我在使用请求库提取数据时遇到问题。我想从nesine.com获取比赛时间、球队名称、结果赔率例子:Match time: 19.00Team Name 1 : BolusporTeam Name 2 : MenemenMatch Result (1) : 2.10Match Result (X) : 2.65Match Result (2) : 2.65Match Result (Lower) : 1.55Match Result (Upper) : 1.75我为此做了很多尝试,但没有一个是积极的。这是我尝试过的代码之一 r = requests.get("https://www.nesine.com/iddaa?et=1&lc=584%7C1980&le=1&ocg=MS-2%2C5>=Pop%C3%BCler") source = BeautifulSoup(r.content,"lxml") times = source.find_all("div",attrs={"class":"time"}) names = source.find_all("div",attrs={"class":"name"}) return times,names
1 回答
开满天机
TA贡献1786条经验 获得超13个赞
首先值得理解为什么您不能以requests您正在执行的方式检索此数据,以及您如何能够做到这一点。
requests工作流程相当简单 - 该.get()函数向服务器发送 HTTP 请求,请求有关页面的相关资源。然后,服务器回复组成页面的相关 HTML、CSS 和 Javascript。与许多服务器一样,该服务器不会回复整个页面,而是使用服务器响应客户端的 Javascript,进一步将更多信息加载到页面中。当您加载网站并且您在尝试从中请求信息的框架内看到“正在加载”符号时,这一点在视觉上是显而易见的,但当您在Inspect Element 的Network选项卡中进行快速分析时,这一点会变得更加明显。
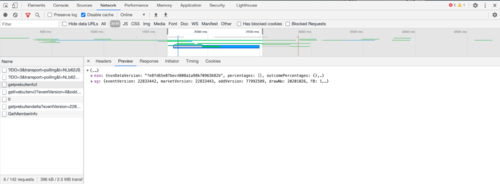
在大约 1,500 毫秒到 2,500 毫秒时,我的浏览器向 API 端点发送一个新请求,该请求似乎提取了您所寻求的相关信息(我只是在进一步挖掘后才知道这一点 - 不是一些疯狂的直觉)。与http://example.com进行比较,您可以看到一个简单的 HTML 和 CSS 网站如何仅回复初始GET数据:
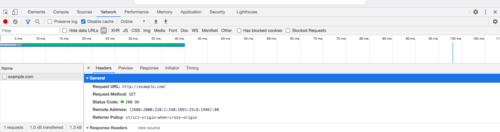
要提取您正在查找的信息,您必须查看“网络”选项卡并查看浏览器如何从服务器提取数据。对单词进行快速“查找”,Boluspor我们得到以下结果:
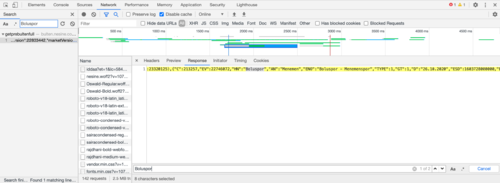
现在我们知道API 请求在哪里requests,然后我们可以查询它以获取相关信息。我建议首先单击实际结果来源的 URL ,然后选择“复制为提取”,您将得到以下内容:
fetch("https://bulten.nesine.com/api/bulten/getprebultenfull", {
"headers": {
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-language": "en-US,en;q=0.9",
"authorization": "Basic RDQ3MDc4RDMtNjcwQi00OUJBLTgxNUYtM0IyMjI2MTM1MTZCOkI4MzJCQjZGLTQwMjgtNDIwNS05NjFELTg1N0QxRTZEOTk0OA==",
"cache-control": "no-cache",
"content-type": "application/json; charset=utf-8",
"pragma": "no-cache",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site"
},
"referrer": "https://www.nesine.com/",
"referrerPolicy": "strict-origin-when-cross-origin",
"body": null,
"method": "GET",
"mode": "cors",
"credentials": "include"
});
仅上述内容似乎并不表明请求中发生了任何特殊情况(例如标头、参数等),因此单独访问端点应该可以工作 - 情况就是这样:
https://bulten.nesine.com/api/bulten/getprebultenfull
然后,您可以requests抓取该页面,通过json模块加载它,并开始组织数据。
添加回答
举报
0/150
提交
取消