
































































 沈无奇 ·
沈无奇 ·Scrapy 运行架构与数据处理流程简介
今天我们来重点看看 Scrapy 爬虫框架的架构设计,它非常非常重要。Scrapy 的架构图能帮助我们理解其背后的整个运行流程,是我们深度掌握和定制化开发 Scrapy 插件的一个重要基础。此外,我们还会从整体角度过一遍 Scrapy 框架的源码,后续部分章节会进入到 Scrapy 的源码中去讲解,因此有必要先熟悉一遍 Scrapy 的源码目录。
1. Scrapy 架构介绍
首先来看 Scrapy 最经典的架构设计图,如下:
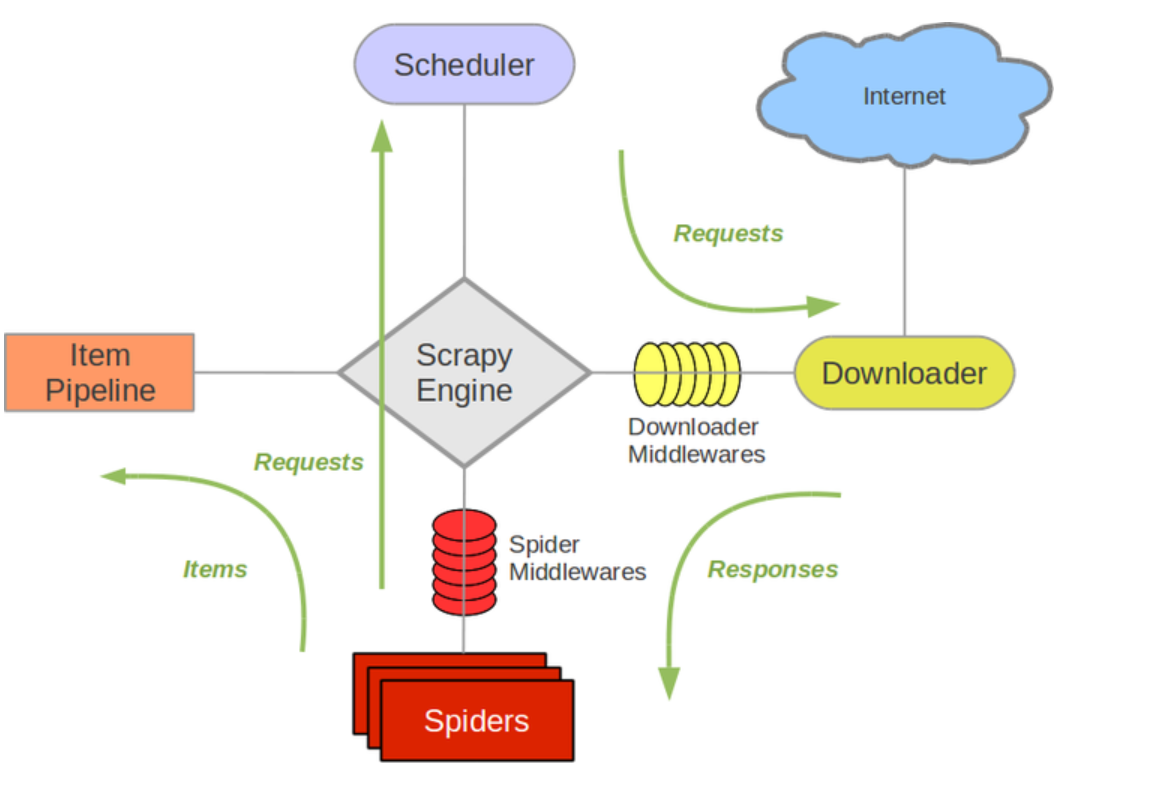
我们可以看到,Scrapy 框架中几个比较核心的组件包括:
- 位于核心位置的称为 Scrapy 引擎。它就好比一军的总司令,负责把控全局,指挥其它组件,协同作战;
- 图上方的是调度器 Scheduler:它接收引擎发生过来的请求,按照先后顺序,压入队列,同时会过滤重复请求;
- 图下方的爬虫 (Spiders) 组件,它主要负责构造 Request 请求发送给引擎,然后引擎会将该 Request 请求结果交到该组件中进行处理,解析出想要的 items 结果并传给 Item Pipelines 进行后续的处理;
- 图右边的**下载器 (Downloader) **,很明显它的职责是从互联网上下载网页数据;
- 最左边的 Item Pipeline,用于对生成的 Item 数据进行进一步处理。比如数据清洗、保存到数据库等;
- **中间件 (Downloaders Middlewares) **,包括爬虫中间件、下载中间件等,它们都是用于中间处理数据的。我们可以在此处选择对 item 的数据进行清洗、去重等操作,也可以在这里选择使用何种方式 (MySQL、MongoDB、Redis、甚至文件等) 保存得到的 item;
