
一.Tensorflow介绍:
谷歌官网提供的视频
1.Tensorflow输出Hello World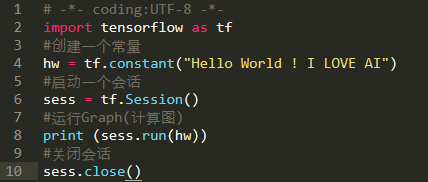
运行效果: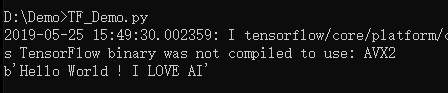
2.Tensorflow官方教程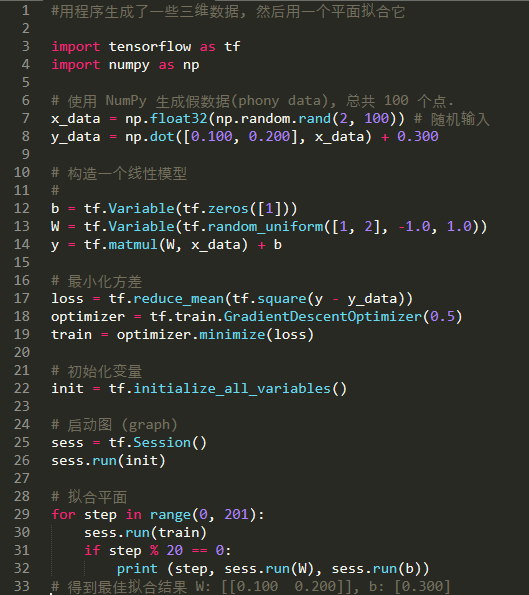
运行效果: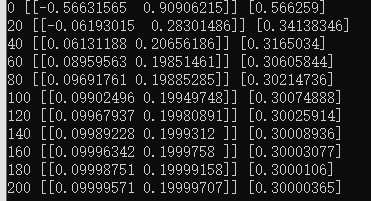
二,Tensorflow基本结构
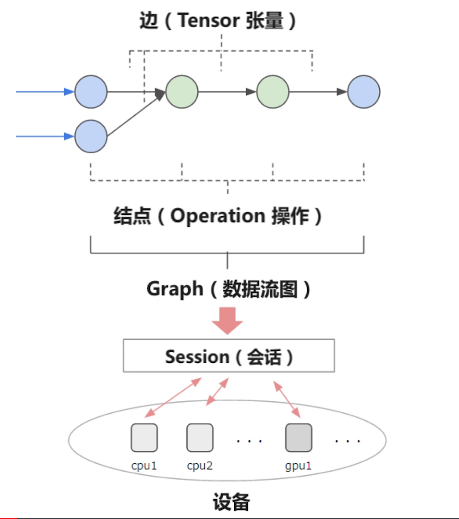
关于张量:
值不能改变的Tensor: tf.constant
值可以改变的Tensor:tf.Variable
占位符:tf.placeholder
稀疏张量:tf.SparseTensor
创建constant不需要初始化,创建Variable需要初始化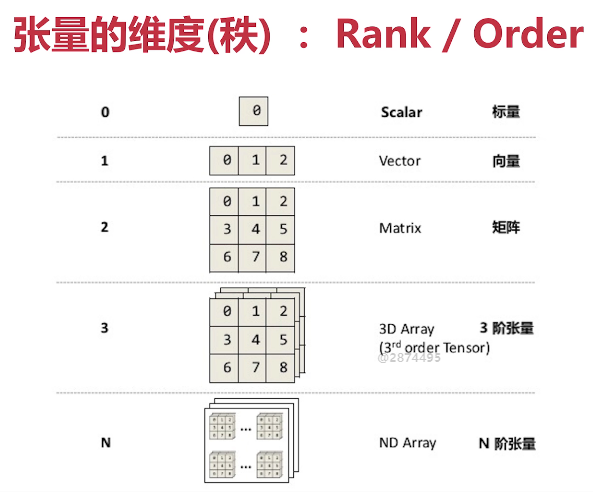
Placeholder实例: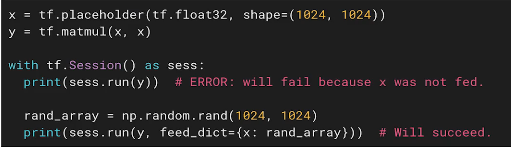
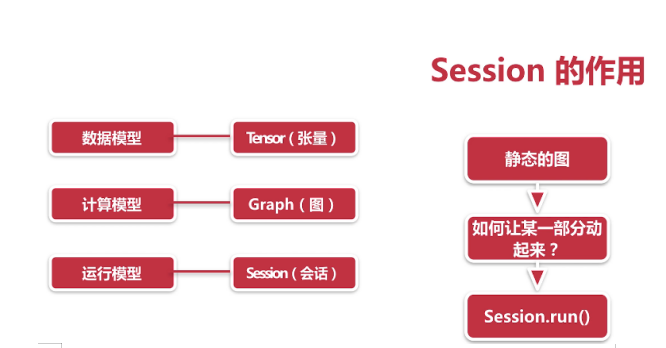
Tensorflow程序流程:
1.定义算法的计算图(Graph)结构(由Tensor,Operation构成)
2.使用会话(Session)执行计算
三,Tensorboard可视化
1.用TensorFlow保存图的信息到日志中
tf.summary.FileWriter(“日志保存路径”,sess.graph)
2.用TensorBoard读取并展示日志
tensorboard --logdir = 日志所在路径
完整代码:
# -*- coding: UTF-8 -*-
import tensorflow as tf
#构造图 (Graph) 的结构
#用一个线性方程的例子 y = W * x + b
W = tf.Variable(2.0,dtype = tf.float32,name = "Weight")
