
1.部分代码实现
import numpy as np
from sklearn import datasets
from math import log
from collections import Counter
iris = datasets.load_iris()
X = iris.data[:,2:]
y = iris.target
from sklearn.tree import DecisionTreeClassifier
# criterion = "entropy" : 基于信息熵的方式
dt_clf = DecisionTreeClassifier(max_depth = 2,criterion = "entropy")
dt_clf.fit(X,y)
#模拟使用信息熵进行划分
#d:维度,value:阈值
#获得划分用的d(维度)和value(阈值)
def try_split(X,y):
#方法:通过多次尝试,使信息熵结果最低
best_entropy = float('inf') #用正无穷的值初始化best_entropy
best_d = -1
best_v = -1
#X的维度数:X.shape[1]
#阈值:d划分后的中间值,所以需要先对X的每一列的值进行排序
for d in range(X.shape[1]): #列扫描
sorted_index = np.argsort(X[:,d])
for i in range(1,len(X)): #行扫描
#防止相邻的两个数相等
if X[sorted_index[i - 1],d] != X[sorted_index[i],d]:
v = (X[sorted_index[i - 1],d] + X[sorted_index[i],d]) / 2
X_left,X_right,y_left,y_right = split(X,y,d,v)
#划分完可以求熵了!!!
e = entropy(y_left) + entropy(y_right) #划分得到的信息熵
if e < best_entropy :
#小于则更新熵和划分方式(d,value)
best_entropy,best_d,best_v = e,d,v
return best_entropy,best_d,best_v
#划分X
def split(X,y,d,value):
# X[:,d] <= value : 布尔类型
# index_a ,index_b :代表的是索引
index_a = (X[:,d] <= value)
#获得小于阈值的索引
index_b = (X[:,d] > value)
#获得大于阈值的索引
return X[index_a],X[index_b],y[index_a],y[index_b]
#计算熵
def entropy(y):
#计算y的各类别所占的比例
counter = Counter(y) #字典类型,collections
res = 0.0
for num in counter.values():
p = num / len(y)
res += -p * log(p) #信息熵
return res
#开始用函数逐步划分:
def tree():
print ("\n *****第一步划分****** \n")
entropy1,d1,v1 = try_split(X,y)
print ("entropy1 = ",entropy1)
print ("d1 = ",d1)
print ("v1 = ",v1)
x1_l,x1_r,y1_l,y1_r = split(X,y,d1,v1) #存储划分结果
print ("\n *****第二步划分****** \n")
entropy2,d2,v2 = try_split(x1_r,y1_r)
print ("entropy2 = ",entropy2)
print ("d2 = ",d2)
print ("v2 = ",v2)
x2_l,x2_r,y2_l,y2_r = split(x1_r,y1_r,d2,v2) #存储划分结果
print ("\n *****第三步划分****** \n")
entropy3,d3,v3 = try_split(x2_r,y2_r)
print ("entropy3 = ",entropy3)
print ("d3 = ",d3)
print ("v3 = ",v3)
#如此循环
#本函数只沿着右边的维度划分
tree()
运行结果
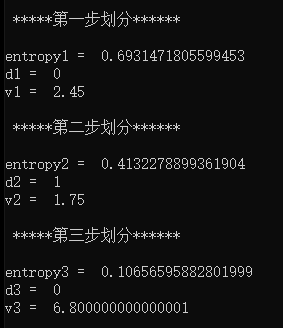
2.完整代码实现
from math import log
import time
import pandas as pd
import numpy as np
def createDataSet():
dataSet =[[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no'],]
labels =['Tree','leaves']
return dataSet,labels
#计算香农熵
def calcShannonEnt(dataSet):
numEntries =len(dataSet)
labelCounts={}
for feaVec in dataSet:
currentLabel =feaVec[-1]
if currentLabel not in labelCounts:
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1
shannonEnt =0.0
for key in labelCounts:
prob =float(labelCounts[key])/numEntries
shannonEnt-=prob*log(prob,2)
return shannonEnt
#去掉已经决策过的属性
def splitDataSet(dataSet,axis,value):
retDataSet = []
for featVec in dataSet:
if featVec[axis]==value:
reducedFeatVec =featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
#根据信息增益算法,选取最优属性
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0])-1 #因为数据集的最后一项是标签
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain =0.0
bestFeature = -1
for i in range(numFeatures):
featList =[example[i] for example in dataSet]
print(featList)
uniqueVals =set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet =splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy +=prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy -newEntropy
if infoGain >bestInfoGain:
bestInfoGain =infoGain
bestFeature =i
return bestFeature
#因为我们递归构建决策树是根据属性的消耗进行计算的,所以可能会存在最后属性用完了,但是分类还没有算完,
#这时候就会采用多数表决的方式计算节点分类
def majorityCnt(classList):
classCount ={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] =0
classCount[vote]+=1
return max(classCount)
def createTree(dataSet,labels):
classList =[example[-1] for example in dataSet]
if classList.count(classList[0]) ==len(classList): #类别相同则停止划分
return classList[0]
if len(dataSet[0])==1:#所有特征已经用完
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel =labels[bestFeat]
myTree ={bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]#为了不改变原始列表的内容复制了一下
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat, value),subLabels)
return myTree
def main():
data,label =createDataSet()
t1 =time.clock()
myTree =createTree(data,label)
t2 =time.clock()
print(myTree)
print('execure time:',t2-t1)
if __name__=='__main__':
main()
运行结果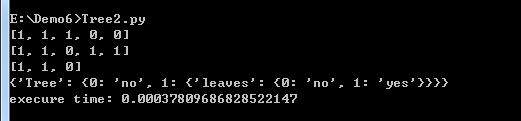
参考教程
点击查看更多内容
1人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