2. Scrapy 数据处理流程
而下面这张图是非常经典的 Scrapy 框架的数据处理流程图,这张数据流图非常重要,它详细描述了 Scrapy 框架背后的运行流程。按照图中的序号,我来给大家描述下 Scrapy 框架中的数据处理流程:
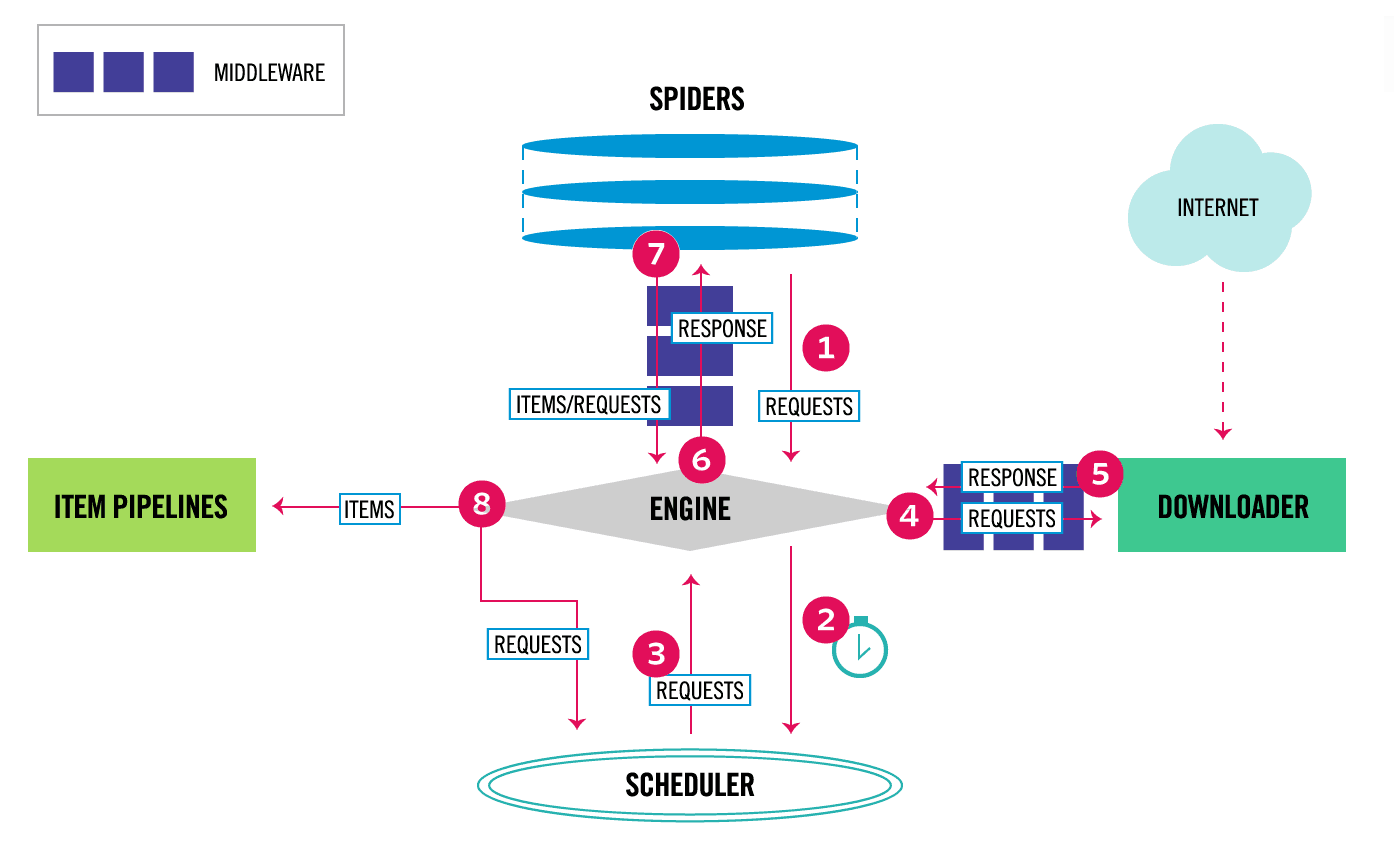
-
Spider 构造 Request 请求并提交给 Scrapy 引擎;这步中存在中间件操作,可以对请求设置代理 IP 等后再发送给引擎;
-
引擎将请求发生给调度器,调度器会根据请求中设置的优先级确定要执行的请求顺序;
-
引擎从调度器中获取将要执行的请求;
-
引擎通过下载中间件后,将请求传给下载器执行网页下载;
-
得到 HTTP 响应结果并将其封装成 Response 类,然后经过下载中间件处理后传递回引擎;
-
引擎接收到请求的响应结果后,通过爬虫的中间件将其发送给爬虫 (Spider) 去处理,对应我们前面案例中的
parse()方法或者自定义的回调方法book_list_parse(); -
爬虫会将网页数据抽取成一条数据实体 (Item) 以及新的请求(比如下一页的 URL),再次发送给引擎处理;
-
引擎将爬虫获取到的 Item 发送给项目管道 (Item Pipelines),在项目管道中我们可以实现数据的持久化,比如保存到 MySQL 数据库或者 MongoDB 中 。同时,如果有新的请求也会发送给引擎,在继续从第二步开始重复执行,直到最后调度器中没有请求为止。
大家将这八个步骤和我们前面实现的互动出版网数据爬取的代码进行实例分析,是不是会有更进一步的理解呢?这上面的架构图和数据流图对于我们学习和理解 Scrapy 框架都非常重要,大家一定要掌握!
