆内存快照输出到指定路径。
⚠️ 注意事项:
-
dump文件大小约等于堆内存大小,确保磁盘有足够空间
-
生成dump文件会暂停应用,时间从几秒到几分钟不等
-
生产环境建议配置,这是线上排查的"救命稻草"
方法二:手动生成
如果没有提前配置自动dump,也可以手动生成:
# 先找到Java进程ID
jps -l
# 生成堆转储文件
jmap -dump:format=b,file=/path/to/heapdump.hprof <pid>
# 或者只dump存活对象(更快,但信息少一些)
jmap -dump:live,format=b,file=/path/to/heapdump.hprof <pid>
jmap是JDK自带的工具,-dump:format=b表示以二进制格式dump,live参数表示只dump存活的对象(会先触发一次Full GC)。
💡 小技巧:如果担心jmap执行时间太长影响服务,可以先把进程挂起(gcore),再慢慢分析。不过一般情况下,既然已经OOM了,服务基本也不可用了,直接dump就行。
2.4 收集关键信息
除了dump文件,还有很多信息需要同步收集,这些信息对后续排查至关重要:
1. JVM参数配置
# 查看JVM启动参数
jinfo -flags <pid>
# 查看堆内存配置
jmap -heap <pid>
知道了JVM是怎么配置的,才能判断是不是参数设置不合理导致的OOM。比如堆内存是不是设小了?元空间是不是不够?GC策略是不是选错了?
2. GC日志
如果配置了GC日志,赶紧把日志文件保存下来。GC日志能告诉你:内存是怎么增长的?GC的频率和耗时如何?是慢慢泄漏还是突然暴涨?
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintHeapAtGC
-Xloggc:/var/log/java/gc.log
3. 应用日志和错误日志
查看OOM发生前后的应用日志,看看有没有异常栈、有没有什么特殊的业务操作、有没有报错信息。很多时候,OOM的异常栈本身就能提供重要线索。
4. 服务器基本信息
# 查看内存使用情况
free -h
# 查看CPU使用情况
top -p <pid>
# 查看磁盘使用情况
df -h
确认一下是不是机器本身的内存就不够了,或者是不是磁盘满了导致其他问题。
5. 业务上下文
问问业务方:OOM发生时在做什么操作?有没有上线?有没有搞活动?有没有批量任务在跑?这些信息能帮你快速缩小排查范围。
📝 检查清单:发生OOM后,先确认以下信息是否都收集到了:
-
堆转储文件(.hprof)
-
JVM启动参数
-
GC日志
-
应用日志/错误日志
-
服务器基本信息
-
业务上下文信息
三、步骤二:初步定位OOM类型
拿到现场信息后,先别急着打开MAT分析dump文件。第二步,我们先做个"初诊",判断一下是哪种类型的OOM,这样后续才能对症下药。
3.1 常见的OOM类型大盘点
Java中的OOM可不只有一种,不同类型的OOM对应不同的内存区域,排查思路也完全不同。
类型一:Java heap space(堆内存溢出)
java.lang.OutOfMemoryError: Java heap space
这是最常见的OOM类型,意思是堆内存不够用了。可能的原因:
-
堆内存设置太小
-
内存泄漏:对象无法被回收,越积越多
-
突然创建了超大对象或大量对象
类型二:GC overhead limit exceeded(GC开销超限)
java.lang.OutOfMemoryError: GC overhead limit exceeded
这个OOM的意思是:GC占用了太多时间,却回收不了多少内存。JDK的默认阈值是:GC时间超过98%,但回收的内存不到2%,就会抛出这个错误。
通常这是内存泄漏的"前兆"——堆内存快满了,GC频繁执行但效果甚微,最后彻底撑爆。
类型三:Metaspace(元空间溢出)
java.lang.OutOfMemoryError: Metaspace
JDK 8之后,永久代被元空间取代,元空间使用的是本地内存。如果元空间溢出,说明加载的类太多了。可能的原因:
-
元空间设置太小
-
动态生成的类太多(比如CGLIB动态代理、反射、JSP等)
-
类加载器泄漏
类型四:Direct buffer memory(直接内存溢出)
java.lang.OutOfMemoryError: Direct buffer memory
直接内存溢出,通常和 NIO 有关。Java的NIO可以使用DirectByteBuffer直接分配堆外内存,这部分内存不受堆大小限制,但受限于物理内存。如果直接内存用太多,就会报这个错。
常见于使用Netty、Mina等NIO框架的场景。
类型五:unable to create new native thread(无法创建新线程)
java.lang.OutOfMemoryError: unable to create new native thread
这个OOM的意思是:创建线程失败了。每个线程都需要占用一定的栈内存,当线程数量太多时,系统没有足够的资源来创建新线程。
可能的原因:
-
线程池配置不合理,最大线程数设太大
-
线程泄漏:线程创建了没销毁,越积越多
-
系统限制:操作系统对进程的最大线程数有限制
类型六:StackOverflowError(栈溢出)
java.lang.StackOverflowError
严格来说这不是OOM,但也是常见的内存相关错误。栈溢出通常是因为方法调用层次太深,比如递归没有正确的退出条件。
3.2 从错误信息快速判断类型
其实最简单的方法就是直接看错误信息。上面列出的每种OOM都有明确的错误提示,看到错误信息基本就能判断类型。
比如看到Java heap space,那就是堆的问题,重点分析堆转储;看到Metaspace,就去查类加载的问题;看到Direct buffer memory,就去看NIO相关的代码。
3.3 分析GC日志,看内存变化趋势
如果错误信息不够明确,或者想进一步确认,就来分析GC日志。GC日志能清晰地展示内存的变化趋势,帮你判断是"慢慢泄漏"还是"突然撑爆"。
GC日志怎么看?