b = tf.Variable(1.0,dtype = tf.float32,name = "Bias")
x = tf.placeholder(dtype = tf.float32,name = "Input")
#输出的命名空间
with tf.name_scope("Output"):
y = W * x + b
#定义保存日志的路径
path = "./log"
#创建用于初始化所有变量(Variable)的操作
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init) #初始化变量
writer = tf.summary.FileWriter(path,sess.graph)
result = sess.run(y,{x:3.0}) #tf.placeholder用Python中的字典来赋值
print ("y = %s" % result)

log文件夹:
Tensorboard读取日志:
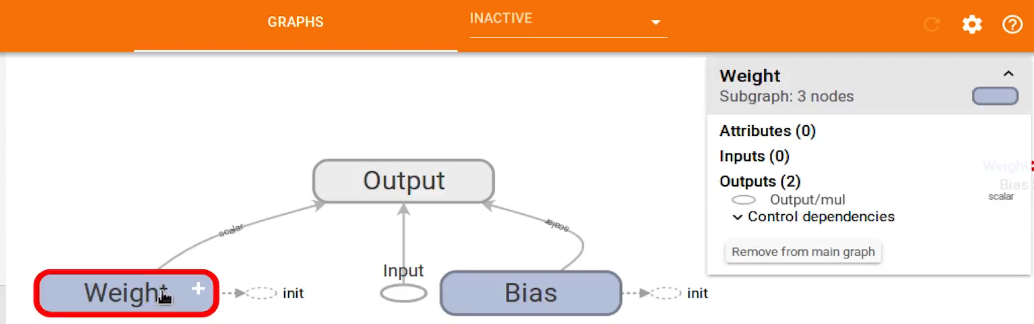
小节——Tensorflow可以用到的Operations操作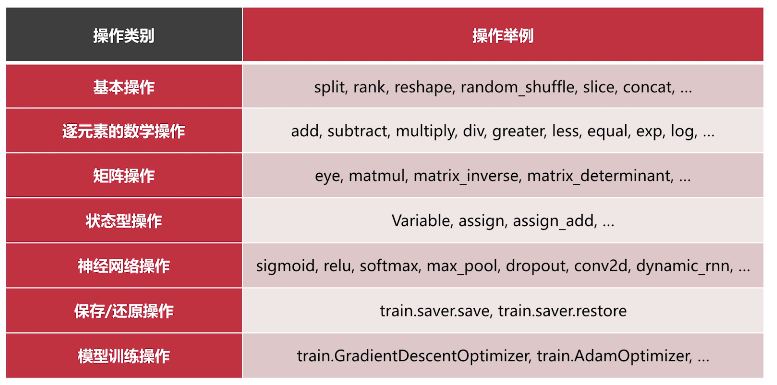
四.Tensorflow实战代码:
实例1:基于Tensorflow的线性回归
完整代码:
# -*- coding: UTF-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
#构建数据
points_num = 100
vectors = []
#用Numpy的正态随机分布函数生成 100 个点
#对应的线性方程 : y = 0.1 * x + 0.2
#权重 : 0.1 ,偏差 : 0.2
for i in range(points_num):
x1 = np.random.normal(0.0,0.66)
y1 = 0.1 * x1 + 0.2 + np.random.normal(0.0,0.04)
vectors.append([x1,y1])
#真实的点的 x 坐标