3. Scrapy 源码初探
看过了 Scrapy 的架构和数据处理流程,我们来简单了解下 Scrapy 框架的源码结构。熟悉和理解 Scrapy 框架的源码,对于我们日常开发的好处不言而喻,我总结了如下三点原因:
- 熟悉掌握 Scrapy 框架用法的最好方式就是阅读源码;
- 提升编程能力的最好途径也是阅读源码;此外,Twisted 模块在 Scrapy 框架中应用广泛,而国内关于该框架资源十分匮乏,我们可以借助 Scrapy 框架来完整学习 Twisted 模块的使用,体验这样一个异步通信机制带给我们的性能体验;
- 方便问题排错以及后续基于 Scrapy 的深度定制开发。只有熟悉了 Scrapy 源码,我们才能针对 Scrapy 框架进行深度定制开发,实现与我们业务相关的爬虫框架;另外,熟悉源码能方便我们在调试 Scrapy 爬虫时快速定位为题原因,高效解决问题,这是一个经验丰富的爬虫工程师必须具备的技能;
截止到这篇文章撰写完成(2020 年 7 月 12 日),Scrapy 最新发布的版本是 2.2.0 版本。我们从 github 上选择稳定的 scrapy 源码包,下载下来后解压并使用 VScode 软件打开该源码目录。下面就是 Scrapy-2.2.0 的源码内容:
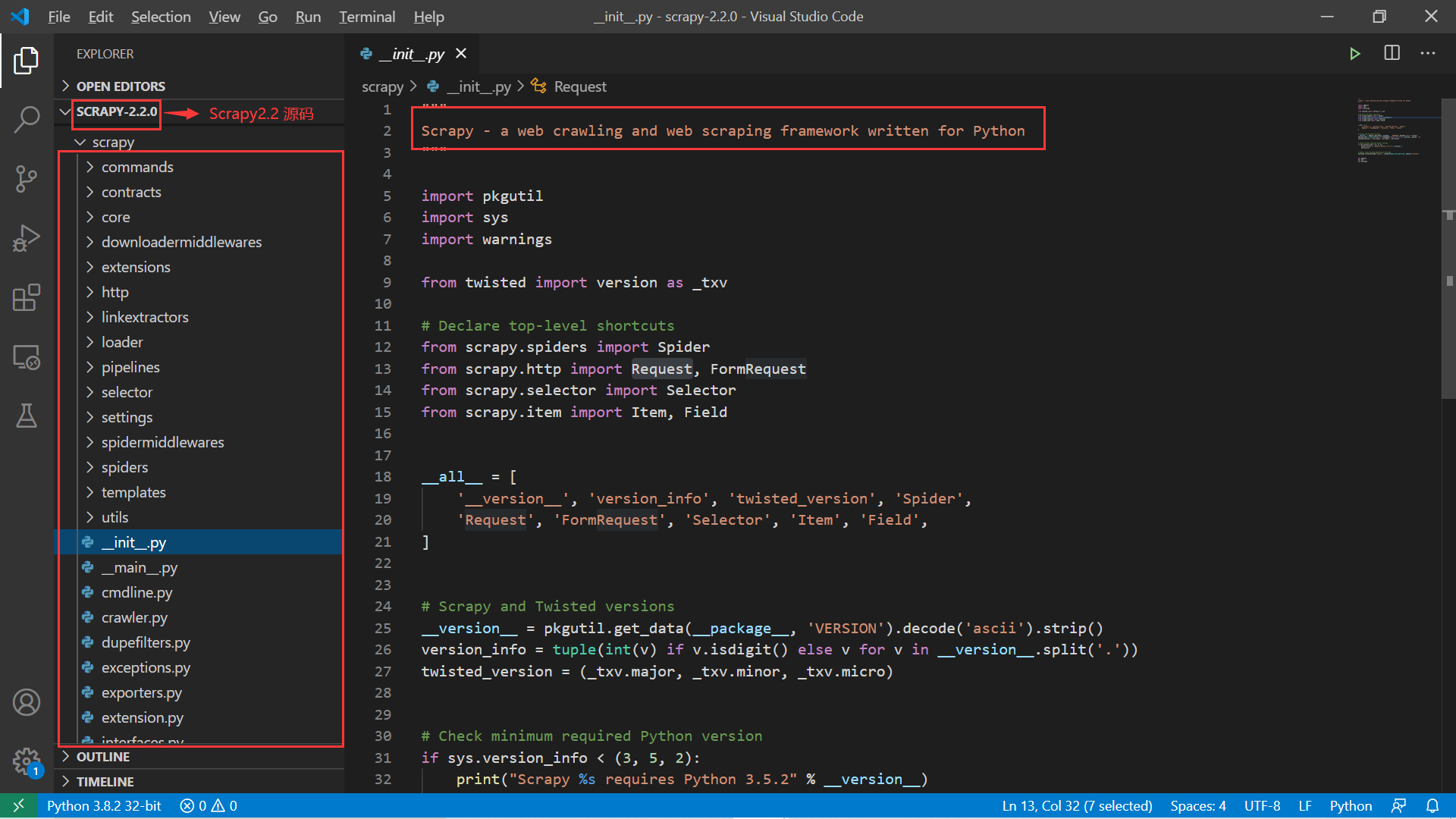
我们依次对这些源码目录和文件进行简单说明,后面我们在学习中会逐渐深入源码去分析 Scrapy 框架的行为以及追踪爬虫的执行过程。来依次看看 Scrapy 源码的目录结构:
- commands目录:该目录下的文件正是 scrapy 所支持的命令。比如我们生成爬虫项目使用的命令
scrapy startproject xxxx对应着文件startproject.py,命令scrapy shell http://www.baidu.com对应的执行文件为shell.py。因此,如果我们要追踪 scrapy 命令的运行过程就可以从这里入手跟踪代码了; - contracts 目录:定义了若干简单 python 文件;
- core 目录:非常核心,定义了 scrapy 框架中的核心类与方法;
- downloadermiddleswares 目录:下载中间件相关的代码;
- extensions 目录:定义了一些扩展方法,比如 debug.py,telnet.py 等代码文件;
