
































































 陈子兴 ·
陈子兴 ·大小端序之争
1. 前言
在 C 语言中,内置的基本类型有 char、short、int、long、double 等,对于整型类型来说,还区分 signed 和 unsigned。在 Java 语言中,内置类型也有 char、short、int、long、double 等,只不过 Java 没有 unsigned 类型。char 类型在 C 语言是占用 1 字节长度,而在 Java 语言中占用 2 字节长度。而其他类型不管在 C 语言中,还是在 Java 语言中,都是占用多个字节长度。
我们知道 CPU 访问内存是通过地址总线完成的,一块连续的内存空间是经过编址的,每一个地址编号对应 1 字节长度的内存空间,地址空间是从低地址到高地址增长的。如果要在内存中存储 0xAABBCCDD 这样一个长度为 4 字节的十六进制整数,需要 4 字节的内存空间。内存空间示意如下:
100 101 102 103 -------> 内存地址由低到高增长的方向
+----+----+----+----+
| | | | |
+----+----+----+----+
那么 0xAA 是存储在地址编号为 100 的空间呢?还是存储在地址编号为 103 的空间呢?这就是本节要讨论的字节序的问题。
字节序有大端序(Big-Endian)和小端序(Little-Endian)之分。对于前面提到的十六进制整数 0xAABBCCDD 来说,如果按照大端序在内存中存储,那么从低地址到高地址的存储顺序依次是 0xAA、0xBB、0xCC、0xDD;如果按照小端序在内存中存储,那么从低地址到高地址的存储顺序依次是 0xDD、0xCC、0xBB、0xAA。
文字描述还是有些抽象,我们通过一张图来直观感受一下内存字节序。
2. 计算机的字节序
在操作系统课程中,我们学过现代操作系统的内存管理机制是虚拟内存管理机制,对于 32 位系统来说,每一个进程都有 4G( 2^32)字节长度的虚拟地址空间,也叫线性地址空间。我们先看一张图。
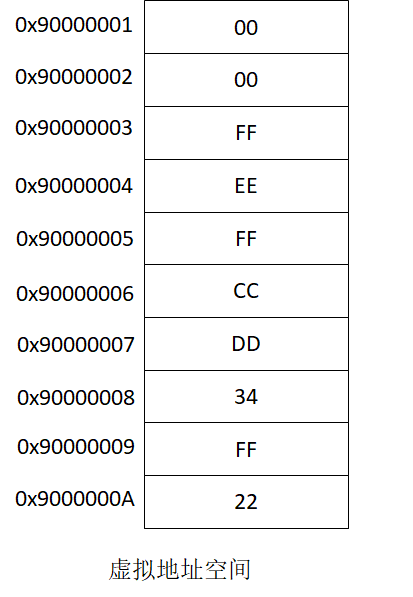
图中用内存地址 0x90000001 ~ 0x9000000A 表示了 10 字节的内存地址空间,每一个地址代表 1 字节的内存。当一个多字节整数存储在内存中时,会涉及到字节序的问题。
我们首先搞清楚两个术语:最高有效位和最低有效位。我们知道,人类习惯的阅读顺序是从左到右,对于一个多位数字来说,经常把它的最左边叫做高位,把它的最右边叫做低位。而在计算机中,对于一个多位数字的描述,也有类似的专业术语,把左边的最高位叫做最高有效位(MSB,most significant bit);把右边最低位叫做最低有效位(LSB,least significant bit)。
下图展示了在内存中存储 16 进制整数 0xAABBCCDD 的不同方式。图中用内存地址 0x90000000 ~ 0x90000003 表示了长度为 4 字节的内存地址空间。
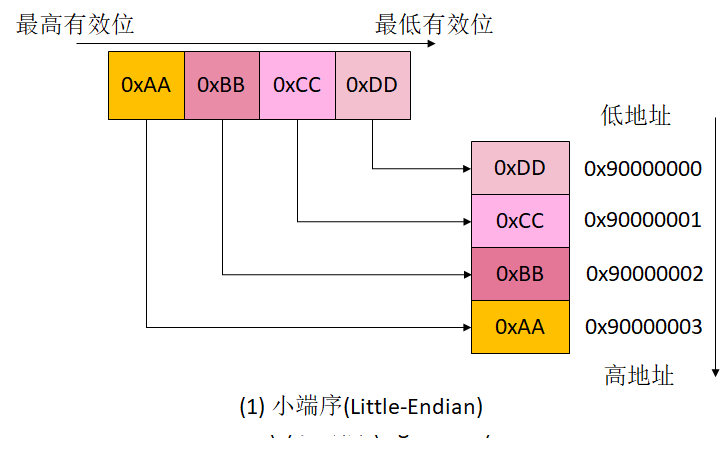
如果按照小端序来存储,0xAABBCCDD 在内存中从低地址到高地址的存储顺序是 0xDD、0xCC、0xBB、0xAA,存储顺序和人类习惯的阅读顺序是相反的。
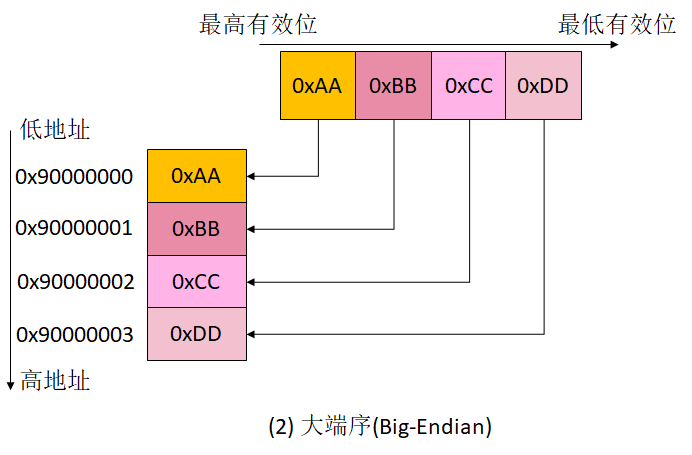
如果按照大端序来存储,0xAABBCCDD 在内存中从低地址到高地址的存储顺序是 0xAA、0xBB、0xCC、0xDD,存储顺序和人类习惯的阅读顺序是相同的。可以类比人类的阅读顺序,更容易理解,也便于记忆。
大小端序是由于 CPU 架构的不同导致的,在历史上 IBM System/360 、Motorola 6800 / 6801、SPARC 是大端序;Intel 架构、ARM 架构是小端序。另外,JAVA 存储多字节整数,也是采用大端序。
