
































































 夜流歌 ·
夜流歌 ·TensorFlow 快速入门示例
因为本课程是以案例为驱动进行框架的应用与讲解,因此我们这一节以一个简单的示例来帮助大家了解 TensorFlow 框架的使用方法以及基本的程序框架与流程。
既然要进行模型的构建与训练,那么数据集便是必不可少的一部分。因为所有的模型都是建立在一定的数据集合之上的。这节课我们便采用一个叫做 fashion_mnist 数据集合进行模型的构建与训练。
1. 什么是 fashion_mnist 数据集合
作为机器学习中最基本的数据集合之一, fashion_mnist 数据集一直是入门者做程序测试的首选的数据集,相比较传统的 mnist 数据集而言,fashion_mnist 数据集更加丰富,能够更好的反映网络模型的构建的效果。
fashion_mnist 数据集合是一个包含 70000 个数据的数据集合,其中60000 条数据为训练集合,10000 条数据为测试集合;每个数据都是 28*28 的灰度图片数据,而每个数据的标签分为 10 个类别。其中的几条数据具体如下图所示(图片来自于 TensorFlow 官方 API 文档)。
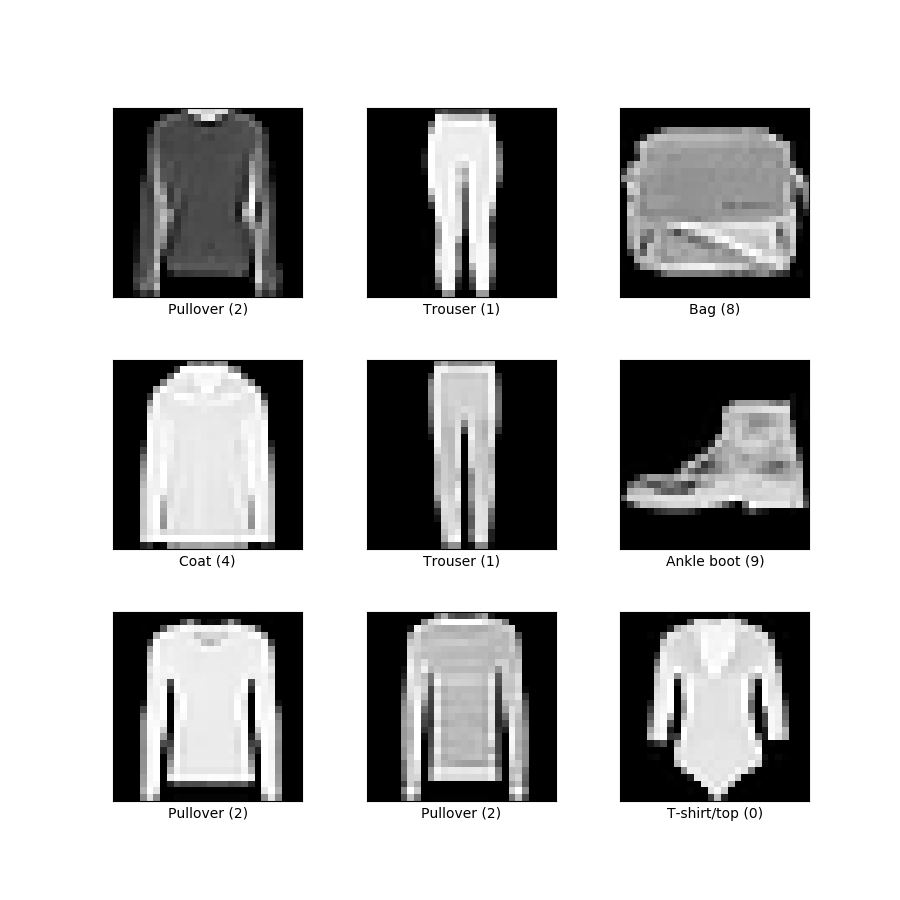
我们要做的就是如何根据输入的图片训练模型,从而使得模型可以根据输入的图片来预测其属于哪一个类别。
fashion_mnist 数据集合的 10 个类别为:
["T-shirt/top", "Trouser", "Pullover", "Dress", "Coat", "Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"]
2. TensorFlow一般程序结构
TensorFlow 一般的程序的结构都是以下的顺序:
- 引入所需要的包
- 加载并预处理数据
- 编写模型结构
- 编译模型或 Build 模型
- 训练模型与保存模型
- 评估模型
在这个简单的示例之中我们不会涉及到模型的保存与加载,我们只是带领大家熟习一下程序的整体结构即可。
具体的程序代码为:
import tensorflow as tf
# 使用内置的数据集合来加载数据
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
# 预处理图片数据,使其归一化
x_train, x_test = x_train / 255.0, x_test / 255.0
# 定义网络结构
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5)
# 评估模型
model.evaluate(x_test, y_test)
接下来让我们仔细地看一下这些代码到底干了什么。
在该程序之中,我们首先使用 tf.keras 中的 datasets 载入了fashion_mnist 数据集合,该函数返回的是两个元组:
- 第一个元组为(训练数据的图片,训练数据的标签)
- 第二个元组为(测试数据的图片,测试数据的标签)
因此我们能够使用两个元组来接收我们要训练的数据集合。
然后我们对图片进行了预处理:
x_train, x_test = x_train / 255.0, x_test / 255.0
