
转载请注明出处:
在这里介绍一下CoreNLP进行自然语言处理一些知识。
功能列表
工具以及对各种语言的支持如下表(英文和中文支持的最好),分别对应:分词,断句,定词性,词元化,分辨命名实体,语法分析,情感分析,同义词分辨等。
| Annotator | ar | zh | en | fr | de | es |
|---|---|---|---|---|---|---|
| Tokenize / Segment | ||||||
| Sentence Split | ||||||
| Part of Speech | ||||||
| Lemma | ||||||
| Named Entities | ||||||
| Constituency Parsing | ||||||
| Dependency Parsing | ||||||
| Sentiment Analysis | ||||||
| Mention Detection | ||||||
| Coreference | ||||||
| Open IE |
NER
什么是命名实体识别(NER)?
命名实体识别(NER)是自然语言处理(NLP)中的基本任务之一。NLP的一般流程如下:
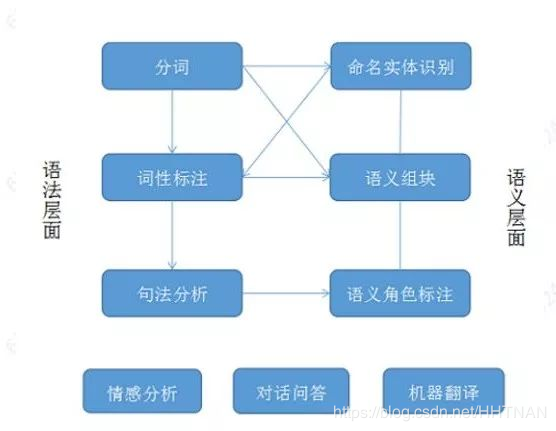
句法分析是NLP任务的核心,NER是句法分析的基础。NER任务用于识别文本中的人名(PER)、地名(LOC)等具有特定意义的实体。非实体用O来表示。我们以人名来举例:
王 B-PER
文 I-PER
和 O
小 B-PER
丽 I-PER
结 O
婚 O
了。 O
(IOB是块标记的一种表示。B-表示开始,I-表示内部,O-表示外部)
首先明确的是NER是个分类任务,具体称为序列标注任务,即文本中不同的实体对应不同的标签,人名-PER,地名-LOC,等等,相似的序列标注任务还有词性标注、语义角色标注。
传统的解决此类问题的方法,包括:
(1) 基于规则的方法。根据语言学上预定义的规则。但是由于语言结构本身的不确定性,规则的制定上难度较大。
(2) 基于统计学的方法。利用统计学找出文本中存在的规律。主要有隐马尔可夫(HMM)、条件随机场(CRF)模型和Viterbi算法。文末会简要介绍比较流行的CRF模型。
(3) 神经网络。因为文本的上下文依赖性,LSTM这种能够存储上下文信息的序列模型是较好的选择(本文侧重于CRF,LSTM的基本知识可参考《深度学习在机器翻译中的应用》)。
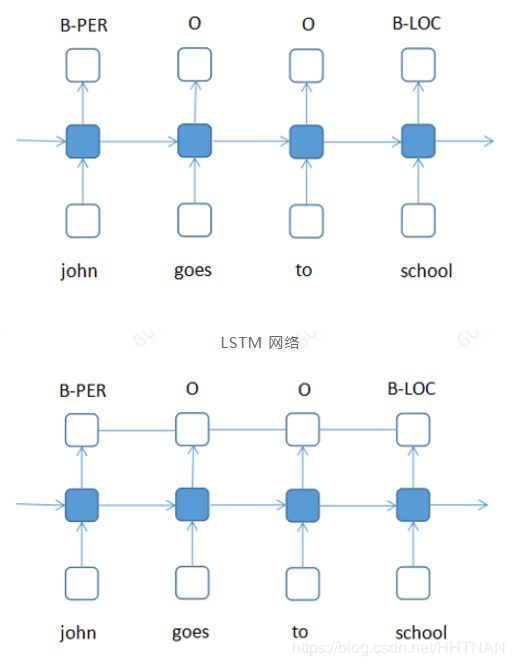
LSTM+CRF模型
语言文本的特殊之处在于其具有一定的结构,主谓宾定状补,状语后置,非限制性定语从句等等。这些结构的存在代表着每个单词的前后是有着一定的词性限制的。比如:
我现在回家 //这是常见的(主+状+谓+宾)结构的句子
我今天家 //这样的文本就不能称为一个句子,少了必要的语法结构
LSTM网络是整体思路同样是先对给定的训练样本进行学习,确定模型中的参数,再利用该模型对测试样本进行预测得到最后的输出。由于测试输出的准确性现阶段达不到100%,这就意味着,肯定存在一部分错误的输出,这些输出里很可能就包含类似于上述第二句话这种不符合语法规则的文本。因此,这就是为什么要将CRF模型引入进来的原因。
