
什么是数据标准化(归一化)
数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。为了消除指标之间的量纲影响,保证结果的可靠性,需要进行数据标准化处理,以解决数据指标之间的可比性。
为什么要数据归一化:
1)归一化后加快了梯度下降求最优解的速度;
当存在多个特征时,如果特征数据范围不一致,可能会导致梯度下降的路径摇摆不定,效率低下。
如下图所示,蓝色的圈圈图代表的是两个特征的等高线。其中左图两个特征X1和X2的区间相差非常大,X1区间是[0,2000],X2区间是[1,5],其所形成的等高线非常尖。当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;
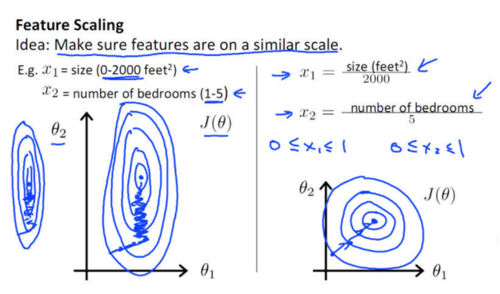
image
而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
2)归一化有可能提高精度。
一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
常见的数据归一化方法
1) 线性归一化
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:
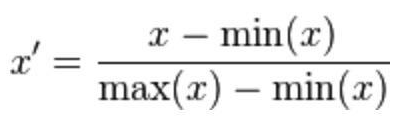
image
其中max为样本数据的最大值,min为样本数据的最小值。
这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
python代码:
def Normalization(x): return [(float(i)-min(x))/float(max(x)-min(x)) for i in x] # 或者调用sklearn包的方法from sklearn import preprocessing import numpy as np X = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]) min_max_scaler = preprocessing.MinMaxScaler() X_minMax = min_max_scaler.fit_transform(X)
1*) 如果想要将数据映射到[-1,1],则将公式换成:
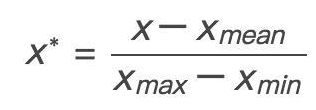
image
x_mean表示数据的均值。
python代码:
def Normalization2(x): return [(float(i)-np.mean(x))/(max(x)-min(x)) for i in x]
2) 标准差标准化
也称为z-score标准化。这种方法根据原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
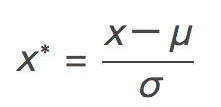
image
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,Z-score标准化表现更好。
python代码:
from sklearn import preprocessing import numpy as np X = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]) # calculate mean X_mean = X.mean(axis=0) # calculate variance X_std = X.std(axis=0) # standardize X X1 = (X-X_mean)/X_std # 自己计算# use function preprocessing.scale to standardize X X_scale = preprocessing.scale(X) # 调用sklearn包的方法# 最终X1与X_scale等价
3) 非线性归一化
经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数,正切等。需要根据数据分布的情况,决定非线性函数的曲线,比如log(V, 2)还是log(V, 10)等。
3.1 对数转换
y=log10(x) /log10(max)
3.2 反余切函数转换
y=atan(x)*2/PI
作者:繁著
链接:https://www.jianshu.com/p/0d8bb02f98fb
共同学习,写下你的评论
评论加载中...
作者其他优质文章



