
正文
是什么
索引用于快速的查询某些特殊列的某些行。如果没有索引, MySQL 必须从第一行开始,然后通过搜索整个表来查询有关的行。表越大,查询的成本越大。如果表有了索引的话,那么 MySQL 可以很快的确定数据的位置,而不用查询整个表格。这比顺序的读取每一行要快的多。索引就像我们查字典时的目录一样,我们通过查询字典的目录,可以定位到某一行数据。
大多数的 MySQL 的索引(主键索引,唯一索引,普通索引,全文索引)都是 B-trees 结构。例外的情况有:在空间数据类型使用 R-trees 结构。存储引擎为 MEMORY 的数据库,也可以支持哈希索引。InnoDB 存储引擎的全文索引使用反向列表结构。
使用场景
MySQL 会使用到索引的场景如下:
1.根据一个条件快速的匹配到对应的行。
2.缩小查询影响行数。如果一个查询字段有多个索引,MySQL 通常选择使用影响行数最小的索引(选择性最高的索引)。索引的选择性的计算 select count(distinct name) / count(*) from table;
3.对于组合索引,索引左边的列可以用索引前缀优化器来查询数据。例如,你有个三列的组合索引(col1,col2,col3) ,那么你可以使用索引查询(col1),(col1,col2),(col1,col2,col3)这三种组合的数据。有关于组合索引,详细请看另外一篇博客 MySQL 组合索引
4.当和其他表进行连表查询的时候,如果进行判断的列的数据类型和大小相同,那么再这两个列上使用索引,可以让判断更加效率。例如:在如下查询中,给tb1.name和tb2.name添加索引会提升查询效率。 SELECT * FROM tb1, tb2 WHERE tb1. name = tb2. name
在这里,VARCHAR 与 CHAR 被认为是相同的类型。需要注意的是,如果要让索引生效,不仅需要类型一致,大小也必须一致。例如,VARCHAR(10) 和 CHAR(10) 大小相同可以使用索引,但 VARCHAR(10) 与 CHAR(15)就无法使用索引。
5.查找索引列的 MIN() 或 MAX()值。
6.通过索引列进行排序或分组,或者组合索引的左前缀进行排序或分组。
7.查询索引列的内容。(如果只需要返回索引列的值,那么不需要查询数据行,直接从内存中读取检索值。这种情况称为覆盖索引)例如: SELECT key_part FROM table WHERE key_part=1
对于小型表或报表查询处理大多数或所有行的大型表的查询,索引不太重要。当查询需要访问大多数行时,顺序读取比通过索引更快。顺序读取可以最大限度地减少磁盘搜索,即使查询不需要所有行也是如此。只有数据较大,并且需要访问其中一部分数据的时候,索引才会显得比较重要。
怎么用
查看索引
SHOW INDEX FROM table
运行后,显示结果如下:

其中,各个字段的含义:
table: 表的名称
Non_unique: 索引是否可以重复。不可以重复则为0;可以重复则为1。
Key_name: 索引名称。创建的时候,可以选择输入,不输入 MySQL 自动生成。如果索引是主键,则名称始终为 PRIMARY。
Seq_in_index: 索引中的列序列号,从1开始。
Column_name: 索引涉及到的列的名称。
Collation:列如何在索引中排序。这可以具有值 A(ascending 升序),D ( descending 降序)或NULL(未排序)。
Cardinality: 索引中唯一值的数量(不是实时更新的准确数据)。
Sub_part: 索引前缀长度。如果使用字段的部分字符作为索引,那么显示索引字符数量。如果使用整个字段都被索引,那么为 NULL。
Packed: key的打包方式,NULL 表示不打包。
Null: 索引列包含 NULL 或者 ‘’ 的时候,会是 YES。
Index_type: 索引类型。(BTREE, FULLTEXT,HASH, RTREE)之一。
Comment: 未在当前列中描述的索引信息,例如 disabled 索引是否已禁用。
Index_comment: 在创建索引时提供的注释。
Visible: 索引是否对优化程序可见(有的版本会出现该信息)。
添加索引
CREATE INDEX index_name ON table_name (key_part,...)
