
需求: 在一堆给定的文本文件中统计输出每一个单词出现的总次数
如下图所示为MapReduce统计WordCount的分析图:
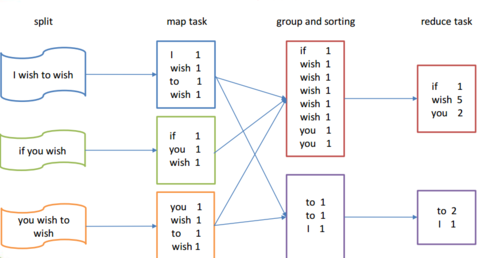
map阶段从文件中读取数据,行号作为key,读取的每行值作为value,将每个key/value对输出给reduce阶段,reduce阶段将map阶段所有执行完的结果进行reduce操作,每个相同的key执行一次reduce方法。
代码如下:
WordCountMapper.java
package com.lxj.wc;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;//Map阶段:输入的行号作为key,每行读取的值作为valuepublic class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ private Text k = new Text(); private IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value,Context context) throws java.io.IOException, java.lang.InterruptedException {
// 1 将每次读入的一行进行分割
String line = value.toString();
// 2 转换成String类型进行分割
String[] words = line.split(" ");
// 3 将每个键值对都写出
for (String word : words) {
String trim = word.trim(); if(!" ".equals(trim)){
k.set(trim); // 4 map阶段将单词拆分,并不合并,所以固定值为1
context.write(k, v);
}
}
}
}WordCountReducer.java
package com.lxj.wc;import java.util.Iterator;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;//Reduce阶段是以Map阶段的输出结果作为Reduce阶段的输入数据public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
//同一个key有且仅只执行一次reduce方法
@Override
protected void reduce(Text text, Iterable<IntWritable> iterable, Context context) throws java.io.IOException, java.lang.InterruptedException {
// 1. 将map阶段同一个key对应的value值求和
int sum = 0;
Iterator<IntWritable> iterator = iterable.iterator(); while(iterator.hasNext()){
sum += iterator.next().get();
} if(!text.toString().trim().equals("")){ //将结果输出
context.write(text, new IntWritable(sum));
}
}
}WordCountDriver.java
package com.lxj.wc;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//驱动类,将map与reduce进行关联
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.获取配置信息
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2.设置加载jar的位置路径,直接传入当前Class对象
job.setJarByClass(WordCountDriver.class);
// 3.设置map和reduce类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4.设置map的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5.设置最终的输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6.设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7.提交
boolean result = job.waitForCompletion(true);
System.exit( result ? 0 : 1);
}
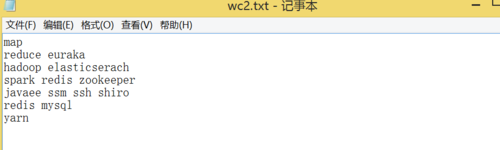
}准备如下文件:

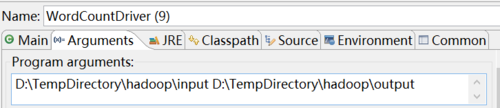
一 本地方法测试结果如下:
Astonished 1 At 1 But 1 Fate 1 He 2 Immediately 1 Many 1 O 1 Phoenix 1 a 1 admired, 1 again 1 ages 1 al 1 amongst 1 an 1 and 5 animals, 1 appeared 1 around 1 at 1 away 1 beasts, 1 beauty, 1 been 2 began 1 being 1 birds 1 both 1 broke 1 compassion, 1 different 1 elasticserach 1 euraka 1 eye 1 flocked 1 friend 1 great 1 had 2 hadoop 1 hard 1 has 2 he 1 him 3 his 1 in 2 into 1 javaee 1 kinds 1 know 1 last 1 look 1 loved 1 loving 1 map 1 mate 1 most 1 mysql 1 neither 1 never 1 nor 1 now 1 of 4 or 1 out 1 passed 1 phoenix 1 pleasure 1 praise. 1 prudent 1 redis 2 reduce 1 seen 1 shiro 1 short 1 sighed 1 since 1 spark 1 ssh 1 ssm 1 stared 1 the 5 them 1 they 2 time, 1 to 2 unhappy 1 upon 1 will 1 wisest 1 with 1 world. 1 yarn 1 zookeeper 1
二 Hadoop集群上运行如下:
首先将项目打成jar包,然后上传到HDFS上面进行分析,并执行以下命令:

执行成功之后查看结果:

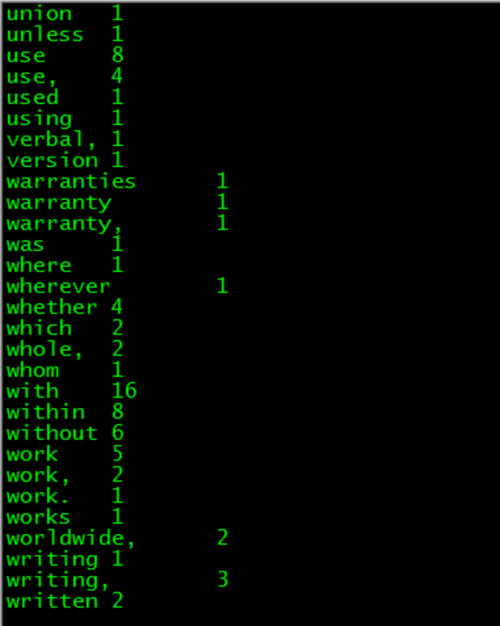
当然也可以直接在web端下载查看:
点击查看更多内容
3人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中



感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