通过简单的程序,很容易测试出来我们当前系统所采用的字节序类型。
3. 通过 C 程序测试字节序
通过 C 语言程序来测试字节序非常简单,大致思路如下:
- 定义一个整形变量,然后将 0xAABBCCDD 赋值给该变量。
- 按照从低地址到高地址的顺序打印此变量的内容。
- 将打印结果的顺序和 0xAABBCCDD 的顺序进行对比,观察二者的变化。
代码片段如下:
1 #include <stdio.h>
2
3 void check_endian()
4 {
5 int n = 0xAABBCCDD;
6
7 unsigned char *ptr_n = (unsigned char*)&n;
8
9 for (int i=0; i < 4; ++i){
10 printf("%X\n", *ptr_n++);
11 }
12 }
代码中有两个需要注意的地方:
Tips:
- 需要将 int 型变量 n 的地址赋值给了 unsigned char 型指针变量,如果是赋值给 char 型变量,那么打印结果是:
FFFFFFDD FFFFFFCC FFFFFFBB FFFFFFAA原因是 printf 在打印的时候会将 char 提升为 int,0xAA,0xBB 最高位是 1,所以会当做符号位扩展。如果是 unsigned char,会提升为 unsigned int,符号位扩展是 0。
- 打印结果的时候用 %x 或者 %X 进行格式化输出。
C 语言程序输出结果:
DD
CC
BB
AA
从输出结果可以看出我的系统是以小端序来存储整数的。
4. Java ByteOrder
我们知道 Java 是平台无关的编程语言,它是运行在 Java 虚拟机之上的,而 Java 虚拟机又是运行在 Native 系统上的。那么,如何通过 Java 程序检测系统本身的字节序呢?可以通过 java.nio.ByteOrder 类来测试当前 Native 系统的字节序。调用 ByteOrder 的 nativeOrder 方法,就能返回系统本身的字节序。另外,ByteOrder 还定义了两个 ByteOrder 类型的常量常用:
- ByteOrder.BIG_ENDIAN 表示大端序
- ByteOrder.LITTLE_ENDIAN 表示小端序
检测程序也很简单,如下:
public static void testByteOrder(){
System.out.println("The native byte order: " + ByteOrder.nativeOrder());
}
检测结果如下:
The native byte order: LITTLE_ENDIAN
5. Java ByteBuffer 的字节序
那么 JVM 作为一部独立运行的机器,它的字节序又是如何呢?通过 Java 程序测试字节序的思路和 C 程序的一致,代码片段如下:
public static void checkEndian()
{
int x = 0xAABBCCDD;
ByteBuffer buffer = ByteBuffer.allocate(Integer.BYTES);
buffer.putInt(x);
byte[] lbytes = buffer.array();
for (byte b : lbytes){
System.out.printf("%X\n", b);
}
}
关于 JAVA 程序需要说明的是 JAVA 中没有指针的概念,所以不能通过取地址的方式直接打印内存的值。需要借助 JAVA 的 ByteBuffer,将 int 型数值存储到 ByteBuffer 中,然后将 ByteBuffer 转换成字节数组,通过打印数组的方式来达到我们的目的。引用 ByteBuffer 需要通过语句 import java.nio.ByteBuffer; 导入ByteBuffer 类。
JAVA 测试结果:
AA
BB
CC
