
一、当一个spark任务submit到yarn集群需要经过有几步?
在《spark必知必会的基本概念》解释了yarn集群的运行过程,理解了Resource Manager、Node Manager、Application master这些基本概念,并且它们之间是如何通信的。那么当一个spark任务submit到yarn集群需要经过有几步?
1.1 在client使用spark-submit提交一个spark任务后
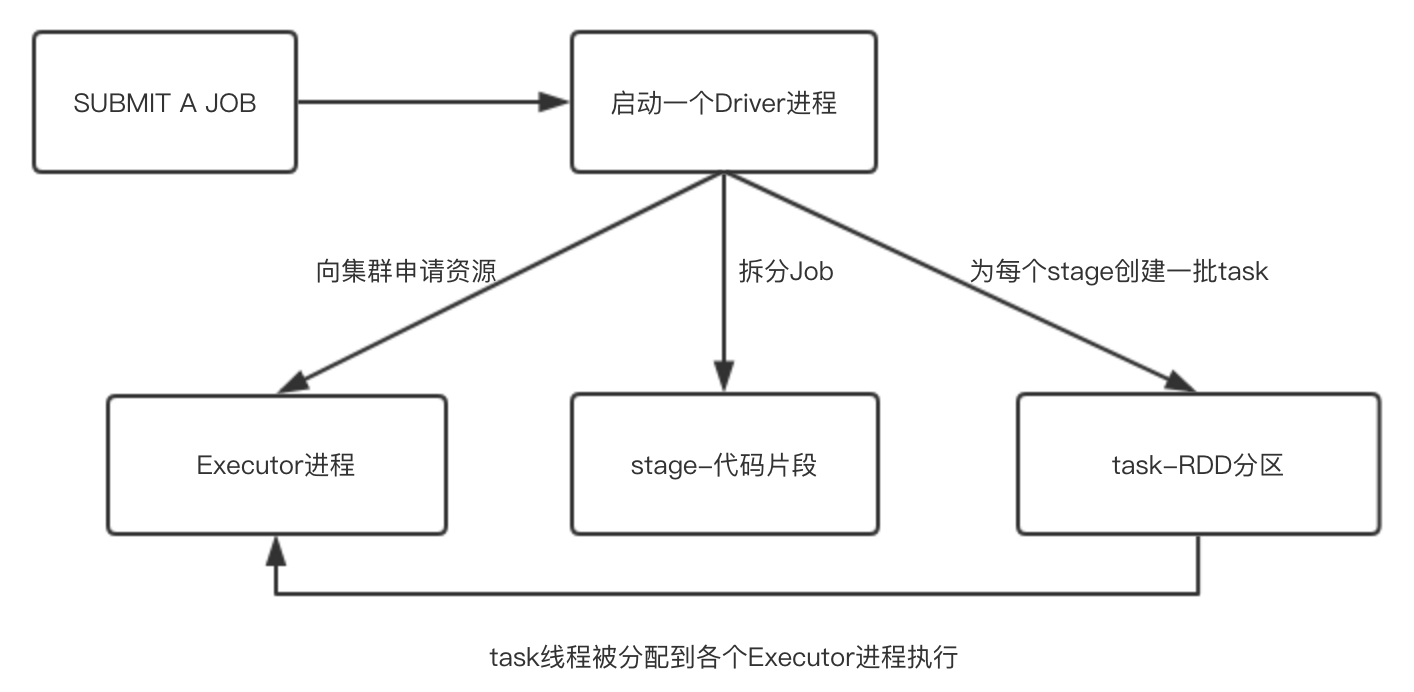
- 首先,每个任务会对应启动一个Driver进程
- 然后,Driver进程为spark任务申请资源:向集群管理器Resource Manager申请运行Spark作业需要使用的资源,主要的资源是Executor进程,Executor进程数量以及所需的CPU core可以通过spark任务设置的资源参数来指定;
- 其次,Driver进程会将Spark任务代码分拆为多个stage:资源申请完毕后,开始调度与执行任务代码,第一步就是将job拆分多个stage;
- 然后,Driver进程为每个stage创建一批task;
- 最后,将这些task分配到各个Executor进程中执行。
1.2 过程很简单,有几个问题值得思考:
- Driver进程在哪里启动的?
- Executor的内存分布?
