
容器类源码解析系列(二)—— LinkedList 集合源码分析(最新版)
前言
上篇文章 容器类源码解析系列(一) ArrayList 源码分析——基于最新Android9.0源码 对ArrayList集合的源码进行了详细的分析,通过源码分析,使得我们对ArrayList的理解更加深刻,使用起来会更得心应手。本文将要讲解的是LinkedList的底层原理。建议在阅读本文之前,先回顾一下上篇介绍ArrayList的文章,毕竟它们都是开发中的常用的集合类。
要点
- LinkedList底层是通过基于双向链表实现数据持久化存储的。
-
LinkedList可以存储Null值,可以存储重复的值。
-
LinkedList是非线程安全的,在多线程并发环境下,需要加锁来做同步处理,也可通过Collections.synchronizedList(new LinkedList(…))方法,获得一个加过锁的List。
-
LinkedList也是具有fail-fast特性的集合类。关于fail-fast机制,容器类源码解析系列(一) ArrayList 源码分析——基于最新Android9.0源码 这篇文章有详细讲解。
-
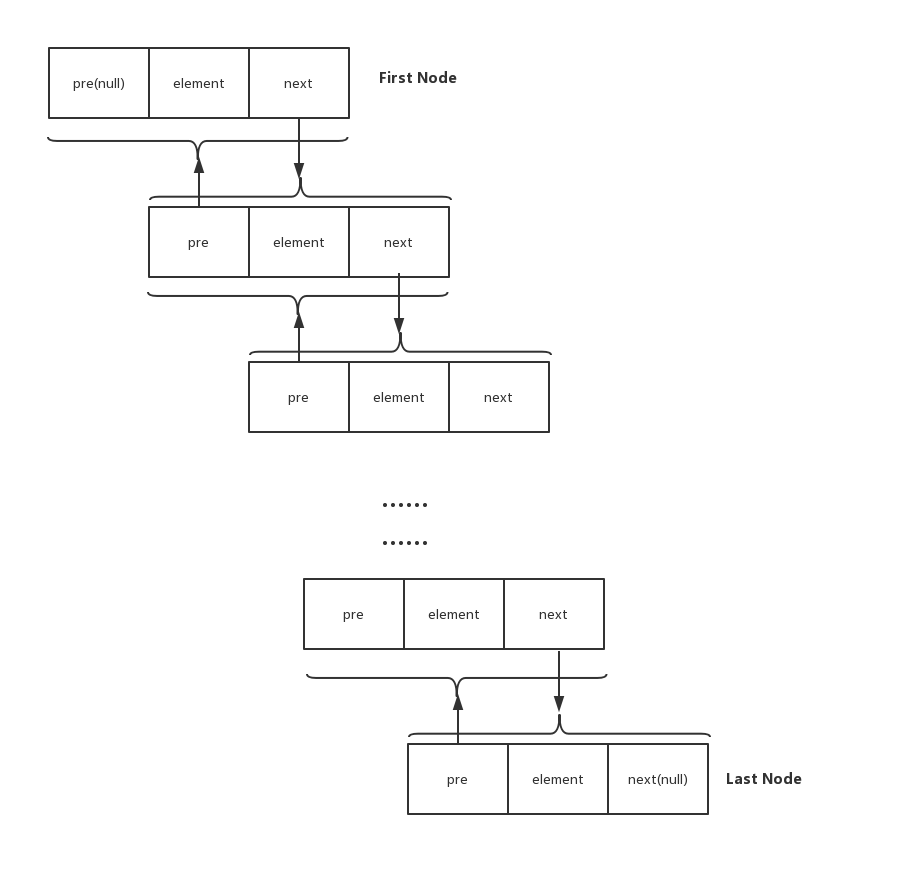
current节点的prev等于null,则该节点是first节点;current节点的next等于null,则该节点是last节点。
Node 节点
分析LinkedList源码,Node这个类,我们必要要知道。Node(节点)是在链表结构中的基本组成单位。我们看一下LinkedList类中,对节点的定义。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}

根据代码再结合图片,很容易知道Node的含义,element表示存储的Value值,pre、next分别指向当前节点的上一个节点和下一个节点。
构造
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
/**
* Constructs an empty list.