**条件随机场(CRF)**是一种统计方法。其用于文本序列标注的优点就是上文所说的对于输出变量可以进行约束,使其符合一定的语法规则。常见的神经网络对训练样本的学习,只考虑训练样本的输入,并不考虑训练样本的输出之间的关系。
附:条件随机场(CRF)原理
要完全搞懂CRF的原理,可以参考李航的《统计学习方法》的第11章。这里作简要说明。CRF的基础是马尔可夫随机场,或者称为概率无向图。
延伸
概率无向图:用无向图表示随机变量的概率分布。
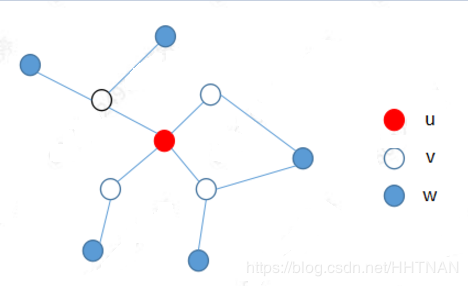
上图就是满足局部马尔可夫性的概率无向图。每个结点都代表着一个随机变量,边代表着随机变量之间的关系。
局部马尔可夫性: P(Yu|Yv)=P(Yu|Yv,Yw)简单理解,因为Yu和Yw之间没有边连接,则在给定随机变量Yv条件下的Yu的概率,跟多加了一个Yw无关。
CRF的理解
CRF可以理解为在给定随机变量X的条件下,随机变量Y的马尔可夫随机场。其中,线性链CRF(一种特殊的CRF)可以用于序列标注问题。CRF模型在训练时,给定训练序列样本集(X,Y),通过极大似然估计、梯度下降等方法确定CRF模型的参数;预测时,给定输入序列X,根据模型,求出P(Y|X)最大的序列y(这里注意,LSTM输出的是一个个独立的类别,CRF输出的是最优的类别序列,也就是CRF全局的优化要更好一些)。
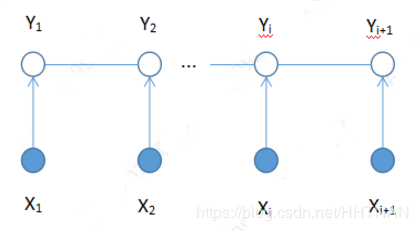
线性链条件随机场(可以比较一下与上面LSTM+CRF网络图的区别与联系)
为何CRF可以表示输出序列内各元素(Y1,Y2,…,Yi,Yi+1)之间的联系?这里就是要联系到马尔可夫性。这也就是为什么CRF的基础是马尔可夫随机场。CRF如何求解P(Y|X),有具体的数学公式,这里就不详细列出了。
首先关于命名主题识别:
#encoding="utf-8"
from stanfordcorenlp import StanfordCoreNLP
import os
if os.path.exists('D:\\stanford_nlp\\stanford-corenlp-full-2018-10-05'):
print("corenlp exists")
else:
print("corenlp not exists")
nlp=StanfordCoreNLP('D:\\stanford_nlp\\stanford-corenlp-full-2018-10-05',lang='zh')
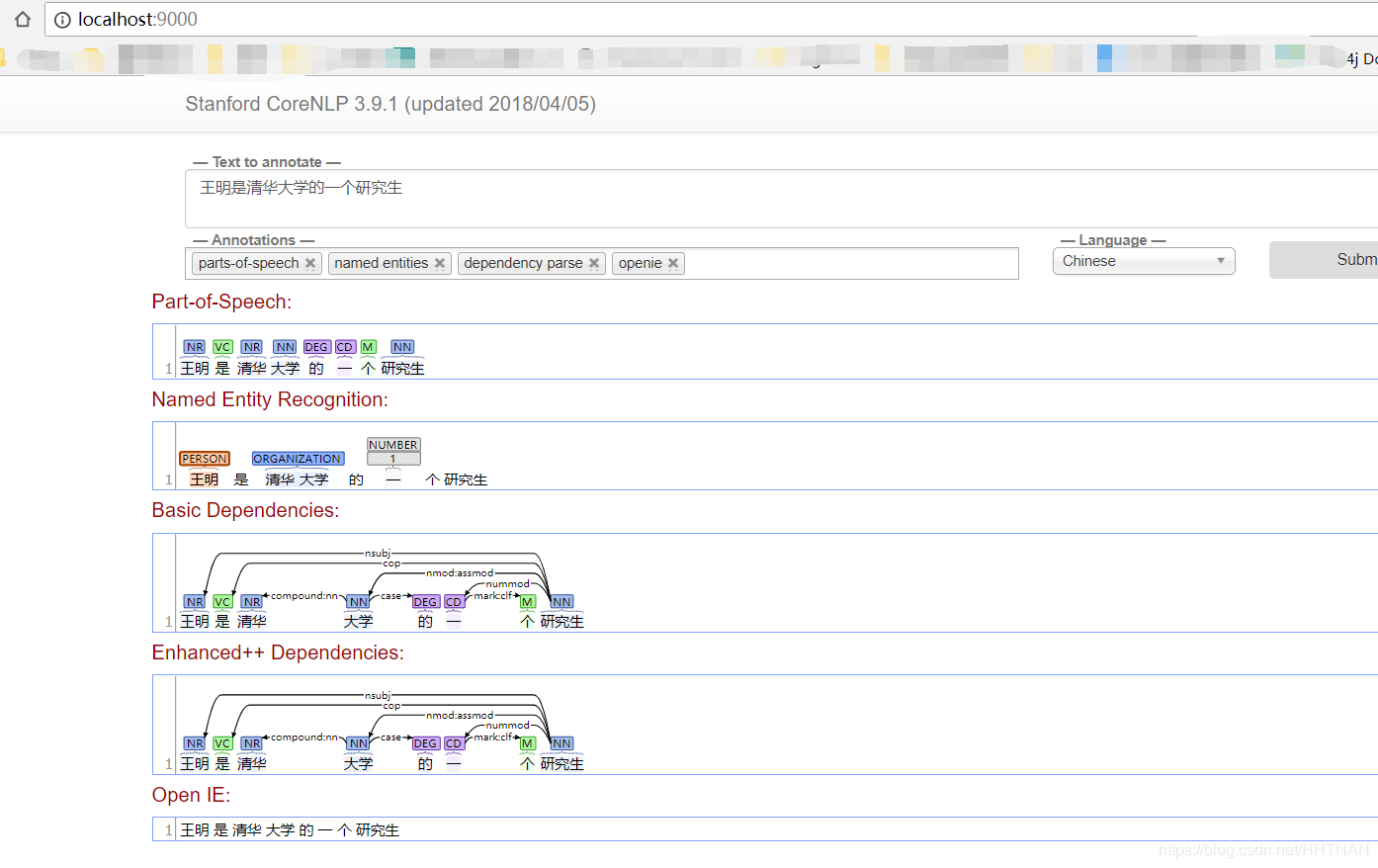
sentence = '王明是清华大学的一个研究生'
#print (nlp.word_tokenize(sentence)) #分词
#print (nlp.pos_tag(sentence)) #词性
print (nlp.ner(sentence)) #NER
#print (nlp.parse(sentence)) #语法分析
#print (nlp.dependency_parse(sentence)) #语法依赖关系
[(‘王明’, ‘PERSON’), (‘是’, ‘O’), (‘清华’, ‘ORGANIZATION’), (‘大学’, ‘ORGANIZATION’), (‘的’, ‘O’), (‘一’, ‘NUMBER’), (‘个’, ‘O’), (‘研究生’, ‘O’)]