- stage如何拆分的?(第二节介绍)
1.2.1 Driver进程的启动方式根据任务部署模式的不同而不同:
- local(本地模式):Driver进程直接运行在本地
- yarn-client:Driver运行在本地
- yarn-cluster:Driver运行在集群中(NodeManager)
1.2.2 Executor的内存分布:
- 执行task所需内存,默认20%
- shuffle所需内存,默认20%
- RDD cache或persist持久化所需内存,默认60%
二、spark调优的基本概念
我们在client提交一个spark任务后,可以在spark web ui看到,当我们运行scala代码的时候,后台都发生了什么,通过分析ui的数据可以指导代码性能优化。一段代码至少由一个job来执行(在Jobs页面可查看,如下图),每个job可能由一个或多个stage完成(在Stages页面可查看,或点击job里的Description链接查看),而每个state由多个task线程完成(在Executors页面查看,或点击Stages里的Description链接查看)。通过查看顺序也可以看到job-stage-task的层级关系。
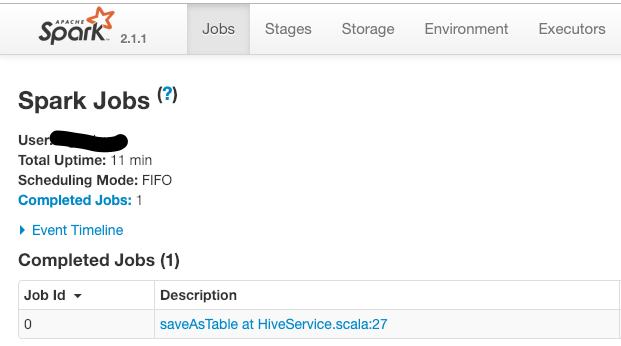
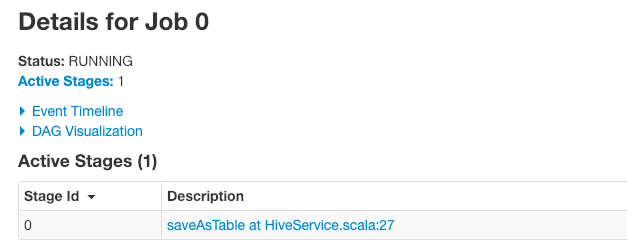
那到底什么是job stage task?
2.1 job
A job (aka action job or active job) is a top-level work item (computation) submitted to DAGScheduler to compute the result of an action (or for Adaptive Query Planning / Adaptive Scheduling).
job指的是在提交的spark任务中一个action,可以在spark ui的Jobs中可以看到Active Jobs为你的action的名称。

2.2 stage
A stage is a physical unit of execution. It is a step in a physical execution plan.
Spark actions are executed through a set of stages, separated by distributed “shuffle” operations.
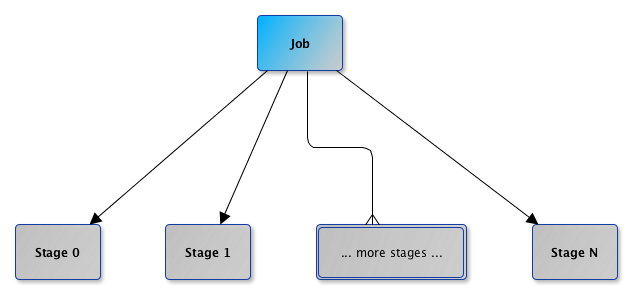
一个job会被拆分为一个或多个stage来执行,每个stage执行一部分代码片段,各个stage会按照执行顺序来执行,而job按照什么规则来划分stage呢?
spark根据shuffle类算子(如join)来进行stage的划分,即在shuffle类算子之前的代码为一个stage,在该shuffle类算子之后的代码则会下一个stage,那么每个stage的执行不需要对整个数据集进行shuffle即可完成。什么是shuffle,后面会讲到。
2.3 task
A stage is a set of parallel tasks — one task per partition (of an RDD that computes partial results of a function executed as part of a Spark job).
Task (aka command) is the smallest individual unit of execution that is launched to compute a RDD partition.
