
订单数据越来越多(亿级),查询越来越慢,如何处理?分库分表会带来哪些副作用?可能的解决方式有哪些?
目前经常使用的关系型数据库如MySQL、SQL Server等,都是以“行”为单位进行存储,为了快速检索,也都采用了B树或其他索引技术。
从原理上来讲,表中的数据越多,索引树的范围越大,磁盘读取也越多,性能也就越低。
从实践角度来看,一般以百万到千万作为一个表的存储量级,超出该范围之后,性能就会下降,需要采用其他技术手段解决。
首先想到的就是能否将读和写分离,主数据库用于写入,读数据库(多个)用于对外提供查询,通过数据复制的方式将主数据库的数据同步到读库。该架构提升了数据库的读写能力,但对于主数据库的写入能力依然没法扩展。
其次,依据数据库分区的思路,可以将不同的数据分散到不同的库中,每个库存储的数据都不同,这样就可以将单一库的压力分散到多个库中,从而提升整个数据库的服务能力,这就是所说的分库分表技术。
若按照“字段(列)”分区,每个库/表存储不同的的字段,即schema不同,就是“垂直拆分”;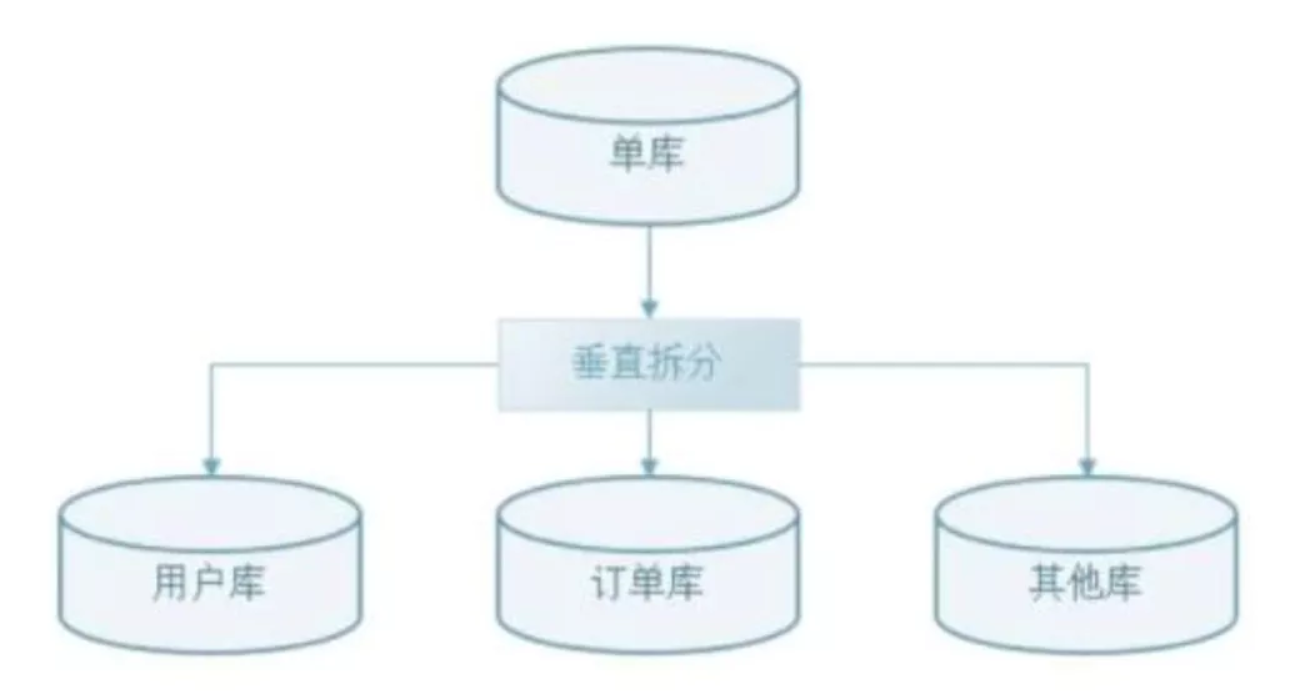
若按“数据记录(行)”分区,每个库/表的schema一致,但存储的数据不同,就是“水平拆分”。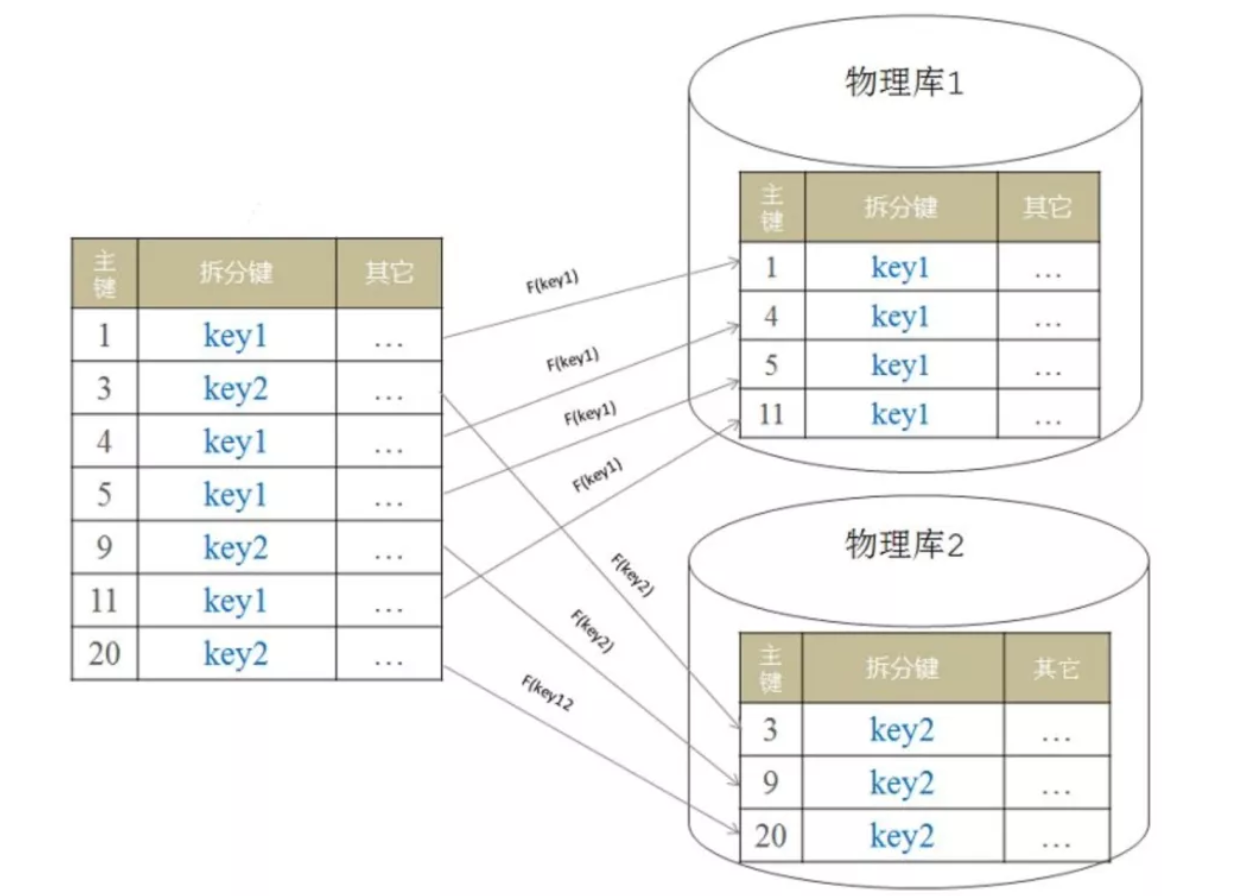
这样做的好处就是解决了数据存储容量的问题,但也带来了诸多弊端。这里以“水平拆分”为例来分析。