我们来看一段典型的GC日志(JDK 8,Parallel GC):
2024-01-15T10:23:45.123+0800: [GC (Allocation Failure) [PSYoungGen: 65536K->8192K(76288K)] 146432K->89088K(251392K), 0.0254321 secs] [Times: user=0.05 sys=0.01, real=0.03 secs]
我们来拆解一下:
-
2024-01-15T10:23:45.123+0800:GC发生的时间 -
GC (Allocation Failure):这是一次Young GC,原因是分配失败 -
PSYoungGen: 65536K->8192K(76288K):年轻代GC前65536K,GC后8192K,总大小76288K -
146432K->89088K(251392K):整个堆GC前146432K,GC后89088K,总大小251392K -
0.0254321 secs:GC耗时 -
[Times: user=0.05 sys=0.01, real=0.03 secs]:用户态、内核态、实际耗时
Full GC的日志类似,只是开头是Full GC。
关键观察点:
-
堆内存使用趋势:每次GC后,老年代的使用量是不是在持续上涨?如果每次GC后老年代回收不完,而且一次比一次高,那大概率是内存泄漏。
-
GC频率:Young GC和Full GC的频率如何?如果Full GC越来越频繁,说明内存压力越来越大。
-
GC耗时:GC耗时是不是越来越长?特别是Full GC,如果一次要好几秒甚至几十秒,那服务基本就卡得不能用了。
-
晋升速率:每次Young GC后,有多少对象晋升到老年代?如果晋升速率很高,说明对象存活时间长,老年代增长快。
GC日志 分析工具
手动看GC日志太累了,推荐用工具:
-
GCEasy:在线工具,上传GC日志就能生成可视化报告,非常好用
-
GCViewer:桌面端工具,开源免费
-
HPjmeter:功能强大的分析工具
💡 经验之谈:如果GC日志显示老年代内存是"阶梯式"上涨,每次GC后都比上一次高一点,那基本就是内存泄漏没跑了。如果是突然一下涨到顶,那可能是某一次操作创建了大量对象。
3.4 使用jstat实时监控
如果服务还没挂,只是内存飙高,那可以用jstat实时监控内存变化。
# 查看GC统计信息,每1秒输出一次,共输出10次
jstat -gcutil <pid> 1000 10
输出大概长这样:
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 98.31 96.23 85.67 76.43 73.21 123 2.345 5 1.234 3.579
各列含义:
-
S0、S1:Survivor 0和Survivor 1区使用率 -
E:Eden区使用率 -
O:老年代使用率 -
M:元空间使用率 -
CCS:压缩类空间使用率 -
YGC:Young GC次数 -
YGCT:Young GC总耗时 -
FGC:Full GC次数 -
FGCT:Full GC总耗时 -
GCT:GC总耗时
通过jstat,你可以实时观察各个内存区域的变化情况,判断是哪个区域在涨。
四、步骤三:深入分析堆转储文件
如果初步判断是堆内存溢出,那第三步就是重头戏——分析堆转储文件。这一步是整个排查过程的核心,也是最能体现技术功底的地方。
4.1 堆转储文件是什么?
堆转储文件(Heap Dump)是JVM堆内存在某一时刻的快照,通常是.hprof格式的二进制文件。它包含了:
-
所有的对象信息:类、成员变量、值
-
所有的类信息:类加载器、类名、静态变量
-
对象之间的引用关系
-
GC Roots信息
简单说,dump文件就是当时堆内存的"全景照片",有了它,我们就能知道内存里到底有什么。
4.2 常用分析工具对比
分析dump文件的工具有很多,各有特点:
| 工具 | 特点 | 适用场景 |
|---|---|---|
| Eclipse MAT | 功能强大,有泄漏嫌疑报告,支持OQL | 最常用,推荐首选 |
| VisualVM | JDK自带,界面友好,功能全面 | 简单分析、监控 |
| jhat | JDK自带,命令行工具,生成网页 | 简单快速查看 |
| YourKit | 商业软件,功能强大,性能好 | 深度分析、性能调优 |
| JProfiler | 商业软件,功能全面 | 专业级分析 |
推荐首选Eclipse MAT(Memory Analyzer Tool),它是专门用来分析内存泄漏的工具,功能强大而且免费。下面我们就以MAT为例,讲讲怎么分析dump文件。
4.3 MAT工具深度使用指南
4.3.1 打开dump文件
打开MAT,选择File -> Open Heap Dump,选择你的.hprof文件。第一次打开会比较慢,因为MAT需要解析整个dump文件并构建索引。大的dump文件(几个G)可能需要十几分钟甚至更久,耐心等待。
打开之后,MAT会自动弹出一个向导,问你想做什么分析。一般选择Leak Suspects Report(泄漏嫌疑报告)就行,这是最常用的。
4.3.2 Leak Suspects Report (泄漏嫌疑报告)
这是MAT最贴心的功能——自动帮你找可能的内存泄漏点。报告会列出几个"嫌疑犯",每个嫌疑犯都是一个占用内存很大的对象,并且MAT会给出分析和建议。
报告通常包含:
-
Problem Suspect:嫌疑对象的描述,占用了多少内存,占总内存的百分比
-
Description:详细描述,比如哪个类的对象、有多少个实例
-
Shortest Paths To the Accumulation Point:从GC Roots到这个对象的最短引用链
-
Accumulated Objects in Dominator Tree:支配树中的对象统计
很多时候,看完泄漏嫌疑报告,你就能大概知道问题出在哪了。比如报告显示有一个HashMap占用了80%的内存,里面存了几百万个对象,那你就知道要去查这个HashMap是哪里来的。
4.3.3 Histogram(直方图)
如果想自己看所有对象的统计信息,就打开Histogram视图。直方图按类列出了每个类有多少个实例、占用了多少内存(浅堆和深堆)。
什么是浅堆(Shallow Heap)和深堆(Retained Heap)?
