
栗子 安妮 发自 凹非寺
量子位 出品
不得了,以生成逼真假照片出名、被称作“史上最佳GAN”的BigGAN,被“本家”踢馆了。
挑战者同样来自Google DeepMind,其新鲜出炉的VQ-VAE二代生成模型,生成出的图像,号称比BigGAN更加高清逼真,而且更具有多样性!
不服气?那先看看这些假照片作品。
浓眉大眼的棕发妹子,与歪果仁大叔:

神似何洁的亚裔面孔:

胡子清晰可见的短发男:

此外,还有各种类型的动物:


在Top-1准确率测试上,VQ-VAE二代比BigGAN成绩多出了16.09分。
DeepMind负责星际项目、也是这项研究的作者之一Oriol Vinyals表示,VQ-VAE二代简直令人惊讶,如此简单的想法竟然能够产生如此好的生成模型!
甚至……连曾经也推出过逼真假脸的英伟达员工:英伟达研究院的高级研究科学家Arash Vahdat,也在研究推特下评价:
令人印象深刻啊!!!
短短几小时,这项研究在推特上收获了500多赞,以及上百次转发。
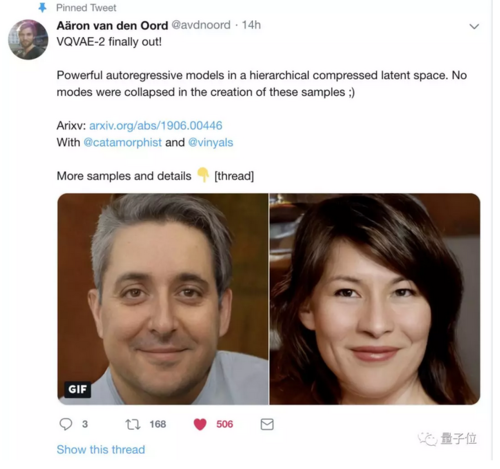
来具体看看效果。
真实效果,好到惊艳
VQ-VAE生成的假照片,可以Hold住多种规格的精确度,在ImageNet上,可以训练出256×256像素的动物:


如果投喂英伟达7万张高清人脸数据集FFHQ(Flickr-Faces-HQ),输出的图像则为1024×1024像素的高清大图,连人脸上的细微毛孔都清晰可见:

这些高清的妹子脸,颜值看起来也不低呢:


VQ-VAE生成出的假照片,比BigGAN的作品多样多了。
与BigGAN相比,VQ-VAE不仅能生成不同物体和动物,还能生成不同视角以及不同姿势的版本。
比如,同样是生成鸵鸟,这是VQ-VAE的作品:

而VQ-VAE,光鸵鸟头就能生成不同姿态,有正脸的、侧对镜头的、45度角抬头仰望天空的、以及不想露脸上镜的:


甚至相对简单没有四肢的金鱼,都能合成这么多形态:

而BigGAN的角度相对来说非常单一:

除了肉眼可见的视觉对比,研究人员还做了一票实验,用多个性能指标证明VQ-VAE二代在多维度上优于BigGAN。
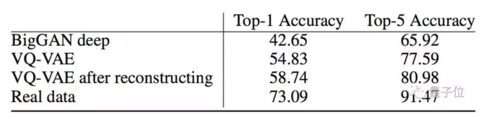
从分类准确率得分(Classification Accuracy Score,CAS)上看,VQ-VAE在Top-1准确率上为58.74分,超出了BigGAN 42.65的成绩16.09分,在Top-5准确率上,VQ-VAE领先了15.06分。
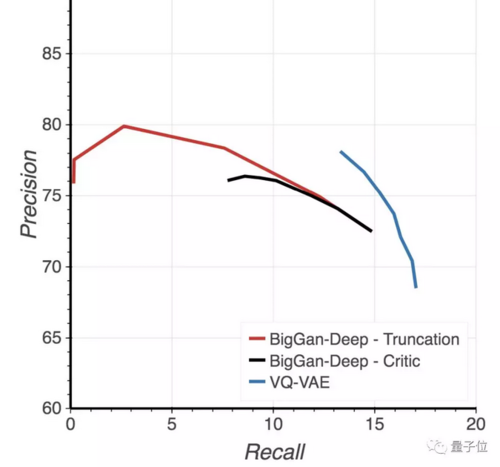
在精确率-召回率指标(Precision - Recall metrics)上,VQ-VAE的精度比BigGAN 稍低,但召回值高出了一大截。
在Inception Scores(IS)上,VQ-VAE没有超越领先前人100多分BigGAN的成绩,但FID值较低。
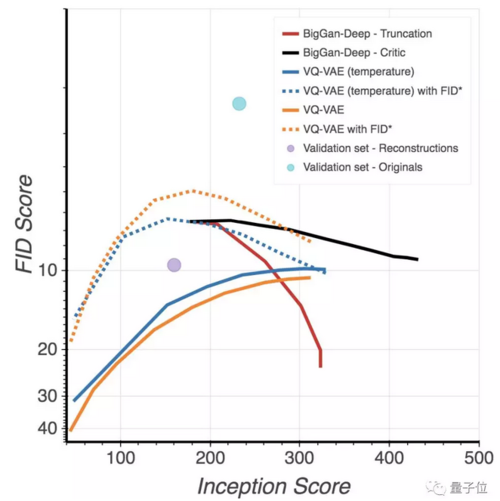
总体来说,VQ-VAE的表现,在多样性和视觉感官上,已经超越了BigGAN,在各项性能指标上表现也还不错。
弥补了GAN的缺点
VQ-VAE-2可以理解成一个通信系统。
其中有编码器,把观察到的信息映射到一组离散的潜变量 (Latent Variables) 上。
还有解码器,把这些离散变量中的信息重构 (Reconstruct) 出来。
系统分成两部分,都是由编码器和解码器构成的。
第一部分
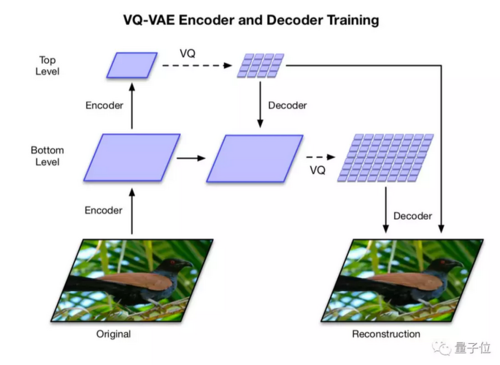
它是一个分层的VQ-VAE,可以把不同尺度的信息分开处理。
比如,输入一张256×256图像,编码器要把它压缩进不同的潜在空间里:
顶层 (Top Level) 要压缩成64×64的潜在映射图,为**全局信息 (比如形状等) 生成潜码;
底层 (Bottom Level) 要压缩成32×32的潜在映射图,为局部信息 (比如纹理等) 生成潜码。
然后,解码器用这两个潜在映射图 (Latent Maps) 中,做出一张与原图同样大小的重构图,其中包含了局部和全局信息。
团队发现,如果不用顶层来调节 (Condition) 底层,顶层就需要编码像素中每一个细节。
所以,他们就让每个层级分别依赖于像素 (Separately Depend on Pixels) :可以鼓励AI在每个映射图中,编码补充信息 (Complementary Information) ,降低重构误差。
而学到分层潜码 (Hierarchical Latent Codes) 之后,该进入下一部分了:
第二部分
在从潜码中学到先验 (Prior) ,生成新图。
这一部分,是二代与一代最大的区别所在:把一代用到的自回归先验 (Autoregressive Priors) 扩展、增强了。
用当前最优秀的PixelRNN模型来为先验建模,这是一个带自注意力机制的自回归模型,能够把先验分布 (Prior Distribution) ,和上一部分学到的边界后验 (Marginal Posterior) 匹配起来。
这样,可以生成比从前相干性更高,保真度也更高的图像。
和第一部分相似:这里也有编码器和解码器,可以进一步压缩图像。
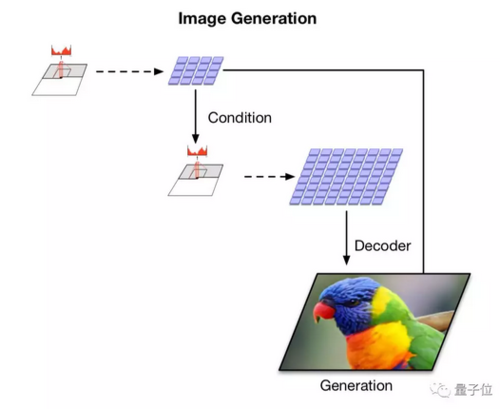
做好之后,从先验里取样,可以生成新的图像:和原图清晰度一致,并且保持了相关性 (Coherence) 。
两个部分合在一起,可以把256×256的图像,压缩200倍来学习;把1024×1024的高清大图,压缩50倍来学习。
团队说这样一来,把图像生成速度提升了一个数量级。
在需要快速编码、快速解码的应用上,这样的方法便有了得天独厚的优势。
同时,还避免了GAN的两个著名缺点:
一是mode collapse,即生成某些图像之后,GAN的生成器和判别器就达成和解,不再继续学习了;二是多样性不足的问题。
作者简介
这项研究的作者共有三位,均来自DeepMind,Ali Razavi和Aäron van den Oord为共同一作,Oriol Vinyals为二作。
Ali Razavi博士毕业于滑铁卢大学,此前在IBM、Algorithmics和Google就职过,2017年加入DeepMind,任职研究工程师。
研究员Aäron van den Oord小哥主要研究生成模型,此前还参与Google Play的音乐推荐项目。

2017年,Aäron参与了哈萨比斯项目组关于Parallel WaveNet的研究,为这篇论文的第一作者。

Oriol Vinyals小哥此前参与了多个明星项目,比如星际项目、比如AlphaStar,还与图灵奖得主Geoffrey Hinton和谷歌大脑负责人Jeff Dean一起合作过,合著论文Distilling the knowledge in a neural network。
对了,最先称赞BigGAN是“史上最佳GAN”的人,也是他~
传送门
论文Generating Diverse High-Fidelity Images with VQ-VAE-2地址:
https://arxiv.org/abs/1906.00446
— 完 —
共同学习,写下你的评论
评论加载中...
作者其他优质文章