如果将命名实体拼接在在一起可以使用
res = nlp.ner(sentence)
tag = 0
name = ''
labels = []
for i in range(len(res)):
if res[i][1] != 'ORGANIZATION':
if tag != 0:
labels.append(name)
name = ''
tag = 0
else:
tag = 1
name += res[i][0]
print(res)
print(labels)
语法解析nlp.parse()
计算机语言学家罗宾森总结了依存语法的四条定理:
- 一个句子中存在一个成分称之为根(root),这个成分不依赖于其它成分; 其它成分直接依存于某一成分;
- 任何一个成分都不能依存与两个或两个以上的成分;
- 如果A成分直接依存于B成分,而C成分在句中位于A和B之间,那么C或者直接依存于B,或者直接依存于A和B之间的某一成分;
- 中心成分左右两面的其它成分相互不发生关系。
使用斯坦福句法分析器做依存句法分析可以输出句子的依存关系,Stanford parser基本上是一个词汇化的概率上下文无关语法分析器,同时也使用了依存分析。
下面是对分析的结果中一些符号的解释:
ROOT:要处理文本的语句
IP:简单从句
NP:名词短语
VP:动词短语
PU:断句符,通常是句号、问号、感叹号等标点符号
LCP:方位词短语
PP:介词短语
CP:由‘的’构成的表示修饰性关系的短语
DNP:由‘的’构成的表示所属关系的短语
ADVP:副词短语
ADJP:形容词短语
DP:限定词短语
QP:量词短语
NN:常用名词
NR:固有名词
NT:时间名词
PN:代词
VV:动词
VC:是
CC:表示连词
VE:有
VA:表语形容词
AS:内容标记(如:了)
VRD:动补复合词
CD: 表示基数词
DT: determiner 表示限定词
EX: existential there 存在句
FW: foreign word 外来词
IN: preposition or conjunction, subordinating 介词或从属连词
JJ: adjective or numeral, ordinal 形容词或序数词
JJR: adjective, comparative 形容词比较级
JJS: adjective, superlative 形容词最高级
LS: list item marker 列表标识
MD: modal auxiliary 情态助动词
PDT: pre-determiner 前位限定词
POS: genitive marker 所有格标记
PRP: pronoun, personal 人称代词
RB: adverb 副词
RBR: adverb, comparative 副词比较级
RBS: adverb, superlative 副词最高级
RP: particle 小品词
SYM: symbol 符号
TO:”to” as preposition or infinitive marker 作为介词或不定式标记
WDT: WH-determiner WH限定词
WP: WH-pronoun WH代词
WP$: WH-pronoun, possessive WH所有格代词