DD
从输出结果可以看出 ByteBuffer 默认是以大端序来存储整数的,因为 Java 虚拟机本身采用的就是大端序,ByteBuffer 也要和整个系统保持一致。当然,ByteBuffer 也提供了 ByteBuffer order() 和 ByteBuffer order(ByteOrder bo) 方法,用来获取和设置 ByteBuffer 的字节序。
另外,像一些多字节 Buffer,如 IntBuffer、LongBuffer,它们的字节序规则如下:
- 如果多字节 Buffer 是通过数组(Array)创建的,那么它的字节序和底层系统的字节序一致。
- 如果多字节 Buffer 是通过 ByteBuffer 创建的,那么它的字节序和 ByteBuffer 的字节序一致。
测试程序如下:
public static void checkByteBuffer(){
ByteBuffer byteBuffer = ByteBuffer.allocate(Long.BYTES);
long [] longNumber = new long[]{
0xAA,0xBB,0xCC,0xDD
};
LongBuffer lbAsArray = LongBuffer.wrap(longNumber);
System.out.println("The byte order for LongBuffer wrap array: " + lbAsArray.order());
LongBuffer lbAsByteBuffer = byteBuffer.asLongBuffer();
System.out.println("The byte order for LongBuffer from ByteBuffer: " + lbAsByteBuffer.order());
}
执行结果:
The byte order for LongBuffer wrap array: LITTLE_ENDIAN
The byte order for LongBuffer from ByteBuffer: BIG_ENDIAN
如果在上面的 checkByteBuffer 方法中,首先将对象 byteBuffer 的字节序设置为 ByteOrder.LITTLE_ENDIAN(通过 ByteBuffer 的 order 方法设置),然后再创建 lbAsByteBuffer 对象,那么 lbAsByteBuffer 的字节序该是什么呢?
6. 网络字节序
前面两小节讨论的都是 CPU、Java 虚拟机的字节序,通常叫做主机(host)字节序。在网络编程中,字节流在网络中传输是遵循大端序的,也叫网络字节序。
由于 Java 虚拟机的字节序和网络字节序是一致的,对于 Java 程序员来说,通常不太关心字节序的问题。然而,当 Java 程序和 C 程序进行通信的时候,需要关心字节序的问题。
7. 小结
本文主要是介绍了 CPU 架构带来的多字节数值在内存中存储时的字节序问题,字节序分为大端序和小端序。在计算机网络中,大端序也叫做网络字节序;相应的主机上的存储顺序叫做主机字节序。
在 Java 程序中,由于 Java 程序是在 Java 虚拟机上运行,Java 虚拟机的字节序是大端序。然而 Java 虚拟机运行的 Native 系统的字节序是不确定的,可以通过 java.nio.ByteOrder 的 nativeOrder 方法来确定。
对于 Java 网络编程中广泛应用的 ByteBuffer,则默认是大端序,当然你也可以根据需要设置它的字节序。对于多字节数值 Buffer,比如 IntBuffer、LongBuffer,则需要根据他们创建时所依赖的结构,来判定它们的字节序。
本节内容相对简单,学习起来也会轻松很多,但是非常重要,需要掌握。

 2026 imooc.com All Rights Reserved |
2026 imooc.com All Rights Reserved |