
一 了解Stream
Stream API(java.util.stream.*) Stream 是JAVA8中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API对集合数据进行操作,就类似于使用SQL执行数据查询一样。也可使用StreamAPI做并行操作,总之,StreamAPI提供了一种高效且易于使用的处理数据的方式。
Stream是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。集合讲的是数据,流讲的是计算。
注意:
1 . Stream自己不会存储元素。
2 . Stream不会改变源对象。相反,他们会返回一个持有结果的新Stream
3 . Stream操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
二 并行流与串行流
并行流就是把一个内容分成多个数据块,并用不同的线程分成多个数据块,并用不同的线程分别处理每个数据块的流。
JAVA8 中将并行进行了优化,我们可以很容易的对数据进行并行操作。Stream API 可以声明性地通过parallel() 与sequential() 在并行流与顺序流之间进行切换。其实JAVA8底层是使用JAVA7新加入的Fork/Join框架:
Fork/Join框架与传统线程池的区别:
采用“工作窃取”模式(work-stealing):当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上.在一般的线程池中,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态.而在fork/join框架实现中,如果某个子问题由于等待另外一个子问题的完成而无法继续运行.那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行.这种方式减少了线程的等待时间,提高了性能.
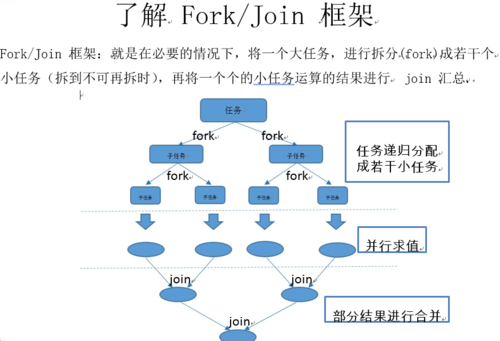
三 并行流与其他方式对比
下面就以一个求 0到一亿、十亿、五百亿 的和来比较执行的效率:
1) 使用For循环求和
@Test
public void testFor() {
Instant start = Instant.now();
long sum = 0;
for (long i = 0; i <= 50000000000L; i++) {
sum += i;
}
System.out.println(sum);
Instant end = Instant.now();
System.out.println("五百亿求和花费的时间为: " + Duration.between(start, end).toMillis());
}运行结果: 5000000050000000 一亿求和花费的时间为: 91 500000000500000000 十亿求和花费的时间为: 868 -4378596987249509888 五百亿求和花费的时间为: 33910
2) 使用Fork/Join框架求和
package com.lxj.java8;
import java.time.Duration;
import java.time.Instant;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
public class ForkJoinSum extends RecursiveTask<Long>{
private static final long serialVersionUID = 6011408981548802596L;
private long start;
private long end;
//临界值
private final long THRESHHOLD = 10000L;
public ForkJoinSum() {
}
public ForkJoinSum(long start, long end) {
super();
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
if(end - start <= THRESHHOLD) {
long sum = 0L;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
}else {
long mid = (start + end)/2;
ForkJoinSum left = new ForkJoinSum(start,mid);
left.fork(); //分支
ForkJoinSum right = new ForkJoinSum(mid+1,end);
right.fork(); //分支
return left.join() + right.join(); //合并
}
}
public static void main(String[] args) {
Instant start = Instant.now(); //100000000L 1000000000L 50000000000L
ForkJoinTask<Long> forkJoinTask = new ForkJoinSum(0L,50000000000L);
ForkJoinPool forkJoinPool = new ForkJoinPool();
Long t = forkJoinPool.invoke(forkJoinTask);
System.out.println(t);
Instant end = Instant.now();
System.out.println("十亿求和耗费的时间为: " + Duration.between(start, end).toMillis());
}
}输出结果: 5000000050000000 一亿求和耗费的时间为: 106 500000000500000000 十亿求和耗费的时间为: 508 -4378596987249509888 五百亿求和耗费的时间为: 20256
3) 使用自己写的递归求和(绝对是个人为了好玩才测的,就怕栈被数据撑爆了,要是C语言的话估计早递归爆内存了)
package com.lxj.java8;
import java.time.Duration;
import java.time.Instant;
public class Recursion {
private long start;
private long end;
private final long THRESHHOLD = 10000L;
public Recursion(long start, long end) {
super();
this.start = start;
this.end = end;
}
public Long getValue() {
long t = (start + end)/2;
if(end - start <= THRESHHOLD) {
long sum = 0L;
for(long i = start ; i <= end ; i++) {
sum += i;
}
return sum;
}else {
Recursion left = new Recursion(start, t);
Recursion right = new Recursion(t+1, end);
return left.getValue() + right.getValue();
}
}
//100000000L 1000000000L 50000000000L
/*
5000000050000000
一亿求和耗费的时间为: 182
500000000500000000
十亿求和耗费的时间为: 979
-4378596987249509888
五百亿求和耗费的时间为: 114102
*/
public static void main(String[] args) {
Instant start = Instant.now();
Recursion binaryValue = new Recursion(0L, 50000000000L);
Long value = binaryValue.getValue();
System.out.println(value);
Instant end = Instant.now();
System.out.println("五百亿求和耗费的时间为: "+Duration.between(start, end).toMillis());
}
}运行结果: 5000000050000000 一亿求和耗费的时间为: 182 500000000500000000 十亿求和耗费的时间为: 979 -4378596987249509888 五百亿求和耗费的时间为: 114102
4) 使用StreamAPI
@Test
public void testStream() {
Instant start = Instant.now();
//使用StreamAPI
OptionalLong result = LongStream.rangeClosed(0L, 50000000000L)
.parallel()
.reduce(Long::sum);
System.out.println(result.getAsLong());
Instant end = Instant.now();
System.out.println("五百亿求和耗费的时间为: " + Duration.between(start, end).toMillis());
}运行结果: 5000000050000000 一亿求和耗费的时间为: 112 500000000500000000 十亿求和耗费的时间为: 854 -4378596987249509888 五百亿求和耗费的时间为: 20250
通过对比,Stream和Fork/Join框架在大数据的时候速度还是挺快的,For循环在数据小的时候是最快的。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