WRB:Wh-adverb WH副词


更多词性参见附录
print (nlp.parse(sentence))
输出:
(ROOT
(IP
(NP (NR 王明))
(VP (VC 是)
(NP
(DNP
(NP (NR 清华) (NN 大学))
(DEG 的))
(QP (CD 一)
(CLP (M 个)))
(NP (NN 研究生))))))
对应图表为
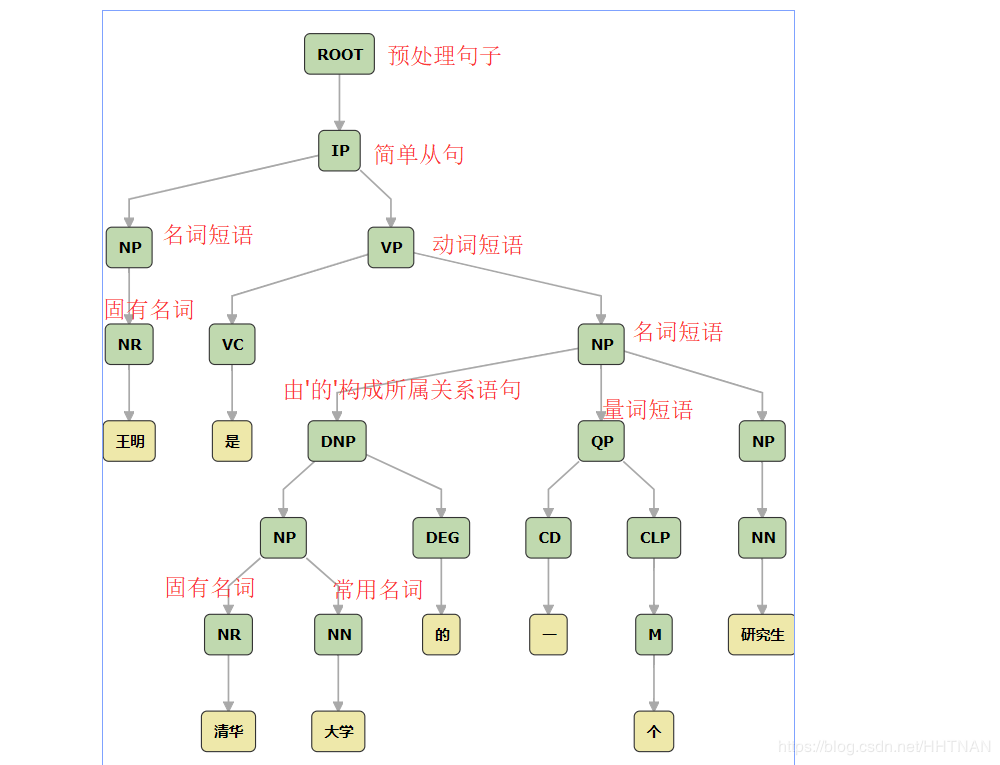
语法依存关系
print (nlp.dependency_parse(sentence))
[(‘ROOT’, 0, 8), (‘nsubj’, 8, 1), (‘cop’, 8, 2), (‘compound:nn’, 4, 3), (‘nmod:assmod’, 8, 4), (‘case’, 4, 5), (‘nummod’, 8, 6), (‘mark:clf’, 6, 7)]
对应如下图
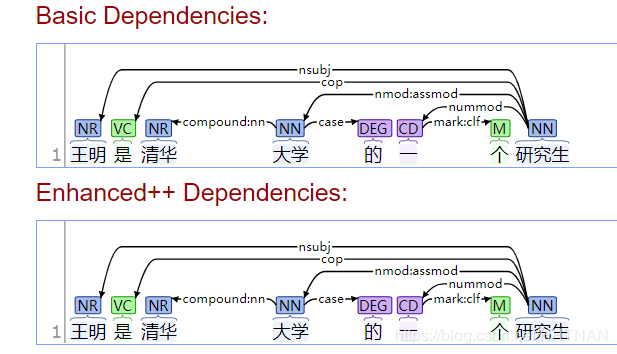
附录:
关系表示
bbrev: abbreviation modifier,缩写
acomp: adjectival complement,形容词的补充;
advcl : adverbial clause modifier,状语从句修饰词
advmod: adverbial modifier状语
agent: agent,代理,一般有by的时候会出现这个
amod: adjectival modifier形容词
appos: appositional modifier,同位词
attr: attributive,属性
aux: auxiliary,非主要动词和助词,如BE,HAVE SHOULD/COULD等到
auxpass: passive auxiliary 被动词
cc: coordination,并列关系,一般取第一个词
ccomp: clausal complement从句补充
complm: complementizer,引导从句的词好重聚中的主要动词
conj : conjunct,连接两个并列的词。
cop: copula。系动词(如be,seem,appear等),(命题主词与谓词间的)连系
csubj : clausal subject,从主关系
csubjpass: clausal passive subject 主从被动关系
dep: dependent依赖关系
det: determiner决定词,如冠词等
dobj : direct object直接宾语
expl: expletive,主要是抓取there
infmod: infinitival modifier,动词不定式
iobj : indirect object,非直接宾语,也就是所以的间接宾语;
mark: marker,主要出现在有“that” or “whether”“because”, “when”,
mwe: multi-word expression,多个词的表示
neg: negation modifier否定词
nn: noun compound modifier名词组合形式
npadvmod: noun phrase as adverbial modifier名词作状语
nsubj : nominal subject,名词主语