ALTER TABLE t1 ADD INDEX index_name (key_part)
通常,在创建表时创建索引。对于InnoDB存储引擎的表。其中主键确定数据的物理布局,可以向现有表中添加索引。key_part 表示组成索引的列的列名,如果是多个列名,那么将产生一个组合索引。在 key_part 参数后可以添加 ASC 或者 DESC 去指定索引按照正序排列还是倒序排列。
关于创建索引需要注意的是:
组合索引
组合索引是一个由多个列组成的索引。举例说明:例如在表 address 中有三个字段,分别为 Provincial 省 city 市 county 县 在建表的时候,用这三个字段组成一个组合索引。代码如下:


1 CREATE TABLE address (2 provincial VARCHAR (10),3 city VARCHAR (10),4 county VARCHAR (10),5 INDEX (provincial, city, county)6 )
CREATE TABLE address
这里的索引是这样创建的:首先按照省排序,然后,再根据同一个省的内容,按照市进行排序,最后,按照县去排序。即,首先按照第一列进行索引排序,如果第一列内容一致,那么按照第二列进行排序,以此类推。
前缀索引
如果将字符串的列作为索引,可以创建前缀索引。一般情况下某个前缀的选择性也是足够高的,足以满足查询性能。对于BLOB,TEXT,或者很长的VARCHAR类型的列,必须使用前缀索引。前缀索引以字节为单位。前缀索引支持的长度取决于存储引擎。例如,对于InnoDB 使用 REDUNDANT 或 COMPACT 行格式的表, 前缀最长可达767字节。对于InnoDB使用DYNAMIC 或 COMPRESSED 行格式的表, 前缀长度限制为3072字节 。对于MyISAM表,前缀长度限制为1000个字节。
如果指定的索引前缀超过最大列数据类型大小,对于非唯一索引,如果启用了严格的SQL模式,创建会发生错误。如果未启用严格SQL模式,索引长度减少到最大列数据类型大小,并产生警告。
创建前缀索引的长度,取决于索引的选择性。详见另外一篇博客:索引选择性
创建前缀索引语法如下(这里的10 表示截取前10个字符):
CREATE INDEX key_part_name ON table_name (key_part(10));
ALTER TABLE table_name ADD INDEX index_name (key_part(10))
方法索引
这里的索引类型英文名称为:Functional Key Parts 这里作者并不清楚官方的翻译名称为啥,只是根据索引的方式进行翻译。如果不对,欢迎大神指正。
这个索引类似于两个前缀索引的拼接。直接举个例子就明白了:在 t1 表中有两个列,col1 和 col2 我要创建一个包含完整的 col1 列和 col2 列的前10个字节组成一个组合索引。代码如下:
CREATE TABLE t1 ( col1 VARCHAR(10), col2 VARCHAR(20), INDEX (col1, col2(10)) );
Functional Key Parts
在 MySQL 8.0.13版本及更高版本中,MySQL 支持表达式进行索引。这里,需要将运算表达式写在括号内进行缩印的声明。例如:
1 -- 方法索引 2 CREATE TABLE t1 ( 3 col1 INT, 4 col2 INT, 5 INDEX func_index ((ABS(col1))) 6 ); 7 8 CREATE INDEX idx1 ON t1 ((col1 + col2)); 9 10 CREATE INDEX idx2 ON t1 (11 (col1 + col2),12 (col1 - col2),13 col114 );15 16 ALTER TABLE t1 ADD INDEX ((col1 * 40) DESC);
Functional Key Parts
唯一索引
通过 UNIQUE 创建的索引。索引列的内容非null值的时候必须是唯一的,null值可以不唯一。如果添加重复值,则会发生错误。如果在创建唯一索引的时候指定前缀值,那么前缀必须是唯一的。创建语法: CREATE UNIQUE INDEX unique_index_name ON table_name (key_part)
全文索引
全文索引,顾名思义,支持全文检索的索引。仅支持 Innodb 和 MyISAM 两种存储引擎。并且只能包括 CHAR, VARCHAR 和 TEXT 列,索引始终发生在整个列上,不支持前缀索引。(即使写了也没用)可以对字段进行全文检索。对于数据量比较大的数据集,先将数据加载到没有数据的表中,然后再添加索引,效率要比把数据直接向有索引的表中添加高。
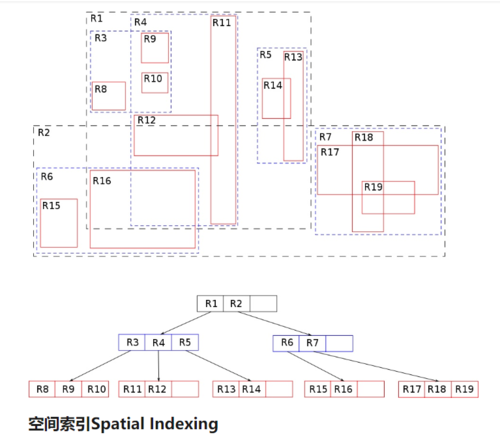
空间索引
空间索引是为空间搜索提供一种合适的数据结构,以提高搜索速度。对于空间索引,作者研究并不多,这里大概介绍下空间索引的用处。等以后研究深刻后,再补上这部分内容。首先,空间索引是干什么用的?举例:当我们需要按照某个点,查询附近的50米内都有哪些客户存在。对于这个需求,可能的解法如下:
1.我们可以根据用户的经纬度,去计算每个人跟我们的当前点的距离,然后跟50米去作对比。这在客户数据量少的时候,还可以这么做,数据量大的时候,将会特别的浪费性能。
2.先画一个方框,把50米范围的数据的经纬度画出来,通过经纬度的值进行筛选后,得到一个正方形的区域,然后再进行计算。这时候,会少很多计算,但依然不是最优方案。
3.使用空间索引。将空间按照一定规则划分为不同的区域,在检索的时候,根据设计的区域,取出相应的数据。空间索引结构图如下(图片来自知乎):
删除索引
删除索引没啥好说的,语句如下:
1 DROP INDEX index_name ON talbe_name2 ALTER TABLE table_name DROP INDEX index_name
DROP INDEX
如果索引所在的列删除,那么该列对应的索引也会自动删除。
索引优化
主键优化
表的主键是唯一且非空的索引,在使用InnoDB存储引擎的时候,表数据直接挂载在主键的叶子节点上,是查询速度最快的索引。
如果表的内容很多,并且很重要。但是没有明显的列和列的集合作为主键的话,可以单独创建一个自动增长的值作为主键。当使用外链查询的时候,这个id可以作为指向内容的指针。
外键优化
如果你的表有很多列,你可以将查询频率比较低的列拆分到其他表格,并通过复制id的方式让它们与主表关联。这样,每个小表都会有个主键来快速查找其他数据。在查询的时候,就可以仅查询自己需要的列集。这时,查询会执行较少的 I/O 并且占用较少的内存。整体原则是:为了提高性能,尽可能少的从磁盘读取数据。这就是拆表的原则。
文章来源:http://www.cnblogs.com/liyasong/
共同学习,写下你的评论
评论加载中...
作者其他优质文章