-
浅堆:对象本身占用的内存大小,不包括它引用的对象
-
深堆:对象被GC回收后,能释放的总内存大小,包括这个对象本身和它直接或间接引用的所有对象
简单说,浅堆是"自己有多大",深堆是"它带着多大的家当"。找内存泄漏主要看深堆,因为深堆大说明这个对象"hold住"了很多内存。
Histogram视图默认按类名排序,你可以点击列标题切换排序方式。通常我们会按深堆降序排列,看看哪些类的对象占用内存最多。
4.3.4 Dominator Tree(支配树)
支配树是MAT中一个非常重要的概念。简单说,支配树展示了对象之间的"支配关系"——如果所有到达对象B的路径都必须经过对象A,那A就支配B。
支配树的作用是:快速找到占用内存最多的对象,以及它们为什么还活着。
在支配树视图中,每个节点下面的子节点就是被它支配的对象。节点的大小表示它的深堆大小。这样你就能一眼看到:哪个对象是"内存大户",它又持有了哪些对象。
4.3.5 Path to GC Roots(GC Roots引用链)
找到了占用内存大的对象后,接下来要问:为什么这些对象没有被GC回收?
答案就在GC Roots引用链里。GC Roots是垃圾回收的起点,所有从GC Roots可达的对象都是"存活"的,不会被回收。
在MAT中,右键点击一个对象,选择Path to GC Roots -> exclude weak/soft references,就能看到从GC Roots到这个对象的完整引用链。
通过引用链,你就能知道:这个对象是被谁引用的?是被静态变量持有?还是被某个集合持有?还是被线程上下文持有?顺着引用链往上找,就能找到"罪魁祸首"。
💡 小技巧:排除弱引用和软引用,因为它们本来就可能被GC回收,通常不是泄漏的原因。重点看强引用链。
4.3.6 OQL(Object Query Language)
MAT还支持OQL,一种类似SQL的查询语言,可以用代码的方式查询对象。当你需要做一些复杂的筛选时,OQL非常有用。
常用OQL示例:
-- 查询所有String对象,按长度排序
SELECT s FROM java.lang.String s ORDER BY s.value.length DESC
-- 查询所有HashMap的大小
SELECT map, map.size FROM java.util.HashMap map
-- 查询包含"leak"关键字的字符串
SELECT s FROM java.lang.String s WHERE s.toString().contains("leak")
-- 查询某个类的所有实例
SELECT * FROM com.example.service.UserService
OQL的语法很灵活,熟练使用能大大提高分析效率。
4.4 常见的内存泄漏模式
分析dump文件多了,你会发现很多内存泄漏都是"套路"。下面总结几种最常见的内存泄漏模式,遇到类似情况可以直接对号入座。
模式一:集合类泄漏
这是最常见的泄漏模式。集合(HashMap、ArrayList等)持有了大量对象,但这些对象用完了却没有从集合中移除,导致越积越多。
典型代码:
public class CacheService {
// 静态集合,生命周期和JVM一样长
private static final Map<String, Object> cache = new HashMap<>();
public void put(String key, Object value) {
cache.put(key, value);
}
// 只有put,没有remove,也没有过期策略
// 时间长了cache就会越来越大,最终OOM
}
特征:
-
dump中某个HashMap或ArrayList特别大
-
里面的对象数量异常多
-
引用链通常能追到一个静态变量或长生命周期对象
修复方法:
-
使用带过期策略的缓存(如Guava Cache、Caffeine)
-
设置最大容量,超过就淘汰
-
用完及时remove
模式二:静态集合引用
和上面类似,但更隐蔽——静态变量持有集合引用,而集合里又持有了大量对象。因为静态变量的生命周期和类一样长,只要类不卸载,这些对象就永远不会被回收。
典型代码:
public class AppContext {
// 静态的ApplicationContext,持有大量对象
private static ApplicationContext context;
// ...
}
特征:
-
引用链的根是static字段
-
通常是全局上下文、工具类、单例等
模式三:单例模式导致的泄漏
单例模式本身没问题,但如果单例持有了不该持有的对象,就会造成泄漏。比如单例持有了Activity的引用(Android场景),或者持有了大量业务数据。
典型代码:
public class Singleton {
private static Singleton instance;
private List<Object> data = new ArrayList<>();
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
public void addData(Object obj) {
data.add(obj); // 只加不删,越积越多
}
}
模式四:未关闭的资源
数据库连接、文件流、网络连接等资源,如果用完不关闭,也会造成内存泄漏。虽然这些资源很多是堆外的,但它们在堆上也会有对应的对象,而且这些对象通常会占用不少内存。
典型代码:
public void readFile(String path) {
try {
FileInputStream fis = new FileInputStream(path);
// 读取文件...
// 忘记关闭fis了!