*/
public LinkedList() {
}
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
先看上面的成员变量,他们都被transient关键字修饰,表示不会被序列化。size是容器大小;first,last分别表示开始的节点和最后一个节点。我们发现first和last上面还有两段说明。这两段说明,是很有必要注意一下的,因为后面的一些add,remove等常规操作,其中对节点的处理逻辑,是和这两段说明有对应联系的。
Invariant: (first == null && last == null) || (first.prev == null && first.item != null)
这段说明是形容first节点的,如果first是null,那么last节点也应该是null;first.prev等于null,first.item不能等于null。这两个条件至少有一个成立,这是对first节点的定理约束。第一个判断还比较好理解,第二个判断可能不好理解,我们来通过一些例子感受一下。
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
上面的代码是LinkedList源码中把一个value值插入链表尾部的方法,实现逻辑如下:
- 首先把旧的last节点引用指向l;
- 创建新的节点来,pre指向旧的last节点,那么不言而喻,newNode节点就是新的last节点。
- 如果l节点,也就是pre指向的节点等于null,这个newNode同是也被指向first节点,成为first节点。
后面的就不分析了,此时我们看,newNode节点(即first节点),它的pre(l)是等于null的,newNode节点的next也是null,如果此刻e也等于null,则第二个条件**(first.prev == null && first.item != null)** 没有满足,但是不要忘了newNode既是first节点也是last节点,满足了第一个条件**(first == null && last == null)** 所以,定理还是满足的。
第二个不变的定理是指向last节点的Invariant: (first == null && last == null) || (last.next == null && last.item != null) 就不在细说了,这两个不变的定理,在LinkedList的源码实现逻辑中,会表现出现。
LinkedList不像ArrayList默认有10个capacity,linkedlist的size默认是0。所以LinkedList每次add数据都需要创建Node节点。
LinkedList有两个构造方法:
/**
* Constructs an empty list.
*/
public LinkedList() {
}
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
我们主要看第二个构造函数。传入有个list集合,把它放在当前LinkedList的尾部。
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);//(注释1)
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
if (index == size) { //(注释2)
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
主要调用这个方法,表示吧指定集合添加到index对应的节点之前。通过构造函数调用这个方法的话,index是size值的大小,表示,把指定集合添加到当前链表的尾部。
(注释1)会先对index做一个数组越界的异常检测。
(注释2)如果size = index,表示吧传进来的指定集合add到链表尾部。不相等的话,就先通过node(index)拿到对应的节点,然后把pred = succ.prev;表示,之后添加的节点是插在index对应节点之前的地方。
接下来就比较简单了,就是循环创建节点,然后是修改next,prev指向问题。
常规操作
get,set操作
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
/**
* Replaces the element at the specified position in this list with the
* specified element.
*
* @param index index of the element to replace
* @param element element to be stored at the specified position
* @return the element previously at the specified position
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
先看get方法
/**
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
在做一个判断来确定区间后,接着用for循环,遍历查找出目标节点。而ArrayList是通过数组直接拿到的。我们看set方法。
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
和get方法一样,也是要通过node(index)方法,遍历获取目标节点,然后替换目标节点的element的值。所以相较于ArrayList,对于get,set操作,还是ArrayList更方便,效率些。
Add,Remove操作
public boolean add(E e) {
linkLast(e);
return true;
}
添加元素,默认是添加到尾部,linkLast()这个方法前文有介绍,这里就不在重复了,内部逻辑就是new一个Node节点,然后赋给last,再把旧的last指向新的节点的prev。
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
我们着重看linkBefore方法,该方法的第二个参数是调用了之前说的node(index)方法,找到对应index的目标节点。
/**
* Inserts element e before non-null Node succ.
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
总的来说就是new一个节点,然后设置其的prev,next,以及它前一个节点的确定。add操作系列的方法还有addAll、addFirst、等等。addAll方法上面已经介绍过了。它们的逻辑都大差不差,有index要求的,就先遍历确定index对应的节点,然后创建Node节点,再做pre,next这些引用的调整,没有index要求的,就创建节点,默认放在最前面,或者最后面,最后重新设置一下first,last的引用。
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
先遍历找到目标节点,然后重新指定目标节点的prev,next指向关系,把目标节点的prev,element,next值置为null,方便回收。
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
这个方法,是根据index,先找到目标节点,然后在对目标节点进行处理。通过分析ArrayList和LinkedList的插入,删除源码实现,可以得出如下结论。
总结:
有些说法认为LinkedList做插入和删除更快,这种说法其实不是绝对的:
(1)LinkedList做插入、删除的时候,慢在寻址,快在只需要改变前后Node节点的prev,next的引用地址。
(2)ArrayList做插入、删除的时候,慢在数组元素的批量copy,快在寻址。
顺序插入(add)的话,建议选择LinkedList,因为ArrayList有扩容和批量copy的消耗。
随机插入,如果插入点在集合的前面部分靠近头,后面部分靠近尾端的部分,LinkedList更合适。
对于ArrayList,插入的越靠后,即index越大,size-index越小,copy的数量就越小。会更快些。(但是存在扩容的损耗)
删除操作,如果是remove(Object o),删除节点的位置越靠后,效率越差,如果是remove(int index)操作,则删除节点的位置在两端的效率高,中部的效率差。
ArrayList的删除操作效率表现和插入类似,越往后,copy的数量越少,越快些。
上面说的是在大量数据下,数据量少的情况下,其实差别不大。随便用!(ps:ArrayList用的多点)。
队列操作
因为LinkedList实现了Deque接口,所以也就有了队列的操作。比如:
offer(E e)
poll()
peek()
…
等等,比较简单,就不说了,知道有这回事。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