在机器学习之中,我们一般将我们的输入数据规范到 [0 ,1] 之间,因为这样会让模型的训练效果更好。又因为图片数据的每个像素都是 [0, 255] 的整数,因此我们可以将所有的图片数据除以 255 ,从而进行归一化。
接下来我们便构建了我们的模型,我们的模型由三层组成:
- Flatten 层,这一层负责将二维的图片数据变成一维的数组数据,比如我们输入的图片数据为 28*28 的二维数组,那么 Flatten 层将会把其变为长度为 784 的一维数组。
- Dense 层,全连接层,这一层的单元数为 10 个,分别对应着我们的 10 个类别标签,激活函数为 “softmax” ,表示它会计算每个类别的可能性,从而取可能性最大的类别作为输出的结果。
然后我们便进行了模型的编译工作,在编译的过程中我们有以下几点需要注意:
- 优化器的选择,优化器代表着如何对网络中的参数进行优化,这里采用的是 “adam” 优化器,也是一种最普遍的优化器。
- 损失函数,损失函数意味着我们如何对“模型判断错误的惩罚”的衡量方式;换句话说,我们可以暂且理解成损失函数表示“模型判断出错的程度”。对于这种分类的问题,我们一般采用的是 “sparse_categorical_crossentropy” 交叉熵来衡量。
- Metrics,表示我们在训练的过程中要记录的数据,在这里我们记录了 “accuracy” ,也就是准确率。
再者我们进行模型的训练,我们使用我们预先加载好的数据进行模型的训练,在这里我们设置训练的循环数( epoch )为 5,表示我们会在数据集上循环 5 次。
最后我们进行模型的评估,我们使用 x_test, y_test 对我们的模型进行相应的评估。
3. 程序的输出
通过运行上面的程序,我们可以得到下面的输出:
Epoch 1/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.4865 - accuracy: 0.8283
Epoch 2/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.3644 - accuracy: 0.8693
Epoch 3/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.3287 - accuracy: 0.8795
Epoch 4/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.3048 - accuracy: 0.8874
Epoch 5/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.2864 - accuracy: 0.8938
313/313 - 0s - loss: 0.3474 - accuracy: 0.8752
[0.3474471867084503, 0.8751999735832214]
由此可以看出,在训练集合上我们可以得到的最高的准确率为 87.52%,在测试集合上面的准确率为 87.519997%。
4. 小结
TesnorFlow 程序的构建主要分为三大部分:数据预处理、模型构建、模型训练。
而在以后的实践过程中我们也总是离不开这个程序顺序,更加深入的定制化无非就是在这三个大的过程中增添一些细节,因此我们大家要谨记这个总体步骤。

 2026 imooc.com All Rights Reserved |
2026 imooc.com All Rights Reserved |