} catch (IOException e) {
e.printStackTrace();
}
}
修复方法:
-
使用try-with-resources自动关闭
-
在finally块中关闭
-
使用连接池,定期检查泄漏
模式五:监听器和回调未注销
注册了监听器或回调,但用完了没注销,导致发布者一直持有订阅者的引用,订阅者无法被回收。
典型代码:
public class UserService {
public void register(EventListener listener) {
eventBus.register(listener);
}
// 只有register,没有unregister
}
特征:
-
事件总线、消息队列、观察者模式
-
订阅者对象无法被回收
模式六:ThreadLocal泄漏
ThreadLocal是个好东西,但用不好很容易造成内存泄漏。ThreadLocal的原理是:每个Thread都有一个ThreadLocalMap,key是ThreadLocal的弱引用,value是实际的值。
如果ThreadLocal是静态的,或者线程是线程池中的线程(生命周期很长),那么即使ThreadLocal本身被回收了(弱引用),value也不会被回收,因为Thread还在。
典型代码:
public class UserContext {
private static final ThreadLocal<User> userThreadLocal = new ThreadLocal<>();
public static void setUser(User user) {
userThreadLocal.set(user);
}
public static User getUser() {
return userThreadLocal.get();
}
// 忘记remove了!线程池中的线程会一直持有User对象
}
修复方法:
-
使用完ThreadLocal后,一定要调用remove()方法
-
最好在finally块中remove
模式七:缓存泄漏
缓存是内存泄漏的重灾区。很多人做缓存时,只考虑了"存",没考虑"清",结果缓存越做越大,最后撑爆内存。
典型问题:
-
缓存没有过期时间
-
缓存没有最大容量限制
-
缓存淘汰策略不合理
修复方法:
-
使用专业的缓存框架(Guava Cache、Caffeine、Redis)
-
设置合理的过期时间和最大容量
-
选择合适的淘汰策略(LRU、LFU等)
五、步骤四:代码级根因定位
通过第三步的dump分析,你应该已经找到了"嫌疑对象"——比如某个HashMap特别大,或者某个类的实例特别多。但这还不够,你还需要找到对应的代码位置,搞清楚为什么会产生这么多对象。
这就是第四步:代码级根因定位。
5.1 结合业务场景缩小范围
找到了问题对象,先别急着翻代码。先结合业务场景分析一下,能帮你快速缩小范围。
问问自己这些问题:
-
什么时候发生的? 是刚上线就出问题?还是运行了好几天才出问题?还是某个时间点突然出问题?
-
刚上线就出问题:大概率是新代码有bug
-
运行几天才出问题:内存泄漏,慢慢积累
-
某个时间点突然出问题:可能是某个活动、某个批量任务、某个特殊请求触发的
-
-
什么操作触发的? 是用户在做什么操作的时候出的问题?是某个接口?还是某个定时任务?
-
如果是某个接口,就去查这个接口的代码
-
如果是定时任务,就去看任务逻辑
-
-
涉及哪些模块? 从dump中看到的对象属于哪个业务模块?是用户模块?订单模块?还是某个中间件?
-
最近有没有变更? 最近有没有上线?有没有改配置?有没有换依赖版本?
把这些问题想清楚,排查范围就能从"整个项目"缩小到"某几个类",效率大大提升。
5.2 代码审查要点
缩小范围后,就开始看代码吧。重点关注以下几种"高危"代码:
5.2.1 大对象创建
有没有哪里创建了很大的对象?比如:
-
一次性从数据库查出几万条数据,全部加载到内存
-
读取大文件,整个读进内存
-
构造巨大的List、Map
-
字符串拼接,生成超长字符串
反例:
// 一次性查出所有用户,几百万条数据全部加载到内存
List<User> allUsers = userMapper.selectAll();
正例:
// 分页查询,每次只查一页
int pageSize = 1000;
for (int i = 0; ; i++) {
List<User> users = userMapper.selectByPage(i * pageSize, pageSize);
if (users.isEmpty()) {
break;
}
// 处理当前页
process(users);
}
5.2.2 循环中创建对象
有没有在循环里创建对象?特别是大循环,如果每次循环都创建对象,而且对象还不能被回收,那很快就OOM了。
反例:
List<String> result = new ArrayList<>();
for (int i = 0; i < 1000000; i++) {
String s = "data_" + i + "_" + heavyComputation(i);
result.add(s);
}
5.2.3 集合使用不当
集合是内存泄漏的高发区,重点检查:
-
集合是不是只加不减?
-
有没有设置最大容量?
-
有没有过期清理机制?
-
是不是静态集合?
-
key是不是正确重写了hashCode和equals?
反例:
private static final Map<String, Object> cache = new HashMap<>();
public void put(String key, Object value) {
cache.put(key, value);
}
5.2.4 静态变量滥用
静态变量的生命周期和类一样长,持有对象很容易造成泄漏。重点检查:
-
静态集合
-
静态单例
-
静态缓存
-
静态的上下文对象
5.2.5 资源未关闭
文件流、数据库连接、网络连接、HttpClient等,用完了有没有关闭?
反例:
public String httpGet(String url) throws IOException {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response = httpClient.execute(httpGet);
return EntityUtils.toString(response.getEntity());
}
正例:
public String httpGet(String url) throws IOException {
try (CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = httpClient.execute(new HttpGet(url))) {
return EntityUtils.toString(response.getEntity());
}
}
5.3 结合日志追踪
代码看了一圈,如果还没找到问题,就去翻日志。日志里往往藏着重要线索。
重点看什么?
-
异常栈信息:OOM的异常栈本身就很有价值,至少能告诉你OOM发生时代码在执行什么操作。
-
关键业务日志:OOM发生前后,有没有什么特殊的业务日志?
-
慢查询日志:看看是不是有SQL查了大量数据。
-
GC日志:结合时间点和业务日志对照着看。
5.4 本地复现与调试
如果能在本地复现问题,那定位起来就容易多了。
怎么复现?
