
并发系列是一个很庞大的知识体系,要想完全弄明白是挺困难的,因为最近打算阅读Tornado源码, 其介绍谈到了内部使用了异步非阻塞的调用方式。之前也没有深入了解,这次就借此好好整理一下。
线程(threading模块)
线程是应用程序运行的最小单元,在同一个进程中,可以并发开启多个线程,每个线程拥有自己的堆栈,同时相互之间是共享资源的。
Python中使用threading模块来开启多线程

import threading, timedef func(n): time.sleep(2) print(time.time(),n)
if __name__ == '__main__': for i in range(10): t = threading.Thread(target=func, args=(1,)) t.start() print('主线程结束')
'结果' 主线程结束1532921321.058243 1 1532921321.058243 1 1532921321.058243 1 1532921321.058243 1...
或者通过自定义类继承Thread,并且重写run方法
import threading,timeclass Mythread(threading.Thread): def __init__(self,name):
super().__init__()
self.name = name def run(self):
time.sleep(1) print('hello %s'%self.name)if __name__ == '__main__': for i in range(5):
m = Mythread('py')
m.start() print('---主线程结束---')
执行顺序如下
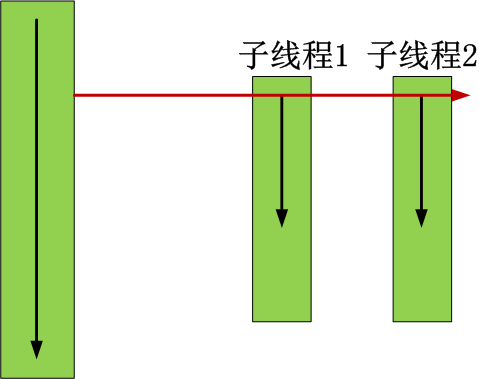
主线程和子线程之间是相互独立的,但是主线程运行完毕会等待子线程的运行,直到完毕,才回收资源。
Thread对象可调用的方法
hread实例对象的方法 # isAlive(): 返回线程是否活动的。 # getName(): 返回线程名。 # setName(): 设置线程名。 #join():使主线程阻塞,直到该线程结束 threading模块提供的一些方法: # threading.currentThread(): 返回当前的线程变量。 # threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 # threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
守护线程(setDaemon)
如果一个线程设置为守护线程,那么它将会和主线程一起结束,而主线程会等待所有的非守护线程的子线程结束而退出。因此可以认为,守护线程是“不重要的线程”,主线程不等它。
import threading, time"""设置两个线程"""def func1(): print('--非守护线程开始--')
time.sleep(2) print('--非守护线程结束--')def func2(): print('--守护线程开始--')
time.sleep(4) print('--守护线程结束--')if __name__ == '__main__':
t1 = threading.Thread(target=func1,args=())
t2 = threading.Thread(target=func2,args=())
t2.setDaemon(True)
t1.start()
t2.start() '''
--非守护线程开始--
--守护线程开始--
--非守护线程结束--
守护线程还没运行完,主线程就结束了 '''
而线程之间共享数据,必然会导致同时操作数据时的混乱,影响数据安全
import threading,timedef func(): #开始处理数据 global n a=n+1 time.sleep(0.0001) n =a # 结束处理if __name__ == '__main__': n=0 li =[] for i in range(1000): t=threading.Thread(target=func,args=()) li.append(t) t.start() for i in li: i.join() #等待子线程全部执行完 print(n) #253 ''' 我们希望能从0加到1000,但是由于有多个线程会拿到数据, 如果处理速度慢,就会使数据混乱 '''
因此,对数据进行加锁就很有必要了。
互斥锁(Lock)
通过获取锁对象,访问共有数据,最后释放锁来完成一次操作,一旦某个线程获取了锁,当这个线程被切换时,下个个进程无法获取该公有数据
import threading,timedef func(): #开始处理数据 global n lock.acquire() #获取 a=n+1 time.sleep(0.00001) n =a lock.release() #释放 # 结束处理if __name__ == '__main__': n=0 lock=threading.Lock() li =[] for i in range(1000): t=threading.Thread(target=func,args=()) li.append(t) t.start() for i in li: i.join() #等待子线程全部执行完 print(n) #1000
通过同步的互斥锁来保证数据安全相比于线程串行运行而言,如每个线程start之前都使用.join()方法,无疑速度更快,因为它就只有在访问数据的时候是串级的,其他的情况下是是并发的(虽然也不能是并行运行,因为GIL,之后会谈到)。
再看如下情况
死锁
import threadingif __name__ == '__main__': lock=threading.Lock() lock.acquire() lock.acquire() #程序卡住,只能获取一次 lock.release() lock.release()
递归锁(RLock)
RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使
用RLock代替Lock,则不会发生死锁:
import threadingif __name__ == '__main__': lock=threading.RLock() lock.acquire() lock.acquire() #可以多次获取,程序顺利执行 lock.release() lock.release()
信号量(Semaphore)
能够并发执行的线程数,超出的线程阻塞,直到有线程运行完成。
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
import threading,timedef sever_help(n):
s.acquire() print('%s欢迎用户%d'%(threading.current_thread().getName(),n))
time.sleep(2)
s.release()if __name__ == '__main__':
s = threading.Semaphore(5)
li = [] for i in range(32):
t = threading.Thread(target=sever_help,args=(i,))
li.append(t)
t.start() for i in li:
i.join() print("===结束==")
通过对比互斥锁可以看出,互斥锁就是Semaphore(1)的情况,也完全可以使用后者,但是如果数据必须单独使用,那么用互斥锁效率更高。
事件(Event)
如果某一个线程执行,需要判断另一个线程的状态,就可以使用Event,如:用Event类初始化一个event对象,线程a执行到某一步,设置event.wait(),即线程a阻塞,直到另一个线程设置event.set(),将event
状态设置为True(默认是False)。


import threadingimport time, randomdef eating():
event.wait() print('去吃饭的路上...')def makeing(): print('做饭中')
time.sleep(random.randint(1,2)) print('做好了,快来...')
event.set()if __name__ == '__main__':
event=threading.Event()
t1 = threading.Thread(target=eating)
t2 = threading.Thread(target=makeing)
t1.start()
t2.start()
# 做饭中
# 做好了,快来...
# 去吃饭的路上...饭做好了我才去吃
基本方法:
event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
线程队列(queue)
特点:先进先出,
作用:多个线程之间进行通信(作用不大,多进程的队列用处大)
常用方法:
.get() 获取 无数据时会阻塞
.set('item') 设置,先设置的数据,先取出
.empty() 是否为空
基本使用:生成者消费者模型
import threading, queuedef eating(n): #消费
i = q.get() print('消费者%d吃了第%d份食物' % (n, i))def making(): #生产
for i in range(1, 11): print('正在制作第%d份食物' % i)
time.sleep(1)
q.put(i)if __name__ == '__main__':
q = queue.Queue()
t2 = threading.Thread(target=makeing)
t2.start() for i in range(1, 11):
t = threading.Thread(target=eating, args=(i,))
t.start()
生产者,消费者
原文出处:https://www.cnblogs.com/ifyoushuai/p/9387984.html
共同学习,写下你的评论
评论加载中...
作者其他优质文章



