

在微服务架构的系列文章中,前面已经通过文章分别介绍过了微服务的「服务注册 」、「服务网关 」、「配置中心 」,今天这篇文章我们继续来聊一聊另外一个重要模块:「 监控系统 」。
因为在微服务的架构下,我们对服务进行了拆分,所以用户的每次请求不再是由某一个服务独立完成了,而是变成了多个服务一起配合完成。这种情况下,一旦请求出现异常,我们必须得知道是在哪个服务环节出了故障,就需要对每一个服务,以及各个指标都进行全面的监控。
一、什么是「 监控系统 」?
在微服务架构中,监控系统按照原理和作用大致可以分为三类(并非严格分类,仅从日常使用角度来看):
日志类(Log)
调用链类(Tracing)
度量类(Metrics)
下面来分别对这三种常见的监控模式进行说明:
日志类(Log)
日志类比较常见,我们的框架代码、系统环境、以及业务逻辑中一般都会产出一些日志,这些日志我们通常把它记录后统一收集起来,方便在需要的时候进行查询。
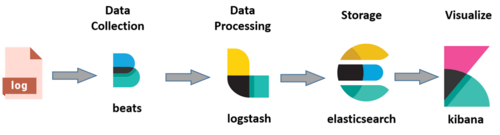
日志类记录的信息一般是一些事件、非结构化的一些文本内容。日志的输出和处理的解决方案比较多,大家熟知的有 ELK Stack 方案(Elasticseach + Logstash + Kibana),如图:
 使用Beats(可选)在每台服务器上安装后,作为日志客户端收集器,然后通过Logstash进行统一的日志收集、解析、过滤等处理,再将数据发送给Elasticsearch中进行存储分析,最后使用Kibana来进行数据的展示。
使用Beats(可选)在每台服务器上安装后,作为日志客户端收集器,然后通过Logstash进行统一的日志收集、解析、过滤等处理,再将数据发送给Elasticsearch中进行存储分析,最后使用Kibana来进行数据的展示。当然还可以升级方案为:
这些方案都比较成熟,搭建起来也比较简单,除了用作监控系统以外,还可以作为日志查询系统使用,非常适用于做分析、以及问题调试使用。调用链类(Tracing)
调用链类监控主要是指记录一个请求的全部流程。一个请求从开始进入,在微服务中调用不同的服务节点后,再返回给客户端,在这个过程中通过调用链参数来追寻全链路行为。通过这个方式可以很方便的知道请求在哪个环节出了故障,系统的瓶颈在哪儿。
这一类的监控一般采用 CAT 工具 来完成,一般在大中型项目较多用到,因为搭建起来有一定的成本。后面会有单独文章来讲解这个调用链监控系统。
度量类(Metrics)
度量类主要采用 时序数据库 的解决方案。它是以事件发生时间以及当前数值的角度来记录的监控信息,是可以聚合运算的,用于查看一些指标数据和指标趋势。所以这类监控主要不是用来查问题的,主要是用来看趋势的。
Metrics一般有5种基本的度量类型:Gauges(度量)、Counters(计数器)、 Histograms(直方图)、 Meters(TPS计算器)、Timers(计时器)。
基于时间序列数据库的监控系统是非常适合做监控告警使用的,所以现在也比较流行这个方案,如果我们要搭建一套新的监控系统,我也建议参考这类方案进行。
因此本文接下来也会重点以时间序列数据库的监控系统为主角来描述。
 使用Beats(可选)在每台服务器上安装后,作为日志客户端收集器,然后通过Logstash进行统一的日志收集、解析、过滤等处理,再将数据发送给Elasticsearch中进行存储分析,最后使用Kibana来进行数据的展示。
使用Beats(可选)在每台服务器上安装后,作为日志客户端收集器,然后通过Logstash进行统一的日志收集、解析、过滤等处理,再将数据发送给Elasticsearch中进行存储分析,最后使用Kibana来进行数据的展示。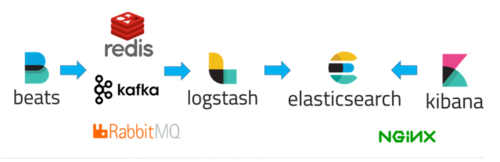 这些方案都比较成熟,搭建起来也比较简单,除了用作监控系统以外,还可以作为日志查询系统使用,非常适用于做分析、以及问题调试使用。
这些方案都比较成熟,搭建起来也比较简单,除了用作监控系统以外,还可以作为日志查询系统使用,非常适用于做分析、以及问题调试使用。二、「 监控系统 」关注的对象和指标都是什么?