x_data = [v[0] for v in vectors]
#真实的点的 y 坐标
y_data = [v[1] for v in vectors]
#Figure1 : 展示100个随机数据点
plt.plot(x_data,y_data,'g*',label ="Original Data")
plt.title("Linear Regression using Gradient Descent")
plt.legend()
plt.show()
#构建线性回归模型
#初始化Weight
W = tf.Variable(tf.random_uniform([1],-1.0,1.0))
#初始化Bias
b = tf.Variable(tf.zeros([1]))
#y:预测值
y = W * x_data + b
#定义损失(代价)函数
# 对 Tensor 的所有维度都计算 :
# Sum((y - y_data) ^ 2) / N
loss = tf.reduce_mean(tf.square(y - y_data))
#用梯度下降的优化器来优化loss function,学习率:0.5
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
#创建会话
sess = tf.Session()
#初始化变量
init = tf.global_variables_initializer()
sess.run(init)
#训练 20 step
for step in range(20):
#每一步都优化
sess.run(train)
#打印每一步的loss,权重和偏差
print(("Step= %d , Loss= %f, [Weight= %f | Bias= %f]") \
% (step,sess.run(loss),sess.run(W),sess.run(b)))
#Figure2 : 绘制出所有的点以及最佳拟合直线
plt.plot(x_data,y_data,'r*',label ="Original Data")
