
作为一名十好青年,微博也关注了许多互联网&科技类的博主。本着学习的心态日常刷着微博。突然看到一条微博。

点开评论,瞬间惊呆了。

下图可能引起不适,未成年人,请在家长的陪同下观看。
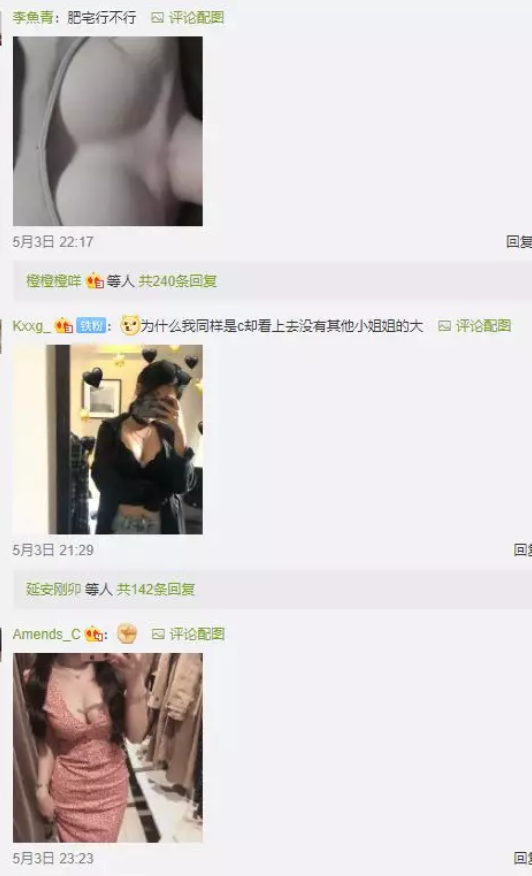
评论1.5W条,一页一页的去翻,身为程序员这显然不是我们的风格。本着学习为主的心态,我决定把他们都保存在我的硬盘里!!!
俗话说,能爬移动端就不要爬PC端,但是在操作手机抓包爬的过程中,遇到了很多坑。一时没有解决。于是转移阵地到PC端微博。
F12打开开发者工具,刷新页面。看到有这样一条Get请求
weibo.com/aj/v6/comment/big,当我们点击加载更多时,又会重新发送一次这样的请求。
请求参数如下: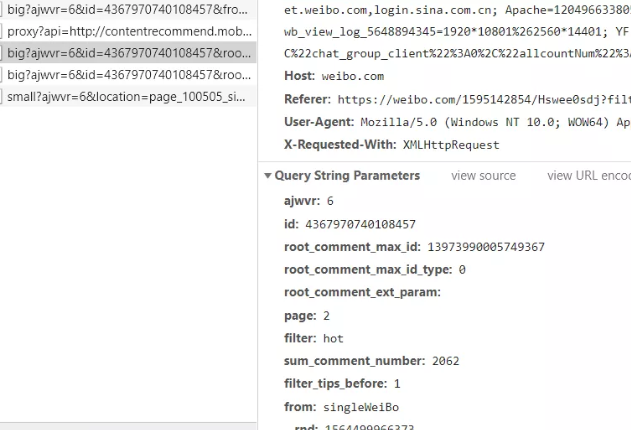
响应为一个json串,微博的内容以html的形式返回。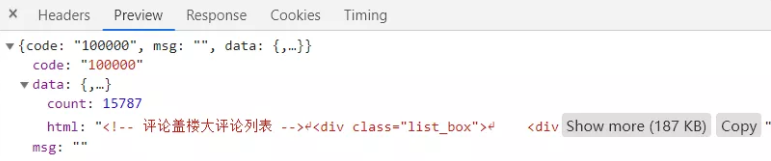
经过对比发现,请求参数 ajwvr为定值6;id为该微博动态的ID,也可以理解为定值;from的值也为定值,_rnd 参数可有可无并不会影响最终的结果。
一开始 root_comment_max_id这个参数让我比较疑惑,第一次请求中并没有这个参数,后面的请求中都必须要传这个参数,否则会影响最后的响应结果。
根据字面意思,大概是父级内容的id,于是我把上一次请求的html数据复制到VSCode,直接Ctrl+F 全局搜索root_comment_max_id。果然不出所料。
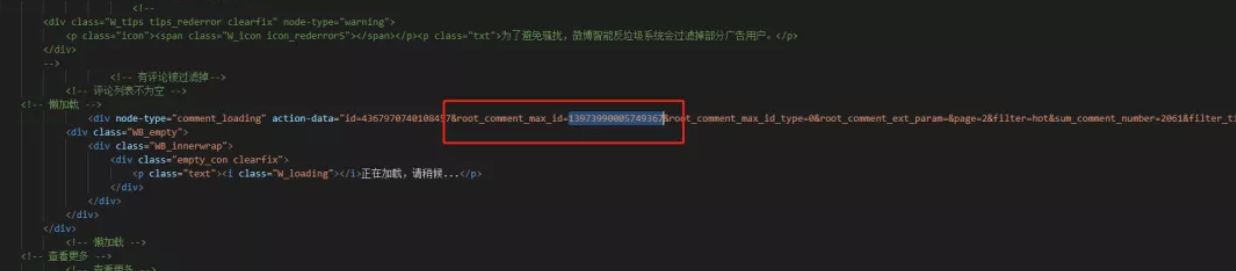
至此,每个参数的含义,基本都清楚了。必传参数总结如下:
-
ajwvr :定值6,必传。
-
id : 该条微博动态的id。
-
from : 定值 singleWeiBo
-
root_comment_max_id:在上一个请求响应的html中提供。也有提供分页的作用
分析相应的html,通过xpath提取出我们想要的字段。