-
构造测试数据:模拟线上的数据量和场景。
-
调小堆内存:把本地的堆内存设小一点,让问题更容易暴露。
-
压测:用JMeter、Gatling等工具压测,模拟高并发场景。
-
添加探针:在关键位置加日志,打印对象大小、集合大小等信息。
本地调试工具:
-
JProfiler/YourKit:可以实时监控内存,还能看对象分配的堆栈
-
VisualVM:JDK自带,免费够用
-
Arthas:阿里开源的Java诊断工具,线上也能用
5.5 Arthas在线诊断神器
重点推荐一下Arthas,这是阿里开源的Java在线诊断工具,堪称"线上调试神器"。
常用命令:
# 启动Arthas
java -jar arthas-boot.jar
# 查看仪表盘
dashboard
# 生成堆转储
heapdump /path/to/heapdump.hprof
# 查看方法调用情况
watch com.example.service.UserService getUser
# 追踪方法调用路径和耗时
trace com.example.service.UserService getUser
# 查看对象的属性
vmtool --action getInstances
# 反编译线上代码
jad com.example.service.UserService
Arthas的功能非常强大,强烈建议每个Java开发者都学一下,关键时刻能救命。
💡 经验之谈:很多时候dump分析告诉你"是什么",但没告诉你"为什么"。这时候就需要结合代码、日志、业务场景一起分析,甚至加日志重新发布来验证。这个过程可能需要反复几次,要有耐心。
六、步骤五:验证修复与预防措施
找到根因了,改完代码就完事了?当然不是。第五步,我们要验证修复是否有效,并且建立预防机制,避免下次再踩同样的坑。
6.1 修复方案验证
改完代码,不能直接就上线,得先验证一下修复是不是真的有效。
验证方法:
-
单元测试/集成测试:针对修复的点写测试用例,确保逻辑正确
-
压测验证:这是最重要的。用压测工具模拟线上流量甚至更高的流量,跑一段时间,观察内存使用情况。
-
对比GC日志:修复前后各跑一次压测,对比GC日志,看看老年代的使用趋势是不是变好了。
-
堆转储对比:压测结束后,各dump一次,对比对象数量和大小,确认泄漏的对象没了。
压测注意事项:
-
压测环境尽量和线上一致
-
压测时间要足够长,内存泄漏可能要跑很久才会显现
-
监控要跟上,实时观察内存、GC、CPU等指标
6.2 常见的修复策略
不同的OOM原因,修复策略也不同。这里总结几种常见的:
策略一:调整JVM参数
如果只是堆内存设置太小,业务本身没问题,那调大堆内存就行。
# 初始堆和最大堆都设为4G
-Xms4g -Xmx4g
# 元空间设为256M
-XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m
⚠️ 注意:调大堆内存只是"治标不治本"。如果是内存泄漏,调大堆只能延缓OOM的时间,不能根本解决问题。
策略二:优化代码
这是最根本的解决方式。根据根因,针对性地优化代码:
-
集合泄漏:加过期、加容量限制、用完及时移除
-
大对象:改成流式处理、分页处理
-
资源未关闭:用try-with-resources,确保关闭
-
ThreadLocal泄漏:用完remove
-
监听器泄漏:注销监听器
代码优化示例:
优化前(有泄漏):
public class CacheManager {
private static final Map<String, CacheObject> cache = new HashMap<>();
public void put(String key, Object data) {
cache.put(key, new CacheObject(data, System.currentTimeMillis()));
}
public Object get(String key) {
CacheObject obj = cache.get(key);
if (obj != null) {
return obj.getData();
}
return null;
}
}
优化后(加过期和容量限制):
public class CacheManager {
private static final int MAX_SIZE = 10000;
private static final long EXPIRE_TIME = 3600 * 1000;
private static final Map<String, CacheObject> cache = new LinkedHashMap<String, CacheObject>(16, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<String, CacheObject> eldest) {
return size() > MAX_SIZE;
}
};
public void put(String key, Object data) {
cache.put(key, new CacheObject(data, System.currentTimeMillis()));
}
public Object get(String key) {
CacheObject obj = cache.get(key);
if (obj == null) {
return null;
}
if (System.currentTimeMillis() - obj.getCreateTime() > EXPIRE_TIME) {
cache.remove(key);
return null;
}
return obj.getData();
}
}
或者更简单,直接用Guava Cache:
LoadingCache<String, Object> cache = CacheBuilder.newBuilder()
.maximumSize(10000)
.expireAfterWrite(1, TimeUnit.HOURS)
.build(new CacheLoader<String, Object>() {
@Override
public Object load(String key) throws Exception {
return loadFromDb(key);
}
});
策略三:使用软引用/弱引用
如果是缓存类的场景,可以考虑用软引用或弱引用,让内存不够时GC能自动回收。
// 软引用:内存不足时会被回收
SoftReference<byte[]> cache = new SoftReference<>(new byte[1024 * 1024]);
// 弱引用:只要GC就会被回收
WeakReference<Object> ref = new WeakReference<>(new Object());
不过要注意,软引用和弱引用不是银弹,使用不当反而会带来更多问题。
策略四:优化缓存策略
如果是缓存导致的OOM,重点优化缓存策略:
-
设置合理的过期时间
-
设置最大容量,超过就淘汰
-
选择合适的淘汰算法(LRU、LFU、FIFO等)
-
冷热数据分离
策略五:资源池化
对于连接、线程、对象等创建成本高的资源,使用池化技术。
-
数据库连接池:HikariCP、Druid
-
线程池:ThreadPoolExecutor
-
对象池:Apache Commons Pool
6.3 预防措施
“事后救火"不如"事前预防”。建立完善的预防机制,才能从根本上减少OOM的发生。
6.3.1 代码规范与Code Review
很多低级错误,通过Code Review都能发现。
-
制定代码规范,明确哪些写法是禁止的
-
严格执行Code Review,特别是核心模块
-
新人培训,普及常见的坑
6.3.2 静态代码检查
用工具自动扫描代码中的问题,比人工review更高效、更全面。
-
SonarQube:功能强大的代码质量平台
-
FindBugs/SpotBugs:专门找Java bug的工具
-
Alibaba Java Coding Guidelines:阿里Java规范插件
6.3.3 压测常态化
不要等上线了才发现性能问题。把压测纳入发布流程,每次上线前都跑一遍。
-
核心接口必须过压测
-
压测要覆盖各种场景
-
关注性能指标:QPS、响应时间、内存使用、GC情况
-
建立性能基线,每次发布对比
6.3.4 完善的监控告警
等OOM了才发现就太晚了。好的监控能在内存异常时就发出告警。
需要监控的关键指标:
-
堆内存使用率:超过80%就告警