- 如何能做到数据的平均拆分,防止某一库压力过大?
系统开发者要结合业务特点来确定分库分表键,比如以userID为分库分表键,采用hash取模的方式将数据散列到不同的库中。
但并不是所有场景都适合用userID作为分库分表键的,若存在“大卖家”,则该userID可能有很多条记录,若简单的按照上述方法进行拆分,则可能打爆其中一个数据库。
一般来说,会将一段时间以前的数据归档(比如某个userID三个月之前的数据),存放到类似HBase这种非关系型数据库中,以此来解决上述问题。
- 分库分表之后就要求每个查询的where子句中必须携带分库分表键,但并非每个查询都能携带分库分表键的。
比如订单库按照订单号hash取模之后存储,此时分库分表键为订单号,那么想查询某位买家所有的订单,查询时就没有了分库分表键,就会出现“全表扫描”的情况。
一般在实践中解决这种问题的方法是建立“异构索引表”,即采用异步机制将原表内的每次一创建或更新,都换一个维度保存一份完整的数据表或索引表,拿空间换时间。
在上面说到,订单库按照订单号hash取模之后存储,同时也按照userID维度进行hash取模,再存储一份数据,那么想要获取某一userID的全部订单时,就将userID作为分库分表键传进去即可,避免了全表扫描。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


