
































































 basil_2020 ·
basil_2020 ·BeatifulSoup 的使用
还记得之前我们在第一个爬虫案例中使用过的 BeatifulSoup 吗?这节课我们就来正式学习一下 BeatifulSoup 这个页面提取工具,通过本节课的学习你会熟悉使用 BeatifulSoup 提取常见的网页元素。
- BeatifulSoup 的基本概念
- BeatifuSoup 的解析器
- BeatifulSoup 的搜索筛选
1. BeatifulSoup 简介
使用 Requests 获取到页面源码后,我们需要一种工具来帮助我们结构化这些数据,从而方便我们检索需要的某个或者某些数据内容。BeautifulSoup 库就是这样一种工具,可以很方便我们对数据进行解析和数据的提取。
BeautifulSoup 的名字来源于大家耳熟能详的一部外国名著里面的小说,这部小说的名字叫做《爱丽丝梦游仙境》。从名字就可以看出,发明这个库的作者的目的是为了让使用这个库的人,心情舒畅,使用起来很方便舒适,接口简单人性化。
2. 安装 BeautifulSoup
因为 BeautifulSoup 并不是 Python 内置的库,我们需要额外安装它。我们现在普遍使用的版本是 BeautifulSoup4, 简称作 bs4。
使用 pip 来安装 BeautifulSoup 很简单,打开 CMD 窗口运行下面这条命令:
pip install beautifulsoup4
安装成功后,如图所示:
2. BeatifuSoup 解析器
解析器是一种帮我们结构化网页内容的工具,通过解析器,我们可以得到结构化的数据,而不是单纯的字符,方便我们解析和查找数据。
BeautifulSoup 的解析器有 html.parse,html5lib,lxml 等。BeautifulSoup 本身支持的标准库是 html.parse,html5lib。但是,lxml 的性能非常棒,以及拥有良好的容错能力,现在被广泛的使用。
解析器对比:
-
html.parse 是 Python 标准库的解析器,这个解析器执行速度不是太快,但是文档容错能力比较好。
-
html.5lib 同样是内置的解析器,它是通过浏览器的方式解析数据,可以生成良好的 HTML5 格式的文档,但是速度比较慢。
-
lxml 是第三方解析器,需要额外安装。这个解析器执行速度快,并且是唯一支持 XML 的解析器。在这里我们也会选用 lxml 来进行讲解。
安装 lxml 和安装 BeautifulSoup 类似,同样只需一行命令就好:
pip install lxml
安装成功后,如下所示:
3. BeautifulSoup 的四类对象
BeautifulSoup 将 HTML 转换成树形结构,每个节点都是 Python 对象,所有对象可以归纳为 4 种:
- Tag;
- NavigableString;
- BeautifulSoup;
- Comment。
下面我们一一来看下这四类对象:
- Tag(标签) ,指的就是 HTML 里面的标签,比如我们常见的 title,head 等标签。
<title></title>
- NavigableString (可遍历的字符串):在获取标签之后,我们需要取标签里内容文字,我们使用 string 属性来获取。string 属性就是输出标签里内容,它的类型就是 fNavigableString。
比如,我们可以通过 string 属性,获取 “慕课网” 字符串。
<title>慕课网</title>
-
BeautifulSoup (文档对象):表示一个文档的全部内容,也就是整个文档,是一种广义的 Tag 对象。
-
Comment (评论):注释对象,这个是 NavigableString 的特殊类型,也就是文本里面的注释内容。
指的是获取 HTML 的注释内容,如下所示:
<!-- 慕课网 -->
4. BeautifulSoup 搜索文档树
下面我们就来具体使用一下 BeautifulSoup 这个解析工具,我们首先模仿 HTML 页面结构创建一个字符串:
<html>
<head>
<title>hello world</title>
</head>
<body>
<div>
<p class="p-one a-item" id="aaa">python introduction</p>
<p class="p-one">Basic Python Class</p>
</div>
<p class="p-two a-item" id="bbb"><b>Java introduction</b></p>
<p class="p-two"><b>Basic Java Class</b></p>
</body>
</html>
4.1 字符串
from bs4 import BeautifulSoup
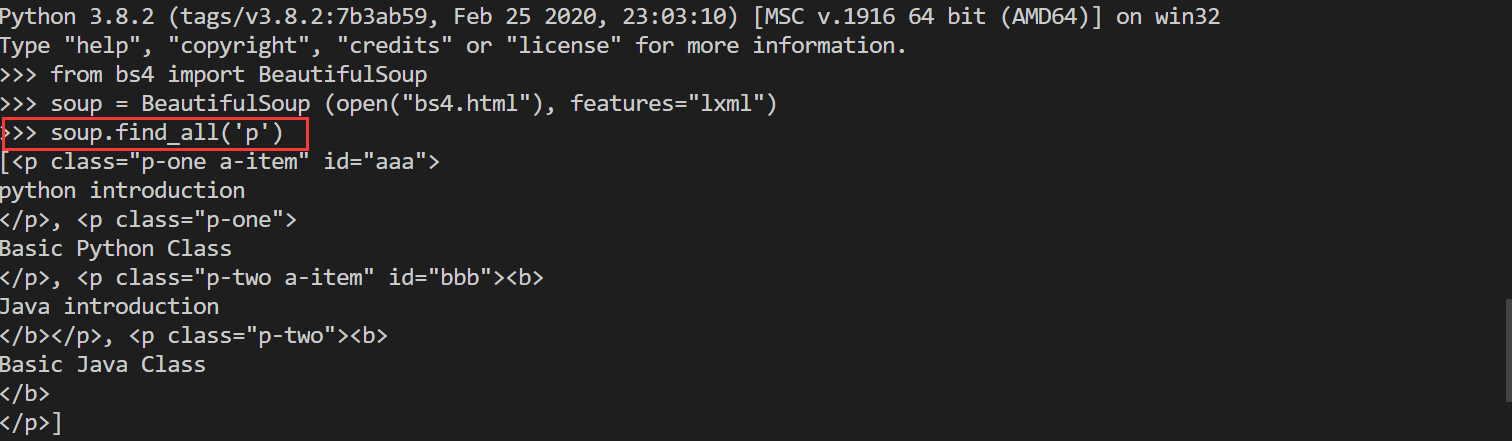
soup = BeautifulSoup (open("bs4.html"), features="lxml")
soup.find_all('p')
4.2 正则表达式
from bs4 import BeautifulSoup
import re
soup = BeautifulSoup (open("bs4.html"), features="lxml")
for tag in soup.find_all(re.compile("b")):
print(tag.name)