plt.title("Linear Regression using Gradient Descent")
plt.plot(x_data,sess.run(W) * x_data + sess.run(b),label = "拟合的直线")
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
#关闭会话
sess.close()
Figure1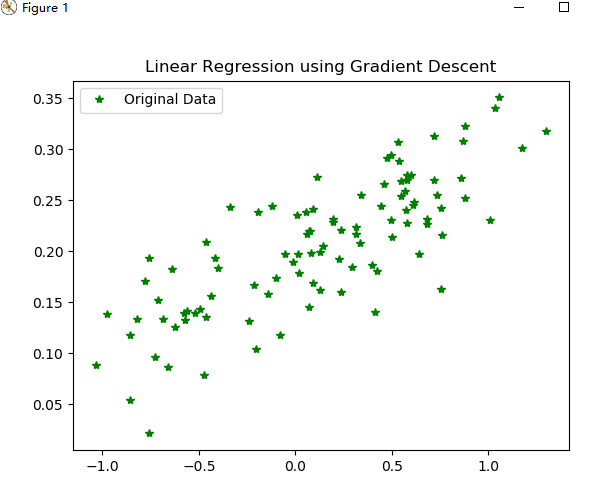
Figure2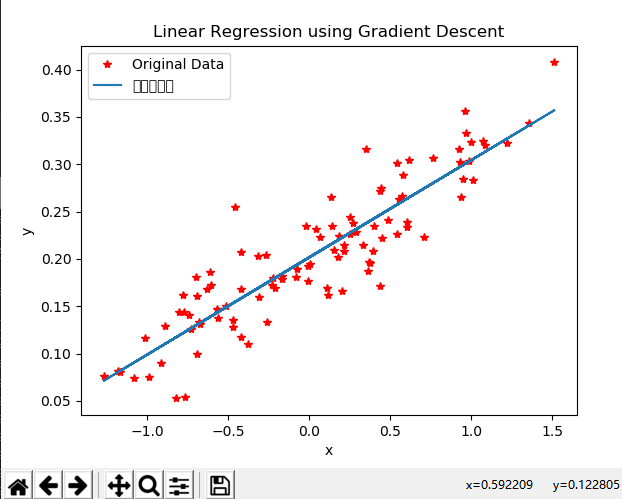
运行结果: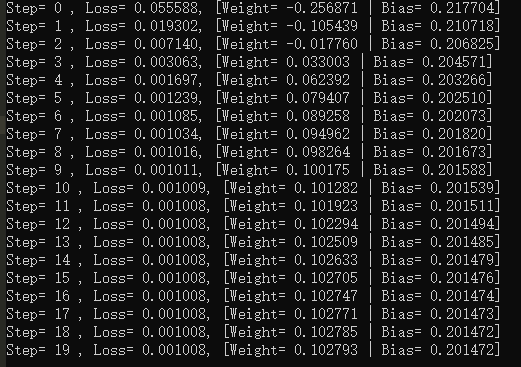
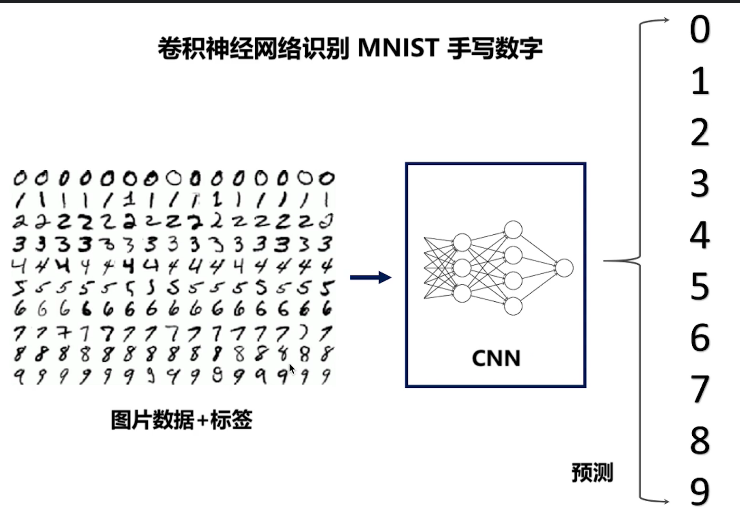
实例二,实现CNN卷积神经网络
手写数字识别的CNN流程: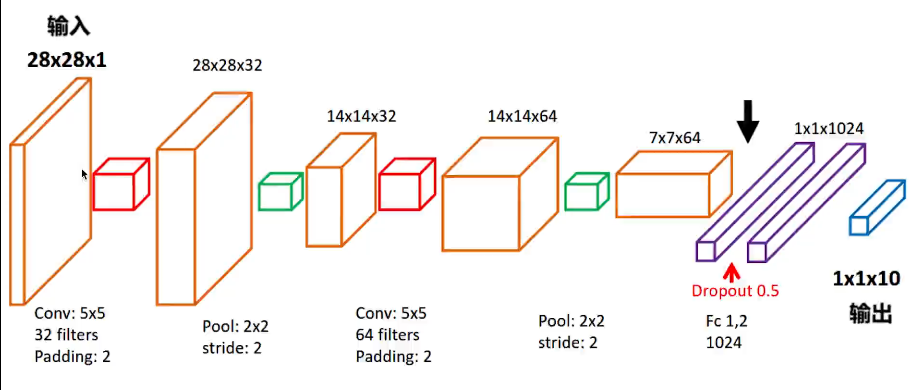
效果图:
Padding参数:
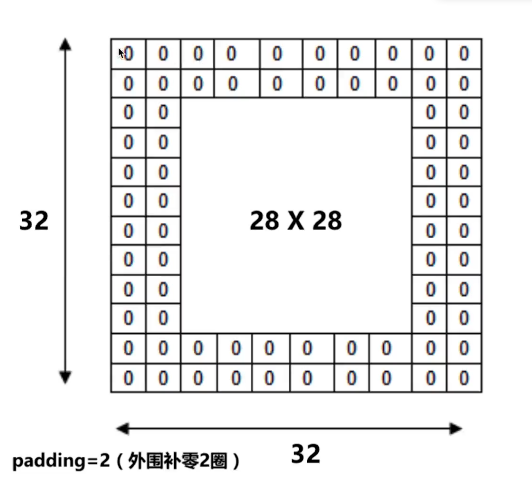
完整代码:
# -*- coding: UTF-8 -*-
import numpy as np
import tensorflow as tf
#下载并载入MNIST 手写数字库
#55000 * 28 * 28
#总共55000张,28* 28 的训练图像
from tensorflow.examples.tutorials.mnist import input_data
#接收数据,并以文件名mnist_data存储
#用独热编码存储数字"1"~"10"
mnist = input_data.read_data_sets('mnist_data',one_hot = True)
#None 表示Tensor的第一个维度可以是任何长度
#输入input_x : 28 * 28 像素
#images表示输入的图像,28X28的灰度图,1表示只有1个图像
input_x = tf.placeholder(tf.float32,[None,28 * 28]) / 255.