-
非堆内存使用率:元空间、直接内存等
-
GC情况:Young GC频率、Full GC频率、GC耗时
-
线程数:线程总数、线程状态
-
类加载数:监控元空间泄漏
-
直接内存使用量:监控直接内存泄漏
6.3.5 定期堆转储分析
即使没有OOM,也可以定期dump一次堆内存,分析一下有没有泄漏的苗头。早发现早处理。
6.3.6 灰度发布
核心功能上线走灰度,先切一小部分流量,观察一段时间没问题再全量。
6.4 建立应急响应机制
就算预防做得再好,也不能保证100%不出问题。所以还要有完善的应急响应机制。
应急预案应该包括:
-
止损流程:怎么摘流、怎么降级、怎么扩容
-
排查流程:第一步做什么、第二步做什么、找谁协助
-
联系人:各个模块的负责人是谁
-
复盘机制:故障后要复盘,总结经验教训
💡 经验之谈:故障不可怕,可怕的是同样的故障反复发生。每次故障后认真复盘,把经验沉淀下来,团队的技术水平才能不断提高。
七、常见OOM场景实战案例
理论讲了这么多,不如来几个真实的案例更直观。下面分享几个我在工作中遇到过的真实OOM案例,每个案例都包含:现象、排查过程、根因、修复方案。
案例一:HashMap的key没重写hashCode和equals导致的泄漏
现象
线上一个服务,运行几天后内存缓慢上涨,最终OOM。dump分析发现有一个HashMap特别大,占了70%的内存,里面有几百万个Entry。但按业务逻辑,这个Map里最多应该只有几千条数据。
排查过程
-
看dump,发现HashMap的size是几百万,远超预期
-
看key的类型,是一个自定义的UserKey类
-
检查UserKey类,发现没有重写hashCode和equals方法
-
再看业务代码,发现每次请求都会new一个UserKey然后put到Map里
根因
HashMap的key如果没有重写hashCode和equals,就会用Object的默认实现——基于对象地址。这样即使两个UserKey的业务字段完全一样,它们的hashCode也不一样,equals也返回false。所以每次put都会当成新的key,Map就越来越大。
问题代码:
// 自定义key,没重写hashCode和equals
public class UserKey {
private Long userId;
private String tenantId;
public UserKey(Long userId, String tenantId) {
this.userId = userId;
this.tenantId = tenantId;
}
}
// 使用
Map<UserKey, UserInfo> cache = new HashMap<>();
cache.put(new UserKey(1L, "t1"), userInfo);
cache.put(new UserKey(1L, "t1"), userInfo); // 又存了一份!因为key不是同一个对象
修复方案
给UserKey重写hashCode和equals方法:
public class UserKey {
private Long userId;
private String tenantId;
public UserKey(Long userId, String tenantId) {
this.userId = userId;
this.tenantId = tenantId;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
UserKey userKey = (UserKey) o;
return Objects.equals(userId, userKey.userId) &&
Objects.equals(tenantId, userKey.tenantId);
}
@Override
public int hashCode() {
return Objects.hash(userId, tenantId);
}
}
经验教训
-
作为HashMap的key,一定要重写hashCode和equals
-
IDE自动生成就行,别偷懒手写,容易写错
-
用Lombok的@Data注解更省事
案例二:ThreadLocal导致的内存泄漏
现象
一个Web服务,使用Tomcat线程池。运行一段时间后元空间OOM,dump分析发现有很多ClassLoader的实例,每个ClassLoader加载了很多类。
排查过程
-
元空间OOM,说明类加载太多
-
dump分析,发现有大量的ClassLoader实例
-
顺着引用链找,发现这些ClassLoader被ThreadLocal持有
-
再看代码,发现有个工具类用ThreadLocal存了用户上下文,但用完没remove
根因
Tomcat的线程池中的线程是复用的。ThreadLocal用完如果不remove,线程下一次处理请求时,之前的值还在。更严重的是,如果ThreadLocal里存的对象引用了ClassLoader(比如动态代理类),那ClassLoader也无法被回收,导致元空间泄漏。
问题代码:
public class UserContext {
private static final ThreadLocal<UserInfo> userThreadLocal = new ThreadLocal<>();
public static void setUser(UserInfo user) {
userThreadLocal.set(user);
}
public static UserInfo getUser() {
return userThreadLocal.get();
}
// 没有remove方法!
}
// 使用
public void doFilter(ServletRequest request, ServletResponse response) {
UserInfo user = getUserFromRequest(request);
UserContext.setUser(user);
// 处理请求...
// 处理完就结束了,没remove
}
修复方案
添加remove方法,在请求结束时调用:
public class UserContext {
private static final ThreadLocal<UserInfo> userThreadLocal = new ThreadLocal<>();
public static void setUser(UserInfo user) {
userThreadLocal.set(user);
}
public static UserInfo getUser() {
return userThreadLocal.get();
}
public static void remove() {
userThreadLocal.remove();
}
}
// 使用
public void doFilter(ServletRequest request, ServletResponse response) {
try {
UserInfo user = getUserFromRequest(request);
UserContext.setUser(user);
// 处理请求...
} finally {
UserContext.remove(); // 一定要在finally里remove
}
}
经验教训
-
ThreadLocal用完一定要remove
-
最好在finally块中remove,确保一定会执行
-
使用线程池时尤其要注意,因为线程是复用的
案例三:大文件处理导致的堆溢出
现象
一个批量导入功能,用户上传Excel文件,系统解析处理。文件不大的时候没问题,文件大了(几十MB)就OOM。
排查过程
-
OOM发生在导入功能上
-
dump分析,发现byte[]数组特别多,占了大部分内存
-
看代码,发现用POI解析Excel时,是把整个文件读进内存再解析
根因
POI的UserModel模式(HSSFWorkbook/XSSFWorkbook)是把整个Excel文件加载到内存中处理的。文件大了,内存自然就爆了。
问题代码:
public void importExcel(MultipartFile file) throws IOException {
// 整个文件读进内存
Workbook workbook = new XSSFWorkbook(file.getInputStream());
Sheet sheet = workbook.getSheetAt(0);
// 逐行处理...
