课程
/后端开发
/Python
/Python开发简单爬虫
有人根据这个视频调出来的吗? 感觉代码一模一样,,,,就是craw failed一次又一次。。。
2017-02-20
源自:Python开发简单爬虫 7-2
正在回答
刚爬成功的,你失败肯定是哪出错了,对照这检查一遍
CCcc_cc_chen
网址变了:
lifelegendc 提问者
一样没有一次成功,都是失败
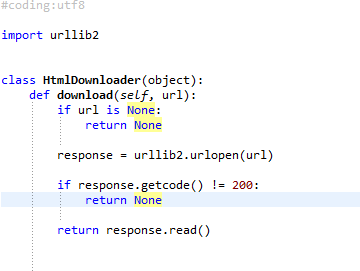
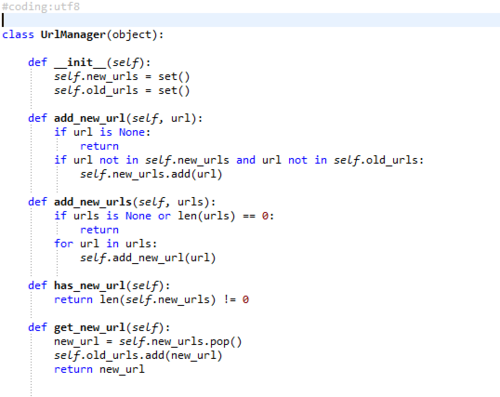
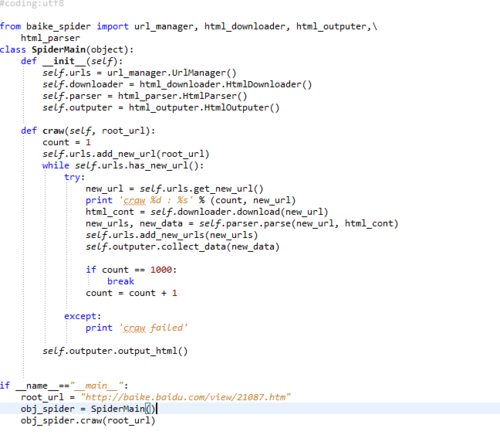
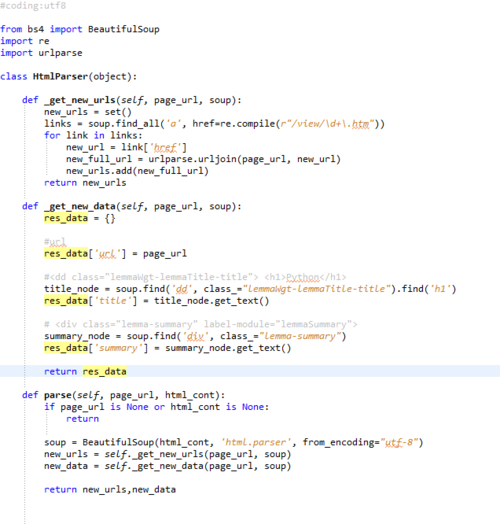
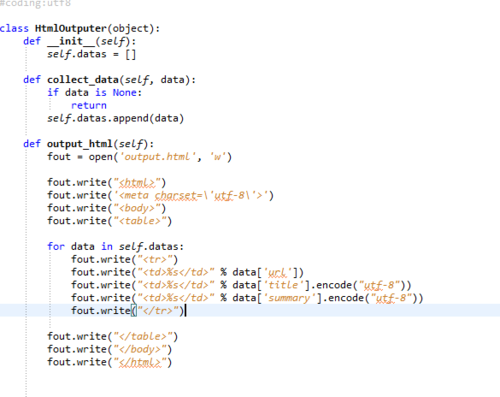
仔细检查,特别是HtmlParser和SpiderMain这两个模块,是最容易出错的地方
老师的代码无误,确实成功了。
我把我犯的错误贴出来给大家看看,自己是不是犯了一样的错:
调用函数的时候一定要注意通过对象调用,即对象名.函数,我写成类名.函数了
beutifulsoup对象实例化,里面有个参数是,html.parser,我把点号写成下划线了
。。。总之,就是你的代码跟老师写的不一样
举报
本教程带您解开python爬虫这门神奇技术的面纱
购课补贴联系客服咨询优惠详情
慕课网APP您的移动学习伙伴
扫描二维码关注慕课网微信公众号