- http 目录:该目录下定义了 Request 和 Response 类及其相关的扩展类。下节和下下节会详细介绍该目录下的源码文件;
- linkextractors 目录:这里的代码主要是辅助
scrapy核心对网页的链接进行抽取,定义了一系列的抽取类; - loader目录:该目录下的代码是 Item Loader,具体信息可以参考源码下的
docs/topics/loaders.rst文件进行深入了解; - pipelines 目录:和 pipelines 模块相关,主要对爬虫抽取到的 items 数据进行再次处理;
- selector 目录:该目录下定义了解析网页的 Selector,主要是封装了 parsel 模块的 Selector 和 SelectorList;
- settings 目录:这里定义了操作配置文件的相关类以及一个默认的配置文件 (default_settings.py);
- spidermiddlewares 目录:定义了爬虫中间件的相关类与方法,
- spiders 目录:定义了爬虫模块的核心类;
- templates 目录:下面保存了创建 scrapy 项目所需要的一些模板文件;
- utils 目录:一些常用的辅助函数;
- 其他文件:一些比较核心的代码文件都在这里,比如 cmdline.py、crawler.py、shell.py 等。
看完这些介绍后有没有什么感觉?是不是觉得一个非常流行的 Python 框架也就那样?
当然不是,在这里我们只是介绍了它的表面,并没有深究其内部细节。任何一个流行的框架必有其独特的优势,且必须代码精良。
Scrapy 框架在简洁易用上做的非常不错,此外由于其使用 Twisted 作为其异步处理框架,因此基于 Scrapy 框架开发的爬虫一般具有不错的性能,加之良好的社区、文档和框架生态,终造就了今天的 Scrapy。接下来,我们会慢慢深入这些目录去探索 Scrapy 的源码,最后实现彻底掌握 Scrapy 框架的目的。
4. 小结
今天我们详细描述了 Scrapy 框架的架构设计,介绍了其重点的组成模块和工作职责,接下来我们对 Scrapy 框架的源码进行了简单的介绍和预览,为我们后续深入分析 Scrapy 框架打好相应的基础。

 2026 imooc.com All Rights Reserved |
2026 imooc.com All Rights Reserved |