}
修复方案
使用POI的SAX模式(事件驱动),流式解析,不用把整个文件加载到内存:
public void importExcel(MultipartFile file) throws Exception {
OPCPackage pkg = OPCPackage.open(file.getInputStream());
XSSFReader reader = new XSSFReader(pkg);
SharedStringsTable sst = reader.getSharedStringsTable();
XMLReader parser = XMLReaderFactory.createXMLReader();
parser.setContentHandler(new SheetHandler(sst) {
@Override
public void processRow(List<String> row) {
// 逐行处理,处理完就丢弃
processRowData(row);
}
});
Iterator<InputStream> sheets = reader.getSheetsData();
while (sheets.hasNext()) {
try (InputStream sheet = sheets.next()) {
parser.parse(new InputSource(sheet));
}
}
pkg.close();
}
或者用EasyExcel,它底层也是SAX模式,但API更友好:
EasyExcel.read(file.getInputStream(), DataDTO.class, new DataListener())
.sheet()
.doRead();
经验教训
-
处理大文件一定要用流式处理,不要一次性加载到内存
-
不仅是Excel,大文本、大图片、大日志都一样
-
能用框架就用框架,别自己造轮子
案例四:数据库查询未分页导致OOM
现象
一个定时任务,每天凌晨跑一次,跑着跑着就OOM了。这个任务是同步数据,把A表的数据同步到B表。
排查过程
-
OOM发生在定时任务执行期间
-
dump分析,发现有大量的User对象,几百万个
-
看代码,发现同步任务是一次性把A表所有数据查出来,然后逐条处理
-
A表的数据量已经增长到几百万条了
根因
一次性查出几百万条数据,全部加载到内存,不OOM才怪。
问题代码:
public void syncData() {
// 一次性查出所有用户,几百万条!
List<User> users = userMapper.selectAll();
for (User user : users) {
// 处理...
}
}
修复方案
改成分页查询,每次只查一页:
public void syncData() {
int pageSize = 1000;
long lastId = 0;
while (true) {
// 按ID分页,每次查1000条
List<User> users = userMapper.selectByIdGreaterThan(lastId, pageSize);
if (users.isEmpty()) {
break;
}
for (User user : users) {
// 处理...
}
lastId = users.get(users.size() - 1).getId();
}
}
💡 小技巧:用"游标分页"(基于lastId)比"偏移量分页"(limit offset)效率高,特别是数据量大的时候。offset大了MySQL会慢。
经验教训
-
数据库查询一定要考虑数据量,不能想当然selectAll
-
数据量会增长,今天没问题不代表明天没问题
-
批量处理任务,优先考虑分页或流式处理
案例五:元空间溢出(动态类生成过多)
现象
一个使用了大量动态代理的服务,运行一段时间后报Metaspace OOM。
排查过程
-
错误信息是Metaspace溢出
-
jstat看元空间使用率,确实一直在涨
-
dump分析,发现有大量的动态生成的类,类名类似
$Proxy123、CGLIB$$EnhancerByCGLIB$$... -
看代码,发现每次调用某个方法都会动态生成一个代理类
根因
动态代理(JDK动态代理、CGLIB等)会在运行时生成新的类。如果每次调用都生成新的代理类,而不是复用,那类就会越来越多,最终撑爆元空间。
问题代码:
public Object getProxy(Object target) {
// 每次调用都创建新的Enhancer,生成新的代理类
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(target.getClass());
enhancer.setCallback(new MyMethodInterceptor());
return enhancer.create();
}
修复方案
缓存代理类,同一个Class只生成一次代理:
private static final ConcurrentHashMap<Class<?>, Class<?>> proxyCache = new ConcurrentHashMap<>();
public Object getProxy(Object target) {
Class<?> targetClass = target.getClass();
Class<?> proxyClass = proxyCache.get(targetClass);
if (proxyClass == null) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(targetClass);
enhancer.setCallback(new MyMethodInterceptor());
proxyClass = enhancer.createClass();
proxyCache.put(targetClass, proxyClass);
}
try {
return proxyClass.newInstance();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
或者直接用Spring的AOP,它已经帮你处理好了这些问题。
经验教训
-
动态生成类的框架(CGLIB、Javassist等)要注意类的复用
-
元空间OOM优先排查类加载相关的问题
-
可以加-XX:+TraceClassLoading参数观察类加载情况
案例六:直接内存溢出(Netty)
现象
一个基于Netty的网关服务,运行一段时间后报Direct buffer memory OOM。堆内存使用率其实不高。
排查过程
-
错误信息是Direct buffer memory
-
堆内存使用率不高,说明不是堆的问题
-
检查直接内存配置,发现没设置,默认是堆内存大小
-
dump分析,发现DirectByteBuffer对象不多,但每个都很大
-
看Netty的配置,发现接收缓冲区设得太大,而且没有上限
根因
Netty使用直接内存来做缓冲区。如果配置不当,比如缓冲区太大、没有限制,或者有泄漏,就会导致直接内存溢出。
问题代码:
public class NettyServer {
public void start() {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_RCVBUF, 1024 * 1024 * 10) // 接收缓冲区10M!
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) {
// ...