也许大家只对最终的结果感兴趣,那我就不具体讲了。只展示一下关键的代码。
微博爬虫中,做了一定的反爬措施。
-
同一IP不能访问频繁。
-
请求头中需要携带Cookie
headers = {
'Cookie': '你的cookie',
}
# 参数信息
params = {
'ajwvr': 6,
'id': '4367970740108457',
'from': 'singleWeiBo',
'root_comment_max_id':''
}
# 访问url
URL = 'https://weibo.com/aj/v6/comment/big'
resp = requests.get(URL, params=params, headers=headers)
resp = json.loads(resp.text)
if resp['code'] == '100000':
html = resp['data']['html']
print(html)
from lxml import etree
html = etree.HTML(html)
# 获取该页面的root_comment_max_id ,为下一次请求提供参数
max_id_json = html.xpath('//div[@node-type="comment_loading"]/@action-data')[0]
node_params = parse_qs(max_id_json)
# max_id
max_id = node_params['root_comment_max_id'][0]
params['root_comment_max_id'] = max_id
# data = html.xpath('//div[@class="list_ul"]/div[@node-type="root_comment"]/div[@class="list_con"]')
# 获取每一条动态的节点信息
data = html.xpath('//div[@node-type="root_comment"]')
# 遍历每一条东岱
for i in data:
# 评论人昵称
nick_name = i.xpath('.//div[@class="WB_text"]/a/text()')[0]
# 评论内容。
wb_text = i.xpath('.//div[@class="WB_text"][1]/text()')
# 简单的清洗,出去空格和换行符
string = ''.join(wb_text).strip().replace('\n', '')
# 封装了一个方法,将留言信息写入文本
write_comment(string)
# 评论id , 用于获取评论内容
comment_id = i.xpath('./@comment_id')[0]
# 评论的图片地址
pic_url = i.xpath('.//li[@class="WB_pic S_bg2 bigcursor"]/img/@src')
pic_url = 'https:' + pic_url[0] if pic_url else ''
# 封装的下载图片方法
download_pic(pic_url, nick_name)
以上是获取评论信息,但是每条评论下还有很多别的小姐姐的评论(胸照),这我们肯定不能放过。