一般我们做「监控系统」都是需要做分层式监控的,也就是说将我们要监控的对象进行分层,一般主要分为:
系统层:系统层主要是指CPU、磁盘、内存、网络等服务器层面的监控,这些一般也是运维同学比较关注的对象。
应用层:应用层指的是服务角度的监控,比如接口、框架、某个服务的健康状态等,一般是服务开发或框架开发人员关注的对象。
用户层:这一层主要是与用户、与业务相关的一些监控,属于功能层面的,大多数是项目经理或产品经理会比较关注的对象。
知道了监控的分层后,我们再来看一下监控的指标一般有哪些:
延迟时间:主要是响应一个请求所消耗的延迟,比如某接口的HTTP请求平均响应时间为100ms。
请求量:是指系统的容量吞吐能力,例如每秒处理多少次请求(QPS)作为指标。
错误率:主要是用来监控错误发生的比例,比如将某接口一段时间内调用时失败的比例作为指标。
三、基于时序数据库的「 监控系统 」有哪些?
下面介绍几款目前业内比较流行的基于时间序列数据库的开源监控方案:
Prometheus
Promethes是一款2012年开源的监控框架,其本质是时间序列数据库,由Google前员工所开发。
Promethes采用拉的模式(Pull)从应用中拉取数据,并还支持 Alert 模块可以实现监控预警。它的性能非常强劲,单机可以消费百万级时间序列。
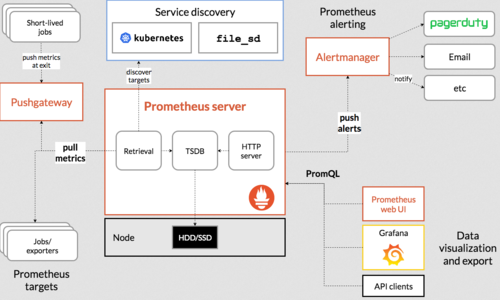
架构如下:
从看图的左下角可以看到,Prometheus 可以通过在应用里进行埋点后Pull到 Prometheus Server里,如果应用不支持埋点,也可以采用exporter方式进行数据采集。从图的左上角可以看到,对于一些定时任务模块,因为是周期性运行的,所以采用拉的方式无法获取数据,那么Prometheus 也提供了一种推数据的方式,但是并不是推送到Prometheus Server中,而是中间搭建一个 Pushgateway,定时任务模块将metrics信息推送到这个Pushgateway中,然后Prometheus Server再依然采用拉的方式从Pushgateway中获取数据。
需要拉取的数据既可以采用静态方式配置在Prometheus Server中,也可以采用服务发现的方式(即图的中间上面的Service discovery所示)。
PromQL:是Prometheus自带的查询语法,通过编写PromQL语句可以查询Prometheus里面的数据。
Alertmanager:是用于数据的预警模块,支持通过多种方式去发送预警。
WebUI:是用来展示数据和图形的,但是一般大多数是与Grafana结合,采用Grafana来展示。
OpenTSDB
OpenTSDB是在2010年开源的一款分布式时序数据库,当然其主要用于监控方案中。
OpenTSDB采用的是Hbase的分布式存储,它获取数据的模式与Prometheus不同,它采用的是推模式(Push)。
在展示层,OpenTSDB自带有WebUI视图,也可以与Grafana很好的集成,提供丰富的展示界面。
但OpenTSDB并没有自带预警模块,需要自己去开发或者与第三方组件结合使用。
可以通过下图来了解一下OpenTSDB的架构:
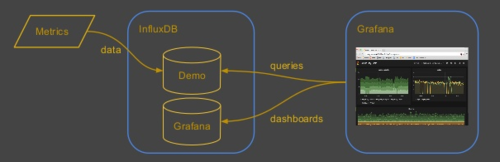
InfluxDB
InfluxDB是在2013年开源的一款时序数据库,在这里我们主要还是用于做监控系统方案。它收集数据也是采用推模式(Push)。在展示层,InfluxDB也是自带WebUI,也可以与Grafana集成。
 从看图的左下角可以看到,Prometheus 可以通过在应用里进行埋点后Pull到 Prometheus Server里,如果应用不支持埋点,也可以采用exporter方式进行数据采集。
从看图的左下角可以看到,Prometheus 可以通过在应用里进行埋点后Pull到 Prometheus Server里,如果应用不支持埋点,也可以采用exporter方式进行数据采集。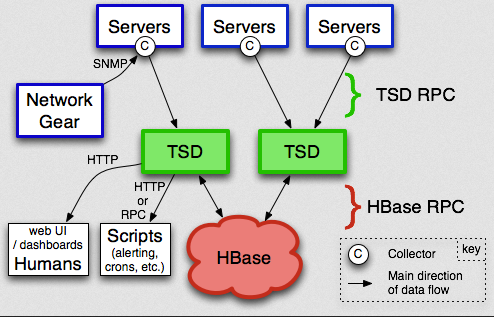
以上,就是对微服务架构中「 监控系统」的一些思考。
码字不易啊,喜欢的话不妨转发朋友,或点击文章右下角的“在看”吧。?
本文原创发布于「 不止思考 」,欢迎关注。涉及 思维认知、个人成长、架构、大数据、Web技术 等。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



