
针对构建的电影购票功能获取相应数据,主要获取:电影信息+影院信息+场次信息,都不难获取,主要是场次信息方面的构造、排布
1. 爬取首页所有电影链接
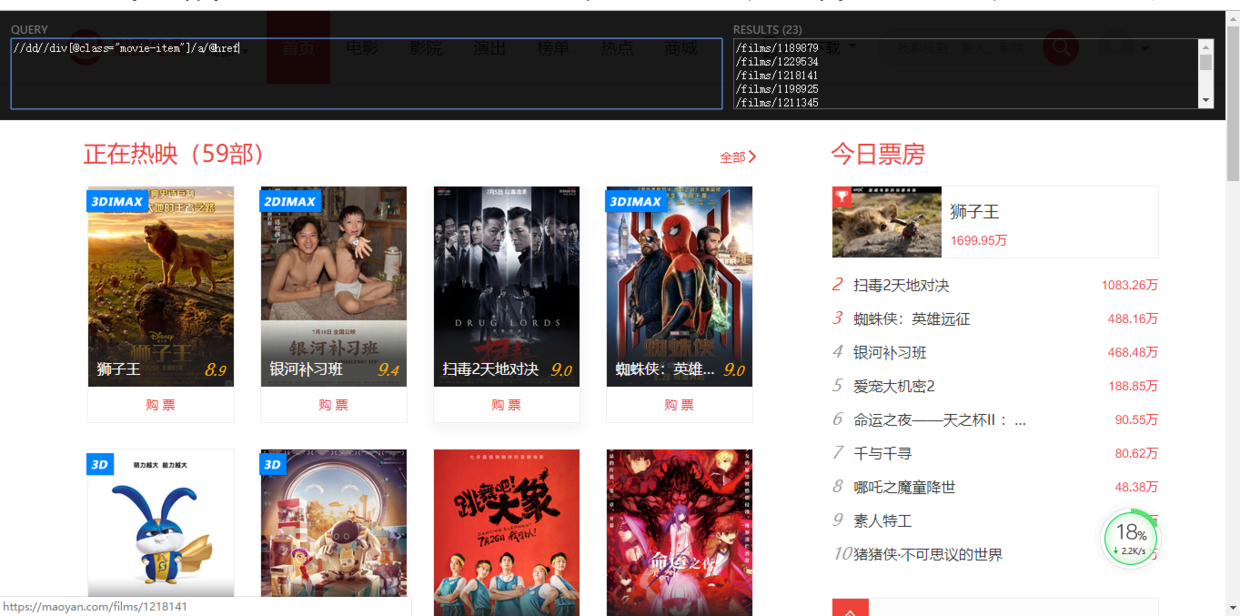
def parse(self, response):
movie_list = response.xpath('//dd//div[@class="movie-item"]/a/@href').extract()
for url in movie_list:
yield scrapy.Request("https://maoyan.com" + url, callback=self.parse_tag)
2. 进入子页面获取电影具体信息

def parse_tag(self, response):
item = MaoyanItem()
item['movie_name'] = response.xpath('//h3[@class="name"]/text()').extract_first()
item['ellipsis'] = response.xpath('//div[@class="ename ellipsis"]/text()').extract()
time_str = ''.join(response.xpath('//li[@class="ellipsis"]//text()').extract())
item['time'] = self.date_reg_exp.findall(time_str)[0]
if response.xpath('//i[@class="imax3d"]'):
item['vision'] = "3DIMAX"
elif response.xpath('//i[@class="m3d"]'):
item['vision'] = "3D"
else:
item['vision'] = ""
yield item
3. 获取影院信息
因为这里需要的数据并不多,就自行选取部分区域爬取即可,想要爬取所有区域或者城市可以根据具体的城市id以及区域唯一标识id进行构造

4. 获取影院详情信息

def parse_tag(self, response):
item = MaoyanItem()
item['movie_name'] = response.xpath('//h3[@class="name"]/text()').extract_first()
item['ellipsis'] = response.xpath('//div[@class="ename ellipsis"]/text()').extract()
time_str = ''.join(response.xpath('//li[@class="ellipsis"]//text()').extract())
item['time'] = self.date_reg_exp.findall(time_str)[0]
item['introduction'] = response.xpath('normalize-space(//span[@class="dra"]/text())').extract_first()
duration = ''.join(response.xpath('//li[@class="ellipsis"][2]//text()').extract())
item['duration'] = re.findall('\d+', duration)[0]
if response.xpath('//i[@class="imax3d"]'):
item['vision'] = "3DIMAX"
elif response.xpath('//i[@class="m3d"]'):
item['vision'] = "3D"
else:
item['vision'] = ""
yield item
5. 获取场次信息
场次信息我用的json文件来保存,因为其中涉及到不同日期不同场次,针对不同电影,信息也是不同的,这是一个比较庞大的数据,我们按照如下形式保存
'''
movie_session = [不同电影的场次数据
{movie_name: ...
result:[每一天的场次数据
{
date: ...
session_result:[当天的场次数据
{},
{}....
]
}
]
}
]:每部电影的数据
'''
去对应影院的详情页面,对电影、日期进行循环,然后抓取到所有的场次列表,写入到文件当中

headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",
"Referer": "https://maoyan.com/xseats/201906020127664?movieId=246061&cinemaId=17372",
"Host": "maoyan.com",
"Upgrade-Insecure-Requests": "1",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3"
}
movie_result = []
def getCinemas(urls):
cinemas = []
for url in urls:
html = etree.HTML(getHtml(url))
cinemas.extend(html.xpath('//div[@class="cinema-info"]/a/@href'))
return cinemas
def getUrls(urls):
url_list = []
cinemas = getCinemas(urls)
for cinema in cinemas:
cinema_url = "http://maoyan.com" + cinema
url_list.append(cinema_url)
return url_list
def getHtml(url):
return requests.get(url, headers=headers).text
#给出当天的xpath对象获取对应日期的场次数据
def getToday(today, time_list, num):
result = []
session_result = []
session_list = today.xpath('.//table/tbody/tr')
# 当天每个场次
for session in session_list:
begin_time = session.xpath('.//span[@class="begin-time"]/text()')[0]
end_time = session.xpath('.//span[@class="end-time"]/text()')[0]
lang = session.xpath('.//span[@class="lang"]/text()')[0]
hall = session.xpath('.//span[@class="hall"]/text()')[0]
session_result.append({
"date": re.findall('\d+', time_list[num])[0] + '-' + re.findall('\d+', time_list[num])[1],
"begin_time": begin_time,
"end_time": end_time,
"lang": lang,
"hall": hall
})
result.append({
"date": re.findall('\d+', time_list[num])[0] + '-' + re.findall('\d+', time_list[num])[1],
"session_result": session_result
})
return result
def parse_tag(html, days):
movie_session = []
movie_name = html.xpath('//h3[@class="movie-name"]/text()')[0]
time_list = html.xpath('//div[@class="show-list active"]//div[@class="show-date"]/span/text()')[1:]
for day in days:
result = getToday(day, time_list)
movie_session.append({
"movie_name": movie_name,
"result": result
})
return movie_session
def test(text):
movies_session = []
result = []
tmp_result = []
html = etree.HTML(text)
cinema_name = html.xpath('//h3[@class="name text-ellipsis"]/text()')[0]
movies_list = html.xpath('//div[contains(@class, "show-list")]')
#每一部电影数据
for movie in movies_list:
tmp_result.append(get_MovieData(movie)[0])
with open('files/' + cinema_name + '.json', 'a+', encoding='utf-8') as f:
f.write(json.dumps(tmp_result, ensure_ascii=False, indent=2))
def get_MovieData(movie):
movie_session = []
result = []
movie_name = movie.xpath('.//h3[@class="movie-name"]/text()')[0]
if movie.xpath('.//span[@class="score sc"]/text()'):
star = movie.xpath('.//span[@class="score sc"]/text()')[0]
else:
star = '暂无评分'
time_list = movie.xpath('.//div[@class="show-date"]/span/text()')[1:]
#所有场次天数
days = movie.xpath('.//div[contains(@class, "plist-container")]')
for day in days:
result.append(getToday(day, time_list, days.index(day)))
# print(movie_result)
movie_session.append({
"movie_name": movie_name,
"star": star,
"result": result
})
return movie_session
def parse(text):
html = etree.HTML(text)
movie_session = []
result = []
session_result = []
list = html.xpath('//div[@class="show-list active"]')
movie_name = html.xpath('//h3[@class="movie-name"]/text()')[0]
star = html.xpath('//span[@class="score sc"]/text()')[0]
time_list = html.xpath('//div[@class="show-list active"]//div[@class="show-date"]/span/text()')[1:]#6月2, 6月3
days = html.xpath('//div[@data-index="0"]//div[contains(@class, "plist-container")]')
for day in days:
print(json.dumps(getToday(day, time_list, days.index(day)), ensure_ascii=False))
if __name__ == '__main__':
urls = [
"https://maoyan.com/cinemas?districtId=3799",
"https://maoyan.com/cinemas?districtId=3798",
"https://maoyan.com/cinemas?areaId=-1&districtId=3802",
]
cinemas = getUrls(urls)
for url in cinemas:
test(requests.get(url, headers=headers).text)

点击查看更多内容
1人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