点击类似放上的按钮,发现依旧有个请求,地址与上面提到的地址一样。区别在于参数的不同。具体大家可以实际操作一下。
通过分析子评论的图的获取方式有所不同,他是通过get请求
weibo.com/aj/photo/popview, 参数可有从子评论响应的html获取。下图标注部分。
通过请求构造出的url,会返回一个一个图片列表,第一个就是我们需要的图。
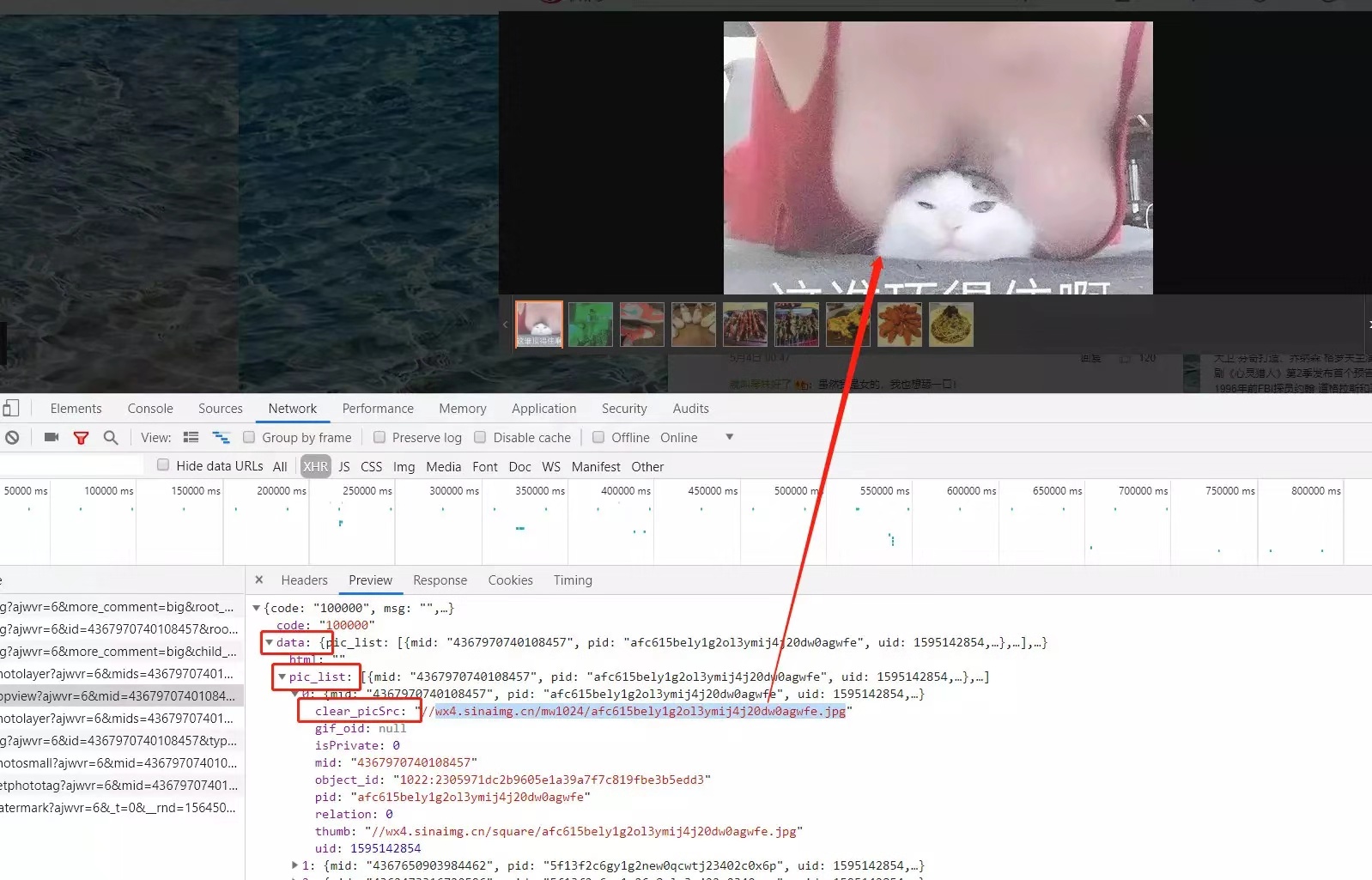
获取子评论方法,代码中只获取了第一页的子评论,因为后面大部分是水文,感兴趣的同学可以去试试,方法跟获取父级留言一样,需要的参数在源码中都可以找到。

def get_child_comment(root_comment_id):
comment_params['root_comment_id'] = root_comment_id
resp = requests.get(URL, params=comment_params, headers=headers)
resp = json.loads(resp.text)
if resp['code'] == '100000':
html = resp['data']['html']
print(html)
from lxml import etree
html = etree.HTML(html)
# 每个子评论的节点
data = html.xpath('//div[@class="WB_text"]')
for i in data:
nick_name = ''.join(i.xpath('./a/text()')).strip().replace('\n', '')
comment = ''.join(i.xpath('./text()')).strip().replace('\n', '')
write_comment(comment)
# 获取图片对应的html节点
pic = i.xpath('.//a[@action-type="widget_photoview"]/@action-data')
pic = pic[0] if pic else ''
if pic:
# 拼接另外两个必要参数
pic = pic + 'ajwvr=6&uid=5648894345'
# 构造出一个完整的图片url
url = 'https://weibo.com/aj/photo/popview?' + pic
resp = requests.get(url, headers=headers)
resp = resp.json()
if resp.get('code') == '100000':
# 从突然url中,第一个就是评论中的图
url = resp['data']['pic_list'][0]['clear_picSrc']
# 下载图片
download_pic(pic_url, nick_name)
好了,知道大家已经迫不及待的想看结果了。部分截图如下。

也可以通过PIL模块生成照片墙。

微博里,大家都在说什么?可以通过词云的方式进行展示
今天下班已经十点了,路上刷微博,突然想尝试爬一下微博评论,时间仓促,代码可能不够严谨。所以各位看官多担待,完整源码。已上传github。
地址:https://github.com/python3xxx/weibo_spider
共同学习,写下你的评论
评论加载中...
作者其他优质文章