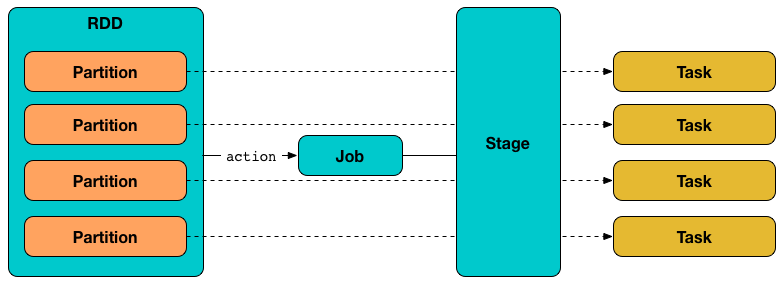
一个stage由一批task线程来执行,task是spark最小的计算单元,每个task执行相同的逻辑计算,但使用不同分区的数据,一个分区一个task。
2.4 shuffle过程
一个shuffle过程是:一个stage执行完后,下一个stage开始执行的每个task会从上一个stage执行的task所在的节点,通过IO获取task需要处理的所有key,然后每个task对相同的key进行算子操作。这个过程被称为shuffle过程。
三、常见参数调优经验
第一节“submit的背后步骤”中我们提到了Driver进程会为spark任务申请资源,合理使用集群资源,是优化spark任务执行性能最基本最直接的方式。资源申请少了,可能导致任务执行非常缓慢甚至出现OOM,无法充分利用集群资源;资源申请多了,当前队列可能无法分配充分资源,同时也影响别的同学任务的执行。
如果你和别人共享一个队列的资源,可以根据集群 ui 的scheduler上目前资源使用情况(比如最大/小的资源数,当前资源数,最大运行任务数,当前运行任务数等)来设置要申请多少资源,申请多少资源可以通过各种常用资源参数来调节。
| 资源参数 | Environment Properties | 参数含义 | 默认值 | 参数意义 | 调优建议 |
|---|---|---|---|---|---|
| –num-executors | spark.executor.instances | spark任务在集群中使用多少个executor | 2个 | 不设置集群会使用默认的少量的Executor进程来执行spark任务,速度缓慢 | 必须,根据spark任务和集群资源队列现有情况设置,官方并没有建议,但美团技术团队的同学建议50-100 |
| –executor-memory | spark.executor.memory | executor的内存大小 | 1G | 对spark任务性能优劣起了决定性作用,常见的JVM OOM与之有关联 | 必须,num-executors * executor-memory=资源队列总内存*(1/3~1/2) |
| –executor-cores | spark.executor.cores | executor的cpu核数 | 1 | 与上一参数决定了一个Executor的资源,cpu核数表示了每个Executor可以并行执行多少个task | 必须,num-executors * executor-cores=资源队列总CPU core数*(1/3~1/2) |
| 无(在spark conf配置) | spark.default.parallelism | RDD默认的分区数,即每个stage默认的task数量 | 有shuffle类算子则取决于RDD最大分区数;无则取决于集群部署模式:Local(本地机器核数);Mesos fine grained(8);other(max(所有executor的cpu核数,2)) | 不设置可能会直接影响spark任务的执行效率 | 必须,num-executors * executor-cores * (2~3) |
markdown表格看不全,截图如下: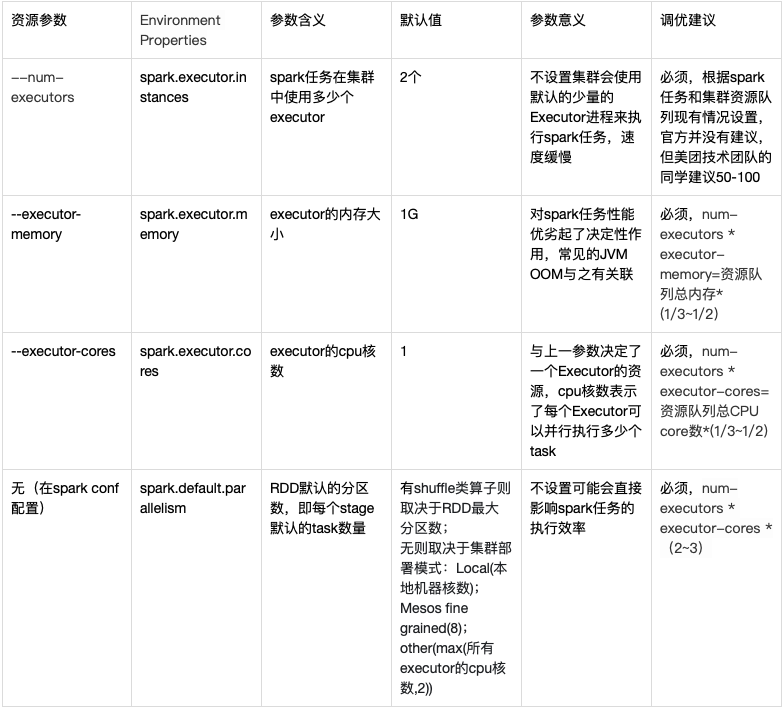
共同学习,写下你的评论
评论加载中...
作者其他优质文章



