

-
Wordcount
//Scala Object WordCount{ def main(args: Array[String]){ val conf= new SparkConf().setAppName("wordcount") val sc = new SparkContext(conf) val input= sc.textFile("/home/soft/hello.txt") //RDD操作:压扁 val lines = input.flatMap(line=> line.split(" ")) //转换成kv对 val count= lines.map(word=>(word,1)).reduceByKey{case (x,y)=>x+y} val output= count.saveAsTextFile("/home/result") } }Project Structure -> Artifacts ->+然后 BuildArtifacts 打包Jar
启动集群:
启动master start-master.sh
启动worker spark-class
提交作业 spark-submit
#启动worker spark-class org.apache.spark.deploy.worker.Worker spark://localhost.localdomain:4040 #提交 spark-submit --master spark://localhost.localdomain:4040 --class WordCount /home/soft/hello.jar #上传jar包 rz -be
查看全部 -

RDDS的特性
 查看全部
查看全部 -


RDD基本操作之action
 查看全部
查看全部 -

rdd缓存级别
 查看全部
查看全部 -

小结
查看全部 -
distinct:驱虫
union:合并
intersection:交集
subtract:差集
 查看全部
查看全部 -
spark与hadoop
spark计算时效:几秒钟、几分钟
存储:基于内存计算,需要借助hdfs持久化数据
查看全部 -

spark core



 查看全部
查看全部 -

spark的生态
查看全部 -
take(n):
随机取n个数
查看全部 -
collect()
查看全部 -
:222222
查看全部 -
rdd action:
查看全部 -
后续课程:
Spark架构
Spark运行过程
Spark程序部署
查看全部 -
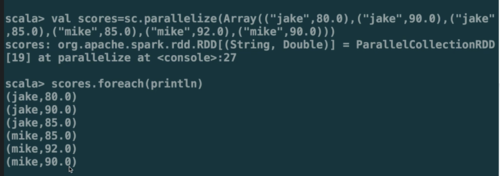
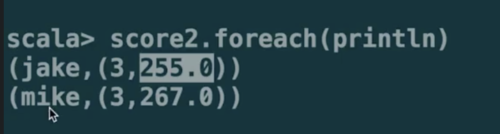
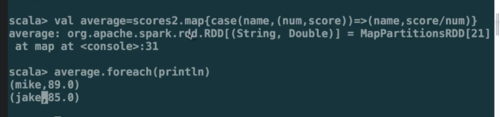
combineByKey():
(createCombiner, mergeValue, mergeCombiners, partitioner)
最常用的基于key的聚合函数,返回的类型可以与输入类型不一样。
许多基于key的聚合函数都用到了它,像groupByKey()
遍历partition中的元素,元素的key,要么之前见过的,要么不是。
如果是新元素,使用我们提供的createCombiner()函数
如果是这个partition中已经存在的key,就会使用mergeValue()函数
合并每个partition的结果的时候,使用mergeCombiners()函数

 查看全部
查看全部




















举报
0/150
提交
取消