
说明
最近忙着找工作,想了解一下用人单位的招聘要求,以爬取boss直聘的招聘信息作为参考。这里记录一下的爬取流程,并不作为其它用途!
分析页面结构
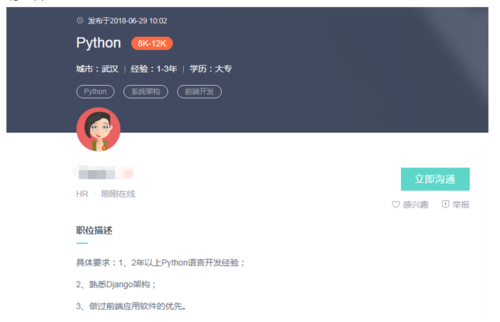
通过分析页面,发现招聘的详细信息都在详情页(如下图),故通过详情页来提取招聘内容

设计爬虫策略
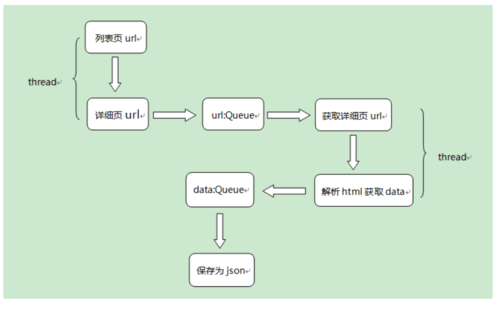
通过列表页获取详细页的url地址,然后存入到url队列中,发现列表页有10页,这里使用多线程提高爬取效率;
通过url队列中的详情页url地址得到详情页的html内容,采用xpath解析,提取招聘信息,以字典形式存入data队列中,这里也采用多线程;
将data队列中的数据保存为json文件,这里每保存的一个json文件都是一个列表页所有的招聘信息。
页面请求方式的判断

不难发现,这里是通过get请求并添加查询字符串获取指定页面的;
查询字符串参数的含义:query=python表示搜索的职位,page=1表示列表页的页码,ka=page-1这个没用到可以忽略掉;
对应的代码如下:
# 正则表达式:去掉标签中的<br/> 和 <em></em>标签,便于使用xpath解析提取文本regx_obj = re.compile(r'<br/>|<(em).*?>.*?</\1>')def send_request(url_path, headers, param=None):
"""
:brief 发送请求,获取html响应(这里是get请求)
:param url_path: url地址
:param headers: 请求头参数
:param param: 查询参数, 如:param = {'query': 'python', 'page': 1}
:return: 返回响应内容
"""
response = requests.get(url=url_path, params=param, headers=headers)
response = regx_obj.sub('', response.text) return response通过列表页获取详情页url
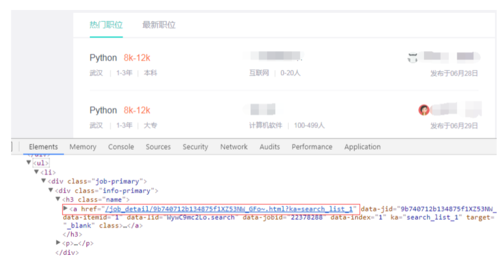
这里通过xpath语法@href获取a标签href属性值,拿到详细页url地址,代码如下:
def detail_url(param):
"""
:brief 获取详情页的url地址
:param param: get请求的查询参数
:return: None
"""
wuhan_url = '/'.join([base_url, "c101200100/h_101200100/"])
html = send_request(wuhan_url, headers, param=param) # 列表页页面
html_obj = etree.HTML(html) # 提取详情页url地址
nodes = html_obj.xpath(".//div[@class='info-primary']//a/@href") for node in nodes:
detail_url = '/'.join([base_url, node]) # 拼接成完整的url地址
print(detail_url)
url_queue.put(detail_url) # 添加到队列中解析详情页的数据
通过xpath解析数据,然后将数据存储为字典放到队列中,代码如下:
def parse_data():
"""
:brief 从html文本中提取指定信息
:return: None
"""
# # 解析为HTML文档
try: while True: # 等待25s,超时则抛出异常
detail_url = url_queue.get(timeout=25)
html = send_request(detail_url, headers, param=None)
html_obj = etree.HTML(html)
item = {} # 发布日期
item['publishTime'] = html_obj.xpath(".//div[@class='info-primary']//span[@class='time']/text()")[0] # 职位名
item['position'] = html_obj.xpath(".//div[@class='info-primary']//h1/text()")[0] # 发布者姓名
item['publisherName'] = html_obj.xpath("//div[@class='job-detail']//h2/text()")[0] # 发布者职位
item['publisherPosition'] = html_obj.xpath("//div[@class='detail-op']//p/text()")[0] # 薪水
