
前几年,腾讯新闻曾发出一片具有爆炸性的文章。并不是文章的内容有什么新奇之处,而是文章的作者与众不同,写文章的不是人,而是网络机器人,或者说是人工智能,是算法通过分析大量财经文章后,学会了人如何编写财经报道,然后根据相关模式,把各种财经数据组织起来,自动化的生成一篇文章,当人阅读时,根本无法意识到文章不是人写,而是电脑生成的。
从本节开始,如何使用神经网络构造出一个能阅读,理解人类文本含义的智能程序。就如同前一章讲述的图像识别网络,本质上并不是网络能像人一样看懂了图片内涵,而是网络通过读取大量图片数据,从数据中抽取出某种固定规律,我们本章要开发的神经网络也同理,它会从大量的文本数据中分析抽取出其潜在的固定模式或规律。
要想让网络能够分析文本,我们首先要做的是将文本进行数据化。它主要包含几个方面的内容:一种方法是将文本分割成词组,并将词组转变为向量。一种方法是将文本分割成一系列字符的组合,然后用向量表示每个字符。第三种方法是把若干个词或字符组合成一个集合,然后将他们转换成向量。无论何种情况,我们都把被向量化的对象成为token,而把整篇文章分解成token的过程叫tokenization。
举个具体例子,假设我们有一条英文句子"The cat jump over the dog",如果我们采用第一种方法,那么我们把句子分解成多个单词:'The','cat','jump','over','the','dog'。然后通过算法为每个单词构造一个向量:
'the'->[0.0, 0.0, 0.4,0.0,1.0,0.0]
'cat'->[0.5, 1.0, 0.5, 0.2, 0.5, 0.5, 0.0]等,后面我们会研究单词是如何转换成向量的。
有一种把单词向量化的简单方法叫one-hot-encoding,我们在前面章节看过这种向量,它所有元素都是0,只有某个位置是1,例如上面例句中总共有5个不同单词,于是我们可以用含有5个元素的向量来表示:
'The' -> [1,0,0,0,0], 'cat'->[0,1,0,0,0], 'jump'->[0,0,1,0,0]以此类推。
我们看一段如何将单词进行one-hot-encoding的代码:
import numpy as np
samples = ['The cat jump over the dog', 'The dog ate my homework']#我们先将每个单词放置到一个哈希表中token_index = {}for sample in samples: #将一个句子分解成多个单词
for word in sample.split(): if word not in token_index:
token_index[word] = len(token_index) + 1
#设置句子的最大长度max_length = 10results = np.zeros((len(samples), max_length, max(token_index.values()) + 1))for i, sample in enumerate(samples): for j, word in list(enumerate(sample.split()))[: max_length]:
index = token_index.get(word)
results[i, j, index] = 1.
print("{0} -> {1}".format(word, results[i, j]))上面代码运行后结果如下:

屏幕快照 2018-08-02 下午4.19.33.png
其实这种”脏活累活“不需要我们亲自动手,keras框架提供了一系列接口帮我们省却了这些麻烦,下面代码同样能实现相同内容:
from keras.preprocessing.text import Tokenizer
samples = ['The cat jump over the dog', 'The dog ate my homework']#只考虑最常使用的前1000个单词tokenizer = Tokenizer(num_words = 1000)
tokenizer.fit_on_texts(samples)#把句子分解成单词数组sequences = tokenizer.texts_to_sequences(samples)
print(sequences)
one_hot_vecs = tokenizer.texts_to_matrix(samples, mode='binary')
word_index = tokenizer.word_index
print("当前总共有%s个不同单词"%len(word_index))上面代码运行后,结果如下:
[[1, 3, 4, 5, 1, 2], [1, 2, 6, 7, 8]] 当前总共有8个不同单词
one_hot_vecs对应两个含有1000个元素的向量,第一个向量的第1,3,4,5个元素为1,其余全为0,第二个向量第1,2,6,7,8个元素为1,其余全为0.
接下来我们要看自然语言处理中一个极为关键的概念叫word embedding,也就是用非零向量来表示每一个单词。one-hot-vector对单词进行编码有很多缺陷,一是冗余过多,一大堆0,然后只有一个1,二是向量的维度过高,有多少个单词,向量就有多少维度,这会给计算带来很多麻烦,word-embedding把原来高维度的冗余向量转换为低纬度的,信息量强的向量,转换后的向量,无论单词量多大,向量的维度一般只有256维到1024维。
单词向量化的一个关键目标是,意思相近的单词,他们对应的向量之间的距离要接近,例如”good","fine"都表示“好”的意思,因此这两个单词对应的向量在空间上要比较接近的,也就是说意思相近的单词,他们对应的向量在空间上的距离应该比较小。假设给定4个单词:‘cat', 'dog', 'wolf', 'tiger',其中前两个猫和狗相似性强,后两个狼和狗相似性强,因此当他们转换成向量时,在空间距离上会形成两个集合,例如下图:
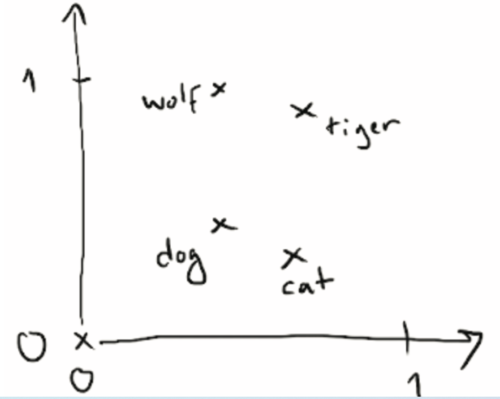
屏幕快照 2018-08-02 下午5.16.10.png
给定一个单词,我们如何生成对应向量呢?我们可以构造一个网络来实现这个目标,假设有两个单词,"good", "fine",我们随机给他们赋值两个向量,然后不断的训练网络,让这两个向量之间的距离变得越来越小,好在我们不用从零开始开发这样的网络,keras框架给我们提供了现成可用的类似网络,我们看下面一段代码:
from keras.layers import Embedding#Embedding对象接收两个参数,一个是单词量总数,另一个是单词向量的维度embedding_layer = Embedding(1000, 64)
上面代码创建一个叫Embedding的网络层,它接收的参数格式如(samples, sequence_length),假设我们现在有32条句子,每条句子最多包含10个单词,那么我们提交的输入参数就是(32, 10),Embedding一开始会给每个单词随意生成一个含有64个元素的向量,然后通过读入大量的数据,调整每个单词对应的向量,让意思相近的单词所对应的向量在空间上的距离越来越近。
详细理论不多说,我们先跑起来一个例子,看看如何分析影评文本所展现的情绪,我们使用的还是以前见过的IMDB数据,我们只抽取每篇影评的前20个单词,然后为单词向量化,由于影评中只有两种情绪,好和坏,好影评中所用到的单词大多含有“好”的意思,因此对应的向量在空间上会聚合在一起形成一个集合,坏影评使用的单词大多都包含“坏”的意思,于是他们对应的向量就会聚合到一起形成另一个集合,当遇到新影评时,我们也把它的前20个单词向量化,然后看这些向量靠近哪一个集合,如果靠近第一个集合,我们就预测该影评包含正能量,如果靠近第二个集合,我们就认为影评包含负能量。我们看看代码的实现:
from keras.models import Sequentialfrom keras.layers import Flatten, Dense model = Sequential()#在网络中添加Embedding层,专门用于把单词转换成向量model.add(Embedding(10000, 8, input_length=maxlen))''' 我们给Embeding层输入长度不超过maxlen的单词向量,它为每个单词构造长度为8的向量 它会输出格式为(samples, maxlen, 8)的结果,然后我们把它转换为(samples, maxlen*8)的 二维格式 '''model.add(Flatten())#我们在顶部加一层只含有1个神经元的网络层,把Embedding层的输出结果对应成两个类别model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics = ['acc']) model.summary() history = model.fit(x_train, y_train, epochs = 10, batch_size = 32, validation_split=0.2)
运行上面代码后,我们把结果绘制出来,看看网络对检验是数据集的识别准确率:
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)#绘制模型对训练数据和校验数据判断的准确率plt.plot(epochs, acc, 'bo', label = 'trainning acc')
plt.plot(epochs, val_acc, 'b', label = 'validation acc')
plt.title('Trainning and validation accuary')
plt.legend()
plt.show()
plt.figure()#绘制模型对训练数据和校验数据判断的错误率plt.plot(epochs, loss, 'bo', label = 'Trainning loss')
plt.plot(epochs, val_loss, 'b', label = 'Validation loss')
plt.title('Trainning and validation loss')
plt.legend()
plt.show()上面代码运行后结果如下:
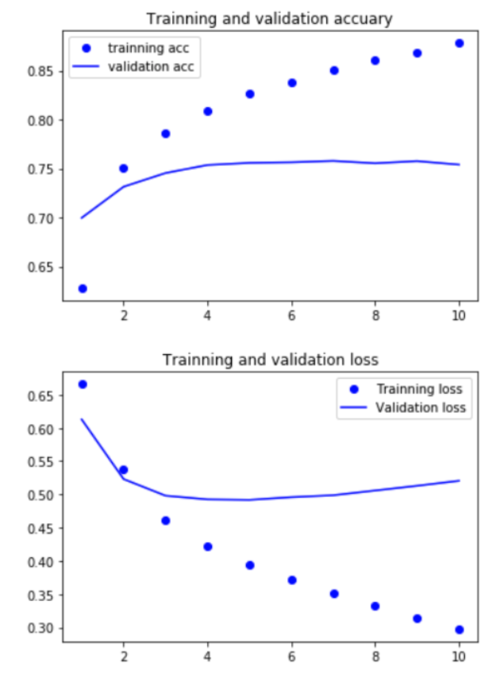
屏幕快照 2018-08-03 上午8.28.29.png
我们从上图可以看到蓝色实线看出,仅仅通过将影评的前20个单词向量化,在没使用任何调优手段的情况下,网络对校验是数据的识别准确率就达到75%左右。
还记得前面我们使用预先训练好的网络大大提升图片识别率吗,单词向量化也一样,有人使用上面提到的Embedding网络层分析读取大量文本后,为常用的英文单词都建立了对应的向量。我们自己运用神经网络处理具体问题时,一大困难在于数据量太少,巧妇难为无米之炊,数据量太小,神经网络的精确度会受到极大的制约,如果我们手上的文本数量很少,那么为单词建立的向量就不会很准确,要弥补这些缺陷,我们可以使用别人训练好的结果。
网络时代的一大优势就是,有人愿意把自己的劳动果实无偿分享出来。当前实现单词向量化的最好算法是由Google研究员Mikolov在2013年发明的Word2Vec算法,有人或组织就使用该算法分析大量英文文本后,为常用的单词建立向量,并把这些向量信息放在网上供人下载。另一个常用的单词向量数据库叫"GloVe",是由斯坦福教授根据单词的统计特性开发的向量化算法对常用单词向量化后形成的数据库。
在下一节我们将看看,如何使用预先训练的单词向量化数据"GloVe"实现原始文本的分割,量化并进行有效的分析。
作者:望月从良
链接:https://www.jianshu.com/p/9c12c3761950
共同学习,写下你的评论
评论加载中...
作者其他优质文章