}
});
}
}
修复方案
1. 调整缓冲区大小到合理值
2. 设置直接内存上限
-XX:MaxDirectMemorySize=512m
3. 检查有没有ByteBuf泄漏(Netty的ByteBuf需要手动release)
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf buf = (ByteBuf) msg;
try {
// 处理buf
} finally {
buf.release(); // 一定要释放
}
}
或者用SimpleChannelInboundHandler,它会自动释放:
public class MyHandler extends SimpleChannelInboundHandler<ByteBuf> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, ByteBuf msg) {
// 处理完自动释放
}
}
经验教训
-
直接内存OOM,重点排查NIO、Netty、Mina等框架
-
Netty的ByteBuf要注意释放,不然会泄漏
-
建议设置-XX:MaxDirectMemorySize限制直接内存大小
-
可以用-Dio.netty.leakDetection.level=advanced开启泄漏检测
八、总结与最佳实践
文章到这里也差不多了,最后我们来总结一下,把这套方法论沉淀下来。
8.1 5步排查法回顾
再回顾一下我们的OOM排查5步法: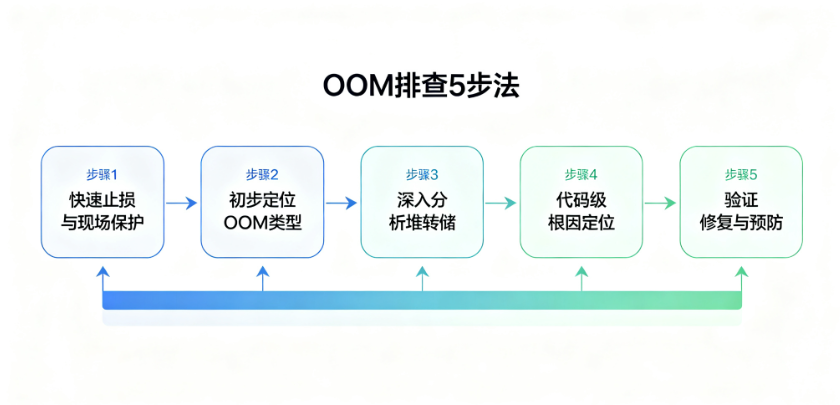
-
步骤一:快速止损与现场保护
-
先止损:摘流、降级、限流、扩容
-
保现场:生成堆转储、收集日志和配置
-
关键原则:不要上来就重启
-
-
步骤二:初步定位OOM类型
-
看错误信息判断类型
-
分析GC日志看趋势
-
jstat实时监控
-
-
步骤三:深入分析堆转储文件
-
用MAT等工具分析dump
-
看泄漏嫌疑报告、直方图、支配树
-
找GC Roots引用链
-
常见泄漏模式对号入座
-
-
步骤四:代码级根因定位
-
结合业务场景缩小范围
-
代码审查高危点
-
日志追踪
-
本地复现与调试
-
Arthas在线诊断
-
-
步骤五:验证修复与预防措施
-
压测验证修复效果
-
针对性修复代码
-
建立预防机制
-
完善应急响应
-
8.2 排查思路总结
除了具体的步骤,更重要的是排查的思路。我总结了几条经验:
思路一:先宏观,后微观
不要上来就扎进代码里。先从整体上判断:是哪种OOM?是哪个区域的问题?大概是什么原因?有了方向再深入。不然就像大海捞针,效率很低。
思路二:先假设,后验证
根据现象先提出假设,然后想办法验证。比如"我怀疑是缓存泄漏",那就去查缓存的大小、过期策略、命中率,用数据说话。不要凭感觉。
思路三:善用工具,不要硬扛
Java生态这么成熟,有很多好用的工具。MAT、Arthas、VisualVM、JProfiler……熟练掌握几个工具,能让你的排查效率提升好几倍。
思路四:数据驱动,不要猜
所有的判断都要有数据支撑。dump数据、GC日志、监控数据、业务日志……用数据说话,不要拍脑袋。
思路五:耐心,耐心,还是耐心
复杂的OOM问题可能需要排查好几个小时甚至好几天。不要急躁,一步一步来,总能找到根因的。
8.3 最佳实践清单
最后,给大家一份OOM预防最佳实践清单,可以对照着检查一下自己的项目:
-
JVM配置了-XX:+HeapDumpOnOutOfMemoryError,OOM时自动dump
-
JVM配置了GC日志输出,方便事后分析
-
核心服务有完善的监控告警(内存、GC、线程等)
-
有一键摘流、一键降级、一键扩容的止损能力
-
代码规范中有内存相关的要求
-
Code Review会关注内存风险点
-
使用了静态代码检查工具
-
核心接口上线前经过压测
-
大文件、大数据量处理使用流式/分页方式
-
ThreadLocal用完都会remove
-
资源(流、连接等)使用try-with-resources确保关闭
-
缓存有过期时间和容量限制
-
集合类不会无限增长
-
线程池有合理的配置,不会无限创建线程
-
有定期的性能巡检和堆转储分析
-
有完善的故障应急预案
-
故障后会复盘,沉淀经验
8.4 写在最后
OOM虽然可怕,但只要掌握了正确的方法论,其实也没那么难搞。关键是要形成一套系统化的排查流程,而不是靠运气瞎碰。
希望这篇文章能帮到你。下次再遇到线上OOM,别慌,按照这5步来,10分钟定位根因不是梦。
当然,纸上得来终觉浅,绝知此事要躬行。方法说得再多,不如自己亲手排查几次印象深刻。建议大家在平时的工作中多练手,把这些工具和方法用熟,关键时刻才能得心应手。
如果你有什么OOM排查的经验或者踩过的坑,欢迎在评论区分享,大家一起交流进步。
最后,祝大家的服务永不OOM,永远稳定运行!
推荐阅读:如果你想深入学习JVM和性能调优,推荐阅读《深入理解Java虚拟机》(周志明著)、《Java性能权威指南》、《实战Java虚拟机》等书籍。同时,Oracle官方的JVM文档也是非常好的学习资料。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