4.3 列表
from bs4 import BeautifulSoup
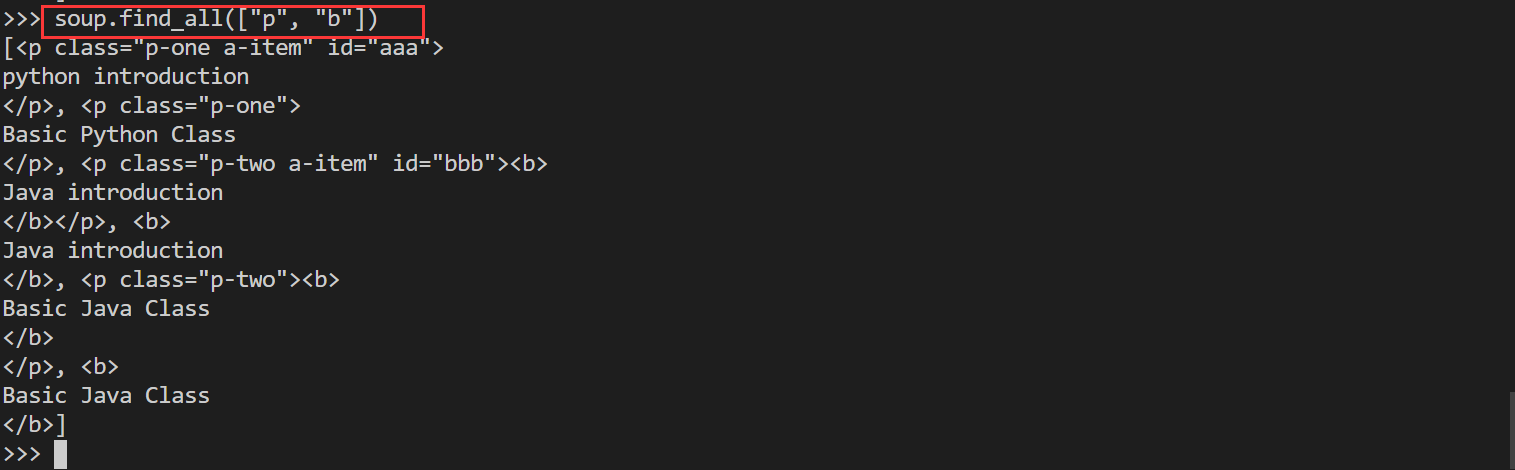
soup = BeautifulSoup (open("bs4.html"), features="lxml")
soup.find_all(["a", "b"])
4.4 搜索属性
from bs4 import BeautifulSoup
soup = BeautifulSoup (open("bs4.html"), features="lxml")
soup.find_all("p", id="aaa")

4.5 搜索字符串内容
from bs4 import BeautifulSoup
soup = BeautifulSoup (open("bs4.html"), features="lxml")
soup.find_all(string="Java")

4.6 搜索 CSS

from bs4 import BeautifulSoup
soup = BeautifulSoup (open("bs4.html"), features="lxml")
soup.find_all(["a", "b"])
5. 小结
工作中,我们一般经常的使用的方法就是 find_all 方法。但是,除了上述我们讲的 find_all 方法之外,BeautifulSoup 还有其他一些以 find 开头的方法,由于不是经常使用,这里就简单的列举一下,如果同学们感兴趣的话可以自己深入了解下。
| 方法名称 | 作用 |
|---|---|
| find_all() | 搜索当前节点的所有子节点和孙子节点,并直接返回所有结果。 |
| find_parents/find_parent | 搜索当前节点的父亲节点 |
| find_next_siblings/find_next_sibling | 搜索所有的后续的兄弟节点 |
| find_previous_siblings/find_previous_sibling | 搜有当前的兄弟节点 |
| find_all_next()/find_next | 对当前节点的后续标签和字符串进行循环迭代 |
| find_all_previous/find_previous | 对当前节点的前面标签和字符串进行循环迭代 |

 2026 imooc.com All Rights Reserved |
2026 imooc.com All Rights Reserved |