item['salary'] = html_obj.xpath(".//div[@class='info-primary']//span[@class='badge']/text()")[0] # 公司名称
item['companyName'] = html_obj.xpath("//div[@class='info-company']//h3/a/text()")[0] # 公司类型
item['companyType'] = html_obj.xpath("//div[@class='info-company']//p//a/text()")[0] # 公司规模
item['companySize'] = html_obj.xpath("//div[@class='info-company']//p/text()")[0] # 工作职责
item['responsibility'] = html_obj.xpath("//div[@class='job-sec']//div[@class='text']/text()")[0].strip() # 招聘要求
item['requirement'] = html_obj.xpath("//div[@class='job-banner']//div[@class='info-primary']//p/text()")[0]
print(item)
jobs_queue.put(item) # 添加到队列中
time.sleep(15) except: pass保存数据为json文件
代码如下:
def write_data(page):
"""
:brief 将数据保存为json文件
:param page: 页面数
:return: None
"""
with open('D:/wuhan_python_job_{}.json'.format(page), 'w', encoding='utf-8') as f:
f.write('[') try: while True:
job_dict = jobs_queue.get(timeout=25)
job_json = json.dumps(job_dict, indent=4, ensure_ascii=False)
f.write(job_json + ',') except: pass
f.seek(0, 2)
position = f.tell()
f.seek(position - 1, 0) # 剔除最后一个逗号
f.write(']')json数据示例
{ "salary": "4K-6K", "publisherName": "曾丽香", "requirement": "城市:武汉经验:应届生学历:本科", "responsibility": "1、2018届统招本科毕业,计算机相关专业;2、熟悉python开发;3、良好的沟通表达能力,学习能力强,积极上进;", "publishTime": "发布于2018-06-11 12:15", "companyName": "云智汇科技", "position": "软件开发(python、0年经验)", "publisherPosition": "HR主管刚刚在线", "companySize": "未融资500-999人", "companyType": "计算机软件"}其它
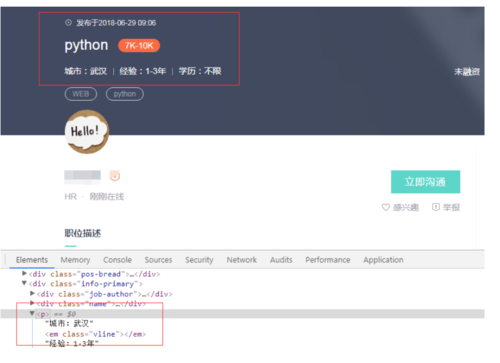
div中存在<br/>标签,xpath无法获取div标签中所有的文本内容(如下图):
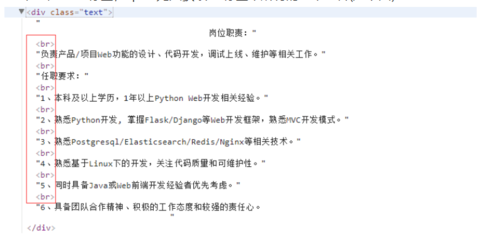
解决办法:拿到html文本后,提前通过正则表达式剔除该标签
核心代码如下:
# 正则表达式:去掉标签中的<br/> 和 <em></em>标签,便于使用xpath解析提取文本regx_obj = re.compile(r'<br/>|<(em).*?>.*?</\1>')
response = requests.get(url=url_path, params=param, headers=headers)
response = regx_obj.sub('', response.text)2.当爬取速度过快时,会被封ip,这里将多线程改为单线程版,并使用time.sleep降低爬取速度
3.程序github地址:https://github.com/White2017/python-spider/blob/develop/boss_wuhan_spider.py
喜欢点个赞!!!
作者:white_study
链接:https://www.jianshu.com/p/d293fe5ba56f
共同学习,写下你的评论
评论加载中...
作者其他优质文章