output_y = tf.placeholder(tf.int32,[None,10])
#将输入input_x改变形状
input_x_images = tf.reshape(input_x,[-1,28,28,1])
#从Test(测试)数据集里选取3000个书写数字的图片和对应标签
test_x = mnist.test.images[:3000]
test_y = mnist.test.labels[:3000]
#构建卷积神经网络
# 1.第一层卷积:
#28 * 28 * 1 --> 28 * 28 * 32
conv1 = tf.layers.conv2d(
inputs = input_x_images,
filters = 32, #32个过滤器(卷积核),输出的深度:depth = 32
kernel_size = [5,5], #过滤器(卷积核)大小
strides = 1, #采样步长
padding = 'same', #same表示输出的大小不变,因此需要在外围补两圈0
activation = tf.nn.relu #激活函数
)
# 2.第一层池化(亚采样)
# 28 * 28 * 32 --> 14 * 14 * 32
pool1 = tf.layers.max_pooling2d(
inputs = conv1,
pool_size = [2,2], #过滤器大小
strides = 2, #步长为2
#32个卷积层,每层对应一个过滤器
#所以过滤器的大小为2
)
# 3.第二层卷积:
# 14 * 14 * 32 --> 14 * 14 * 64
conv2 = tf.layers.conv2d(
inputs = pool1,
filters = 64, #64个过滤器(卷积核),输出的深度:depth = 64
kernel_size = [5,5], #过滤器(卷积核)大小
strides = 1, #采样步长
padding = 'same', #same表示输出的大小不变,因此需要在外围补两圈0
activation = tf.nn.relu #激活函数
)
# 4.第二层池化(亚采样)
# 14 * 14 * 64 --> 7 * 7 * 64
pool2 = tf.layers.max_pooling2d(
inputs = conv2,
pool_size = [2,2], #过滤器大小
strides = 2, #步长为2
)
# 5.平坦化(flatten)
flat = tf.reshape(pool2,[-1,7 * 7 * 64])
# 6.1024个神经元的全连接层:
dense = tf.layers.dense(
inputs = flat,
units = 1024,
activation = tf.nn.relu
)
# 7.丢弃一些特征(Dropout)
#丢弃 50%,rate = 0.5
dropout = tf.layers.dropout(
inputs = dense,
rate = 0.5
)
# 8.10个神经元的全连接层
#这里不需要激活函数线性化
#输出的形状 : 1 * 1 * 10
logits = tf.layers.dense(
inputs = dropout,
units = 10
)
# 9.计算误差 (Cross entropy)
#再用Softmax计算误差百分比
loss = tf.losses.softmax_cross_entropy(
onehot_labels = output_y,
)
# 10.用优化器最小化误差(Adam),学习率 : 0.001
train_op = tf.train.AdamOptimizer(
learning_rate = 0.001
).minimize(loss)
# 11.计算预测值和实际标签的匹配程度
# 返回(accuracy,update_op):局部变量,初始化全局变量时容易漏
accuracy = tf.metrics.accuracy(
labels = tf.argmax(output_y,axis = 1),
predictions = tf.argmax(logits,axis = 1)
)[1]
sess = tf.Session()
#初始化变量:
init = tf.group(tf.global_variables_initializer(),tf.local_variables_initializer())
sess.run(init)
#训练神经网络
for i in range(20000):
batch = mnist.train.next_batch(50) #从训练集里面取50个样本
train_loss,train_op = sess.run([loss,train_op],
{input_x:batch[0],output_y:batch[1]}
#batch[0]:图片,batch[1]:标签
)
if i % 100 == 0:
test_accuracy = sess.run(accuracy,{input_x:test_x,output_y:test_y})
print (("Step= %d,Train_loss= %.4f,[Test_accuracy= %.2f]") \
% (i,train_loss,test_accuracy))
#测试: 打印20个预测值 和真实值 ,对比
test_output = sess.run(logits,{input_x:test_x[:20]})
y_pre = np.argmax(test_output,1)
y_true = np.argmax(test_y[:20],1)
print ("预测的数字",y_pre)
print ("真实的数字",y_true)
运行结果: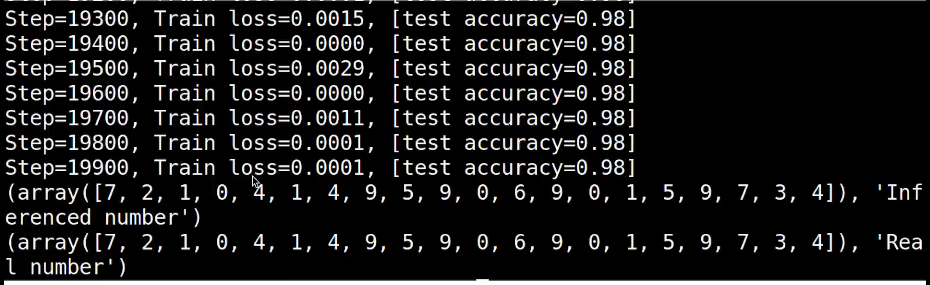
点击查看更多内容
1人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