nsubjpass: passive nominal subject,被动的名词主语
num: numeric modifier,数值修饰
number: element of compound number,组合数字
parataxis: parataxis: parataxis,并列关系
partmod: participial modifier动词形式的修饰
pcomp: prepositional complement,介词补充
pobj : object of a preposition,介词的宾语
poss: possession modifier,所有形式,所有格,所属
possessive: possessive modifier,这个表示所有者和那个’S的关系
preconj : preconjunct,常常是出现在 “either”, “both”, “neither”的情况下
predet: predeterminer,前缀决定,常常是表示所有
prep: prepositional modifier
prepc: prepositional clausal modifier
prt: phrasal verb particle,动词短语
punct: punctuation,这个很少见,但是保留下来了,结果当中不会出现这个
purpcl : purpose clause modifier,目的从句
quantmod: quantifier phrase modifier,数量短语
rcmod: relative clause modifier相关关系
ref : referent,指示物,指代
rel : relative
root: root,最重要的词,从它开始,根节点
tmod: temporal modifier
xcomp: open clausal complement
xsubj : controlling subject 掌控者
中心语为谓词
subj — 主语
nsubj — 名词性主语(nominal subject) (同步,建设)
top — 主题(topic) (是,建筑)
npsubj — 被动型主语(nominal passive subject),专指由“被”引导的被动句中的主语,一般是谓词语义上的受事 (称作,镍)
csubj — 从句主语(clausal subject),中文不存在
xsubj — x主语,一般是一个主语下面含多个从句 (完善,有些)
中心语为谓词或介词
obj — 宾语
dobj — 直接宾语 (颁布,文件)
iobj — 间接宾语(indirect object),基本不存在
range — 间接宾语为数量词,又称为与格 (成交,元)
pobj — 介词宾语 (根据,要求)
lobj — 时间介词 (来,近年)
中心语为谓词
comp — 补语
ccomp — 从句补语,一般由两个动词构成,中心语引导后一个动词所在的从句(IP) (出现,纳入)
xcomp — x从句补语(xclausal complement),不存在
acomp — 形容词补语(adjectival complement)
tcomp — 时间补语(temporal complement) (遇到,以前)
