
卷积
卷积就是对矩阵(图像)应用的滑动窗口函数。

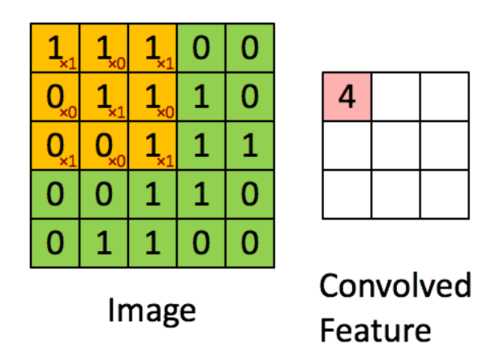
图中绿色为一个二值图像,每个值代表一个像素(0是黑,1是白)。(更典型的是像素值为0-255的灰阶图像)
图中黄色的滑动窗口叫卷积核、过滤器或者特征检测器,也是一个矩阵。
我们将这个大小是3x3的过滤器中的每个元素(红色小字)与图像中对应位置的值相乘,然后对它们求和,得到右边粉红色特征图矩阵的第一个元素值。
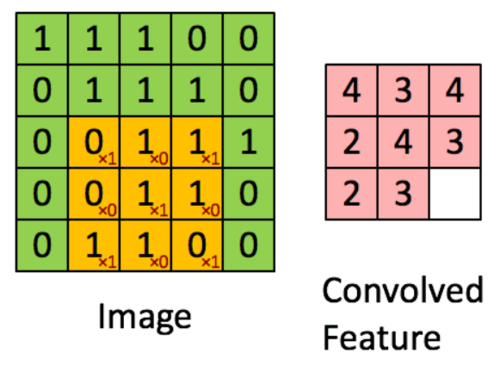
我们在整个图像矩阵上滑动这个过滤器来得到完整的卷积特征图:
Convolution_schematic.gif
直觉理解
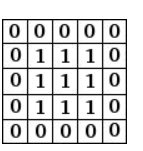
对每个像素点,与它的周边像素一起平均得到模糊效果。
模糊效果的卷积核
(1就相当于权重,新像素点包含对应像素点与其周边像素点的综合信息,“人人有份”)应用该卷积核模糊后的图像
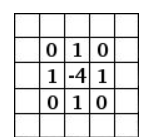
取一个像素与它周边像素的差值来检测边缘
检测边缘的卷积核
(如果图像某区域是平滑的,那么中心点像素值应该与四周的像素都差不多相等,卷积后得到的就是0,即黑色。如果这里有锐边、颜色的突变,就会得到一个很大的差异和卷积后相应的非零值,对应下图的白色)应用该卷积核检测边缘后的图像


卷积的其它资料
补零
如何对图片矩阵的第一个元素(它在顶部和左边并没有相邻的元素)应用过滤器?
我们可以采用零填充,在对第一个元素应用过滤器时落在矩阵之外的所有元素都取为零。
这样就可以获得更大或者相同大小的输出了。输出尺寸的大小计算公式为:
*```
n_{out} = n_{in}+2n_{padding}-n_{filter}+1
以第一张图为例,它的输入尺寸为5x5,没有补零,过滤器尺寸为3x3,输出尺寸就是(5-3+1)x(5-3+1)即3x3的尺寸。### 池化层- 英文名pooling (subsampling) layer - 典型的,**池化层**通常在**卷积层**之后应用。 - 最常见的方式是对过滤器的结果取最大值。 如下是一个2x2的最大池化窗口,取出4个中最大的。 - 池化有**一般池化**(非重叠池化)、**重叠池化**、**空金字塔池化**,上图为一般池化。 - 池化可以减少输出维数,同时一定程度上保持了最突出的信息。 - 池化可以提供基本的平移、旋转不变性。最大化操作会提取出相同的值而不管你是否有一定程度内的平移或旋转。 - 池化可以提供一个固定大小的输出矩阵。如果你有1000个过滤器,然后你对每一个的结果应用最大池化,不论你过滤器的尺寸和输入的尺寸是多少,你会得到1000维的输出。这意味着我们可以使用可变大小的输入和可变大小的过滤器,并且总可以得到相同尺寸的输出,来馈入分类器。 > 其它参考 1. [池化方法总结(Pooling)](http://blog.csdn.net/danieljianfeng/article/details/42433475) 2. [斯坦福教程wiki池化](http://ufldl.stanford.edu/wiki/index.php/%E6%B1%A0%E5%8C%96#.E6.B1.A0.E5.8C.96.E7.9A.84.E4.B8.8D.E5.8F.98.E6.80.A7)### 过滤器的值- 在训练阶段,一个卷积神经网络会基于你要执行的任务,自动学习它的过滤器的值,实现相应的变换。 - 比如说,一个处理图像分类任务的卷积神经网络会学习到在第一层从原始像素中检测边缘,然后在第二层使用这些边缘来检测出简单的形状,之后在更高的层次使用这些形状来发现更高级别的特征,比如脸部特征。最后一层则是一个使用这些高级特征的分类器。 ### 多通道- 很多时候,我们输入的是多通道图像。如RGB三通道图像,下图就是。也有可能我们出于特定目的,将几张图组成一组一次性输入处理。 - 对于这种情况,这时一个过滤器或卷积核其实对应的是x个卷积核(对应x通道)和一个偏置量,如下图中的`W0`和`W1`。一个通道中的某个区域(蓝框)和它对应的卷积核(红框)做卷积,多个通道的卷积结果线性相加,再加上偏置量(最下的单个红框),得到卷积结果(最右列中心的绿色框)。下图的卷积层包含2个多通道卷积核`W0`和`W1`,所以结果为2个绿色矩阵。而该卷积层的输出对于下一卷积层一定程度上也就可以说是2通道,处理方式也是类似。 > 参考: [cs231 Convolutional Neural Networks](http://cs231n.github.io/convolutional-networks/)### 常用激活函数[ReLU](https://www.wikiwand.com/en/Rectifier_(neural_networks)) —— `f(x) = max(0, x) | -oo<x<+oo`[Tanh](https://reference.wolfram.com/language/ref/Tanh.html) —— 双曲正切### 优秀链接- [技术向:一文读懂卷积神经网络CNN](http://dataunion.org/11692.html)- [斯坦福UFLDL教程](http://ufldl.stanford.edu/wiki/index.php/UFLDL%E6%95%99%E7%A8%8B)
作者:treelake
链接:https://www.jianshu.com/p/606a33ba04ff
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