
































































 阿竺 ·
阿竺 ·1. 前言
之前的小节中介绍了操作系统的进程,操作系统中有个创建进程的重要方法就是 fork 函数,当需要执行和本进程相关的独立任务时,一般需要创建一个有血缘关系的子进程。
2. fork 函数
面试官提问: Linux 系统中的 fork 函数是什么,有什么用途?
题目解析:
首先从定义上看,fork 函数的作用是在一个进程的基础上创建新的进程,原有的进程被定义为父进程,新的进程被定义为子进程。
在 C 语言中调用 fork() 函数即实现 fork 功能,示例:
#include<unistd.h> //包含fork函数的头文件
pid_t fork(void); //fork的返回类型为pid_t,我们可以看成int类型
认识一个函数,需要从函数的定义入手,了解函数做了什么事情,入参是什么,出参是什么。我们以 C 语言实现的一个典型的 fork 的程序入手,示例:
#include <unistd.h>
#include <stdio.h>
int main ()
{
pid_t fpid;
int count = 0;
fpid = fork();
if (fpid == 0) { //返回值是0,说明是子进程
printf("i am the child process, process id is %d\n", getpid());
count++;
} else if(fpid > 0) { //返回值>0,说明是父进程
printf("i am the parent process, process id is %d\n", getpid());
count++;
} else { //返回值<0,说明fork发生异常
printf("fork encounter exception, process id is %d\n", getpid());
}
//打印计数器
printf("after fork, counting result : %d\n", count);
return 0;
}
在 MacOS 系统上编译运行案例示例代码,运行结果如下图。
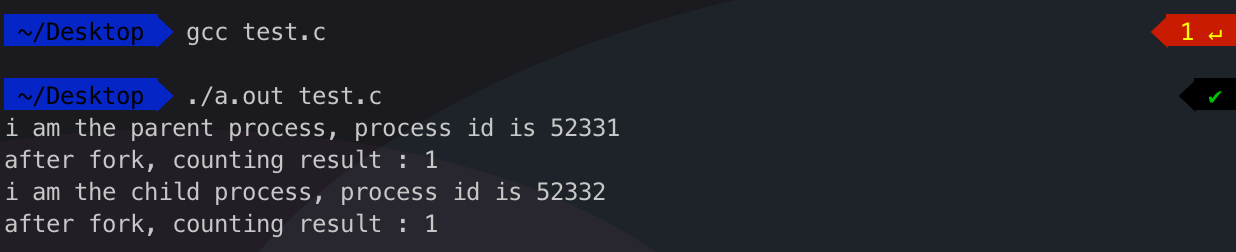
如果是不了解函数原理的前提下,仅仅从代码层面分析,在调用 fork() 函数之后,代码会进入 if-else 判断逻辑,在控制台输出一条语句,然后在控制台打印计数器的数值。但是从真正执行的结果来看,这两个打印动作都分别执行了两次,并不符合我们的预期。fork 之后的代码逻辑被执行了两次,而且两次进入的不同的分支,所以重点在于 fork 函数到底有啥作用。
按照定义、入参和出参三步走的框架,首先是分析函数的定义,调用 fork 函数之后发生了什么事情:
(1)分配内存:分配新的内存空间给子进程;
(2)拷贝数据:拷贝父进程的数据结构给子进程;
(3)加入列表:将新生成的子进程添加到操作系统的进程列表;
(4)返回结果:fork 函数调度并且返回。
然后是分析 fork 函数的入参,fork 函数入参是 void,也就是自动同步进程的上下文,不需要手动声明。
最后是分析 fork 函数的出参,fork 函数和程序员日常接触的函数不同,我们在 C 或者 Java 中定义的函数只会有一个返回值,fork 函数则是调用一次,返回二次。调用方(例如上述案例的 main 函数)根据返回值的不同判断处于父进程还是子进程。
(1)返回值 < 0:调用失败,一般是因为操作系统中的进程个数达到上限或者内存不足以分配给新的进程;
(2)返回值 = 0:调用成功,并且处于子进程;
(3)返回值 > 0:调用成功,并且处于父进程。
现在就不难理解,从调用 fork() 函数,代码实际上是被父子进程分别执行了一次,父进程的进程 id 是 52331,子进程的进程 id 是 52332。
在掌握原理之后,我们继续探究 fork 函数的应用场景。fork 函数的本质在原有的进程基础上创建一个新的进程,所以在网络通信中使用较多,例如在客户端发送一个 HTTP 请求打到服务器时,服务器进程 fork 出一个子进程用于处理单个请求,父进程则继续等待其他的请求。
3. 小结
本章节介绍了 Linux 的 fork 函数,fork 如同其英文名,就是进程的分叉。fork 函数简化了操作系统的进程管理,又提供了一个简单的多进程生成方案,在操作系统中的地位非常核心,候选人需要注意 fork 函数调用 1 次,返回 2 次的核心特性以及返回值。

 2026 imooc.com All Rights Reserved |
2026 imooc.com All Rights Reserved |