lccomp — 位置补语(localizer complement) (占,以上)
— 结果补语(resultative complement)
中心语为名词
mod — 修饰语(modifier)
pass — 被动修饰(passive)
tmod — 时间修饰(temporal modifier)
rcmod — 关系从句修饰(relative clause modifier) (问题,遇到)
numod — 数量修饰(numeric modifier) (规定,若干)
ornmod — 序数修饰(numeric modifier)
clf — 类别修饰(classifier modifier) (文件,件)
nmod — 复合名词修饰(noun compound modifier) (浦东,上海) amod — 形容词修饰(adjetive modifier) (情况,新)
advmod — 副词修饰(adverbial modifier) (做到,基本)
vmod — 动词修饰(verb modifier,participle modifier)
prnmod — 插入词修饰(parenthetical modifier)
neg — 不定修饰(negative modifier) (遇到,不)
det — 限定词修饰(determiner modifier) (活动,这些) possm — 所属标记(possessive marker),NP
poss — 所属修饰(possessive modifier),NP
dvpm — DVP标记(dvp marker),DVP (简单,的)
dvpmod — DVP修饰(dvp modifier),DVP (采取,简单)
assm — 关联标记(associative marker),DNP (开发,的)
assmod — 关联修饰(associative modifier),NP|QP (教训,特区) prep — 介词修饰(prepositional modifier) NP|VP|IP(采取,对) clmod — 从句修饰(clause modifier) (因为,开始)
plmod — 介词性地点修饰(prepositional localizer modifier) (在,上) asp — 时态标词(aspect marker) (做到,了)
partmod– 分词修饰(participial modifier) 不存在
etc — 等关系(etc) (办法,等)
中心语为实词
conj — 联合(conjunct)
cop — 系动(copula) 双指助动词????
cc — 连接(coordination),指中心词与连词 (开发,与)
其它
attr — 属性关系 (是,工程)
cordmod– 并列联合动词(coordinated verb compound) (颁布,实行) mmod — 情态动词(modal verb) (得到,能)
ba — 把字关系
tclaus — 时间从句 (以后,积累)
— semantic dependent
cpm — 补语化成分(complementizer),一般指“的”引导的CP (振兴,的)
以上错误之处,还请批评留言指正。
此模型添加自定义词比较麻烦,不建议使用
转载请注明出处:
共同学习,写下你的评论
评论加载中...
作者其他优质文章



